冗长的背景
两年前我在某开发团队做专项的产品安全时弄了个Python代码保护,当时简单搜索了下发现没有成熟的开源和商业方案就自己搞了,第一版总共花了一天时间,老大的要求是防半天,后经反馈这个目标算是达成了,相关分析可见“浅谈Python代码保护”。 当时做完第一版后就转岗到其他部门啦,后续受同事委托又改进了几版(被保护的产品应该没有在外部流传),后面的改进只是深入分析PVM后做的修补,防止利用PVM特性从内存中恢复CodeObject,总体来说整个方案算是比较初级的方案,后续我也没有再关注,只是知道公司购买了某商业方案,该方案在当时是很弱的但是后来频繁更新,于是认为当前它比自己的实现保护更强。 前不久萌萌来找我说之前的方案要被下了,我也推荐用pyarmor。不过还有另一件事,直接违背了我的想当然:
当时时间紧没做benchmark,但是理所当然的认为自己的方法并不会对执行造成多大的性能损耗,就假装5%吧,当听到损耗50%第一反应就是他们测错了,我还反复确认了是否是第一版,因为后续版本为了增强安全性做了很多保护会对性能有更多的影响,但是第一版就很清晰了,而且我认为作为一个IO密集型应用不至于有这么大影响,然而后来我突然想到,我对每条指令进行的替换是动态做的仿射计算,如下:
 这样每次取指令都需要进行判断与计算,特别的这里的乘法指令没有优化,而我再看了每条指令的操作发现大部分指令其实只是简单的栈操作,那么显然这种变换将会造成指令执行时间的加倍,其实优化方式也很简单直接提前做完计算即可,但是这种方案实在没必要再运行了于是还是推荐他们用pyarmor:
这样每次取指令都需要进行判断与计算,特别的这里的乘法指令没有优化,而我再看了每条指令的操作发现大部分指令其实只是简单的栈操作,那么显然这种变换将会造成指令执行时间的加倍,其实优化方式也很简单直接提前做完计算即可,但是这种方案实在没必要再运行了于是还是推荐他们用pyarmor:

再之后,前几天,我正准备下楼放风老大给我发个文件让我解一下,当时问了是新版的就说要花些时间,由于不急就先放一边了:

现在刚好有空,就拿来分析了一下。
文档分析
首先先看它的官方文档,这个作者还是特别好,对里面很多技术细节都有比较详细的描述,但是由于他方案的特性,这些描述只会更有利于逆向:
| 加密模式 | 说明 | 分析 |
|---|---|---|
| 加密模式 | 普通加密模式,会使用某(几)种算法对 | 就是对字节码部分进行了某种可逆的变换 |
| 超级模式 | 字节码做变换,代码块结构会改变 | 代码块结构改变的意思应该是做了执行流的混淆 |
| 终极模式 | 部分函数直接编译 | 可能类似Cython一样,这个过程是不可逆的(可逆向不可恢复) |
| 高级模式 | 对PyCode_Type结构进行修改 | 修改结构那么原始的代码都不能直接使用了,需要在那些地方下钩子去替换成自己的处理逻辑 |
| 虚拟模式 | 核心库虚拟化保护 | 只支持windows意义不大,应该是用了VMProtect之类的方式对动态库加固了,其实通过操纵PVM也可以破解 |
除了加密外,它还支持对每个脚本指定约束,限制被保护的代码运行环境等,约束模式的分析如下:
| 约束模式 | 说明 | 分析 |
|---|---|---|
| 1 | 禁止修改脚本(默认) | 加载时检查代码,要么源码要么字节码,应该是前者,方式可能是正则匹配 |
| 2 | 只允许被主脚本是加密脚本的加密脚本导入或直接运行 | 检查frame链,要么上级为空要么整个链都是被加密了 |
| 3 | 2基础上,约束模块的属性和函数只能被加密脚本访问 | 函数调用时检查frame,属性访问时设置钩子 |
| 4 | 类似3,不限制主脚本是否加密 | 同上 |
| 5 | 4基础上,限制外部函数访问加密函数的全局变量 | 没搞懂意思...,但是这应该是动态的 |
| 100+ | 前5种和100的组合,100是字典约束,将禁止模块的字典访问行为 | 在字典访问上下钩子 |
再看看它加密后的脚本长相如下:
# 普通模式
from pytransform import pyarmor_runtime
pyarmor_runtime()
__pyarmor__(__name__, __file__, b'\x06\x0f...') # 非主脚本只存在该行,参数三为加密后代码
# 超级模式
from pytransform import pyarmor
pyarmor(__name__, __file__, b'\x0a\x02...', 1)
加密后的每个代码块(激活时)表现如下,第一种在入口处跳转到末尾解密代码,第二种入口处解密,末尾处再次加密:
# 非包裹模式
0 JUMP_ABSOLUTE n = 3 + len(bytecode)
3 ...
... 这里是加密后的代码块
...
n LOAD_GLOBAL ? (__armor__)
n+3 CALL_FUNCTION 0
n+6 POP_TOP
n+7 JUMP_ABSOLUTE 0
# 包裹模式
LOAD_GLOBALS N (__armor_enter__) N = co_consts 的长度
CALL_FUNCTION 0
POP_TOP
SETUP_FINALLY X (jump to wrap footer) X = 原来代码块的长度
这里是加密的后的代码块
LOAD_GLOBALS N + 1 (__armor_exit__)
CALL_FUNCTION 0
POP_TOP
END_FINALLY
至此,对它的实现已经有了大致的猜测,那么除了终极模式其他都是可以恢复的,开始干!
逆向分析
我是直接在pyarmor-core里下载它的运行时库,从它的index.json里大致能看出每个文件夹下的pytransform的特性,随便找了个打开,通过搜索PyInit定位关键点发现它是不符合C扩展规范的,应该是用了其他方式开发,直接去它安装后的目录里看__init__.py可知是ctypes,ctypes可以直接获取函数原型,然后导入Python符号开始逆。
PS:遇到大坑了,由于之前编译过python的调试版就直接拿来取符号了,结果调试版的一些结构体会多一些调试辅助域导致不一致,怎么看怎么奇怪...
pytransform是需要证书包的,里面内嵌了产品的密钥信息,这和被加密的脚本对应,因此若要调试还是直接分析产品里的文件好,另外它有反调试其实Linux下反调方式是比较少的,简单看了下Windows下应该是在TLS里做了保护,用ScyllaHide可以绕。 简单看了下逆向难度不大,主要是体力活,因为由上可知它是支持很多中保护方式的,有大量参数控制其行为,另外Python不同版本内部存在区别导致为了兼容不同版本添加了很多判断逻辑,由于一些字符串其实从算法上看已经知道有DES/3DES/AES/RSA/Base64,这里简单分析一点...
解密code_object
先分析pytransform里的init可大致了解其初始化过程,以普通加密模式来看,它外层__pyarmor__(__name__, __file__, b'\x06\x0f...', x)是先判断并解密再用marshal.loads加载模块并执行它:
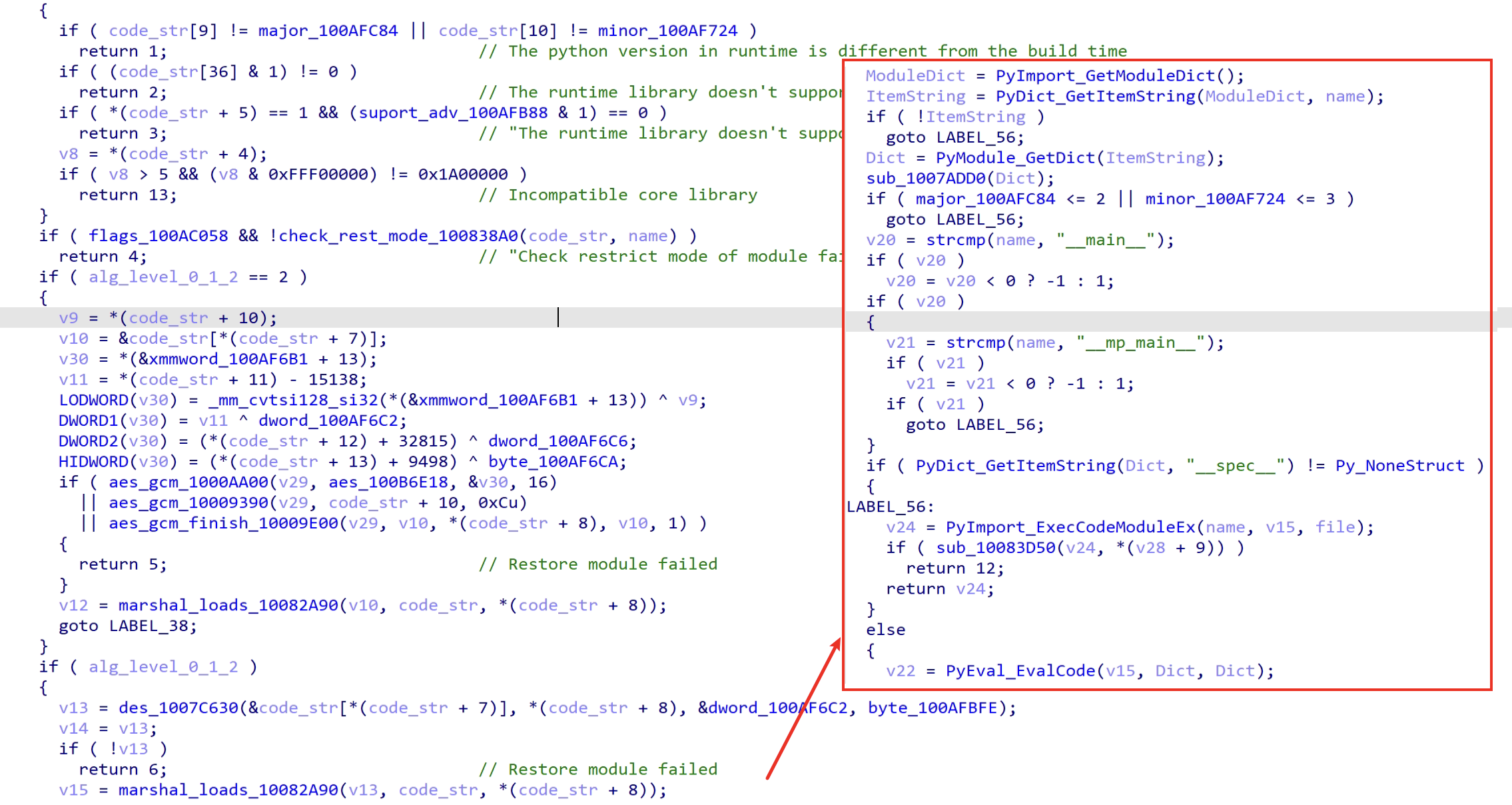
这里的判断由后两个参数决定,如第四个参数代表是否加密,第三个参数结构较复杂,含加密后的字节码与一些其他信息,通过判断这两部分可解密出符合格式的CodeObject,如最后一个参数为0表示未加密,此时可直接恢复:
assert get_int(code, 5) == 0, NotImplemented
start = get_int(code, 7)
size = get_int(code, 8)
assert len(code[start:]) == size, NotImplemented
marshal.loads(code[start:])
而在使用加密时,它会先解密,解密存在多种方式,如使用DES/3DES/AES或自创的加密方式,公开的算法他使用了tomcrypt因此很容易识别,如一般级别的加密它使用CFB模式,64位段,18轮的3DES算法,并使用自创的编码算法,解密方式如下:
# 3DES 解密
des = DES3.new(key, mode=DES3.MODE_CFB, IV=iv, segment_size=64)
org_len = len(code)
pad = 8 - org_len % 8
code = code + b'\x00' * pad
code = des.decrypt(bytes(code))
code = code[:org_len]
# 解码
buf[0] = 0xff & ~buf[0]
if len(buf) <= 2:
return buf
buf[0] ^= buf[-1]
res = buf[0]
for i in range(1, len(buf)):
res ^= buf[i]
buf[i] = res
其中的key和iv是由证书包里获取的,一般情况可通过b'\x60\x70\x00\x0f'定位到嵌入动态库里的密钥与证书文件再分析它们获取key/iv,但也可以直接调试(绕下反调)获取该值,而AES加密,过程如下:
lic_key = unpack('<IIII', bytes.fromhex('6f f5 0d 75 89 eb 72 4e 05 97 1c 72 4c 80 8d 98'))
key = [0, 0, 0, 0]
key[0] = get_int(buf, 10) ^ lic_key[0]
key[1] = (get_int(buf, 11) - 0x3b22) ^ lic_key[1]
key[2] = (get_int(buf, 12) + 0x802f) ^ lic_key[2]
key[3] = (get_int(buf, 13) + 0x251a) ^ lic_key[3]
key = pack('<IIII', *key)
# 处理nonce
nonce = buf[5 * 8:5 * 8 + 12]
# 解密
cipher = AES.new(key, AES.MODE_GCM, nonce=nonce)
plaintext = cipher.decrypt(cipher_text)
其他算法类似不再赘述。
解密co_code
上面解密后的codeobject其实可以看到常量等数据,也可以用marshal.loads加载但是它里面的指令部分还是被加密的,无法用uncompile反编译,上面已经提到它支持两种包裹模式对代码进行解密处理,一种使用__armor__方法解密,一种使用__armor__enter和__armor_exit__实现运行完后再加密,实际使用哪种可通过co_names来识别,如:
if '__armor__' in code_object.co_names:
code_str = decrypt_armor(flag, code_str)
elif '__armor_enter__' in code_object.co_names:
code_str = decrypt_armor_enter(flag, code_str)
else:
... # 未加密或识别不出来
定位到对应的函数进行分析即可,这里面它使用co_flags去判断使用哪种算法解密,如0x80000000的依然是3DES算法,而0x40000000使用了自定义的算法:
for i in range(12, len(code) - 16):
code[i] ^= key[(i - 12) % 24]
return code_str
注意这里面的一些数字是根据具体的python版本和加密算法来确定的,如code[12:-16]这里的12和-16就是因为使用了弱算法,12表示起始处armor_enter指令片段长度为12,而16表示末尾处armor_exit指令片段长度为16,这在不同版本中可能不一致,另外这里面还可能嵌入IV等信息导致这些值发生变化,需要具体分析。而AES的算法,可能如下:
lic_key = unpack('<IIII', lic_key)
key = [0, 0, 0, 0]
key[0] = get_int(iv, 0) ^ lic_key[0]
key[1] = (get_int(iv, 1) - 0xF275) ^ lic_key[1]
key[2] = (get_int(iv, 2) + 0xB0B0) ^ lic_key[2]
key[3] = (get_int(iv, 3) + 0xCD59) ^ lic_key[3]
key = pack('<IIII', *key)
# 它用的计数器是大端序,因此需要自定义
iv = unpack('<QQ', bytes(iv))
iv = (iv[1] << 64) | iv[0]
counter = Counter.new(128, initial_value=iv, little_endian=True)
aes = AES.new(key, mode=AES.MODE_CTR, counter=counter)
# aes = AES.new(key, mode=AES.MODE_CTR, initial_value=iv, nonce=b'')
code = aes.decrypt(buf)
通过这两步的分析就可以解密所有能解密的代码了,只是作者可能还会加新算法啥的,这里的算法也没分析完,总的来说就是体力活,遇到一个分析一个吧...
反编译
像打比赛只有单个文件直接看汇编也可以,但生产环境不现实,需要把它们反编译成源码,直接用uncompyle6即可,但是这需要一些额外的步骤,uncompile的算法比较死板,不符合模板就会报错,因此需要正规化,如调用__armor__enter的头部代码是不需要的需要删除,尾部调用__armor__exit的同理,后者直接去掉即可,而去首会导致指令前移,因此需修复绝对跳转的参数:
opcode = _Py_OPCODE(codestr[i]);
switch (opcode) {
case JUMP_ABSOLUTE:
case CONTINUE_LOOP:
case POP_JUMP_IF_FALSE:
case POP_JUMP_IF_TRUE:
case JUMP_IF_FALSE_OR_POP:
case JUMP_IF_TRUE_OR_POP:
j -= offset; // 识别到绝对跳转时,参数减去前移的数值
break;
// ...
这里需要注意由于python字节码长度为1或3或2,无法表示过大的参数,因此它使用EXTENDED_ARG指令写扩展参数,在处理参数时必须考虑这种情况。
注:讲道理不去除那些干扰也该能反编译的,如[pycdc就没有该限制。
另一个可能的问题是3.6引入了注解,为此又引入了两条新指令SETUP_ANNOTATION和STORE_ANNOTATION,后者后来被删除了,但是反编译这玩意儿却容易出错,其中pycdc不支持它,而uncompyle6从3.3.4版本其实就支持该指令,但是我遇到这个错误了:
Parse error at or near `STORE_ANNOTATION' instruction at offset 22
或许后来删掉该功能了?没仔细看是啥原因,我用了粗暴的方法,直接把那条指令替换掉:
for i in range(0, len(code_str), 2):
if code_str[i] == STORE_ANNOTATION:
code_str[i] = POP_TOP
0606补充:
使用这种方法替换后,再次运行会出错,寻问Josted大哥,他告诉我注解并不只是检查工具会使用,一些数据类也会使用,此时我的粗暴做法存在问题:
由于暂时不影响阅读,先就这样吧,之后有时间再看看uncompyle为啥会出错,改一下它。
取巧方式破解
由于懒得分析,其实可以直接用钩子去解以加密为原理的所有算法,思路如下:
- 在
init_runtime的约束检查处打patch绕过检查 - 在
pyarmor的约束检查处打patch绕过检查 - 执行
__pyarmor__获取解密了外层的对象 :在marshal_loads处获取解密后的内容,并且禁止执行它,从外层获取文件名,将其保存 - 在
__armor_enter__或__armor__的约束检查处打path绕过检查
先说明下,这种方式调用会违反它的约束检查,因此需要先bypass检查,当前有5个检查点,可通过改标志位来绕过,也可用frida直接hook返回值,之后直接用frida在marshal_loads_10082A90处下钩子就可以把外层解密的数据dump下来:
function dumpPyArmor() {
let pyarmorImportAddr = pytransformBase.add(0x1200000 - pytransformImageBase)
Interceptor.attach(pyarmorImportAddr,
{
onEnter: function (args) {
// 先获取文件名
let fileName = args[3].readCString()
let path = "/dumps/" + fileName
// 再添加拦截器
let marshalLoadsRVA = 0x68742540 - pytransformImageBase
let marshalLoadsAddr = pytransformBase.add(marshalLoadsRVA);
console.log(`marshalLoadsAddr ${marshalLoadsAddr}`)
Interceptor.attach(marshalLoadsAddr, { // dump文件,这里拿到的也是codeobject
onEnter: function (args) {
let bufAddr = this.context["eax"];
let wantRead = this.context["edx"].toUInt32();
pycBuf = ptr(bufAddr).readByteArray(wantRead)
let buf = concatArrayBuffers(pycHeader, pycBuf)
writeFile(path, buf)
},
onLeave: function (retVal) {
// 防止被执行,这里修改它最外层的代码对象为直接返回
let codeObject = ptr(retVal)
if (codeObject == ptr(0)) {
return
}
let coCodeAddr = codeObject.add(0x20).readPointer()
coCodeAddr.add(0x10).writeByteArray([0x64, 0x00, 0x53, 0x00]) // 不让它执行 load 0 ret0
}})}})}
通过这种方法,dump后可见之后模块里的代码被__armor_enter__和__armor_exit__包裹了:
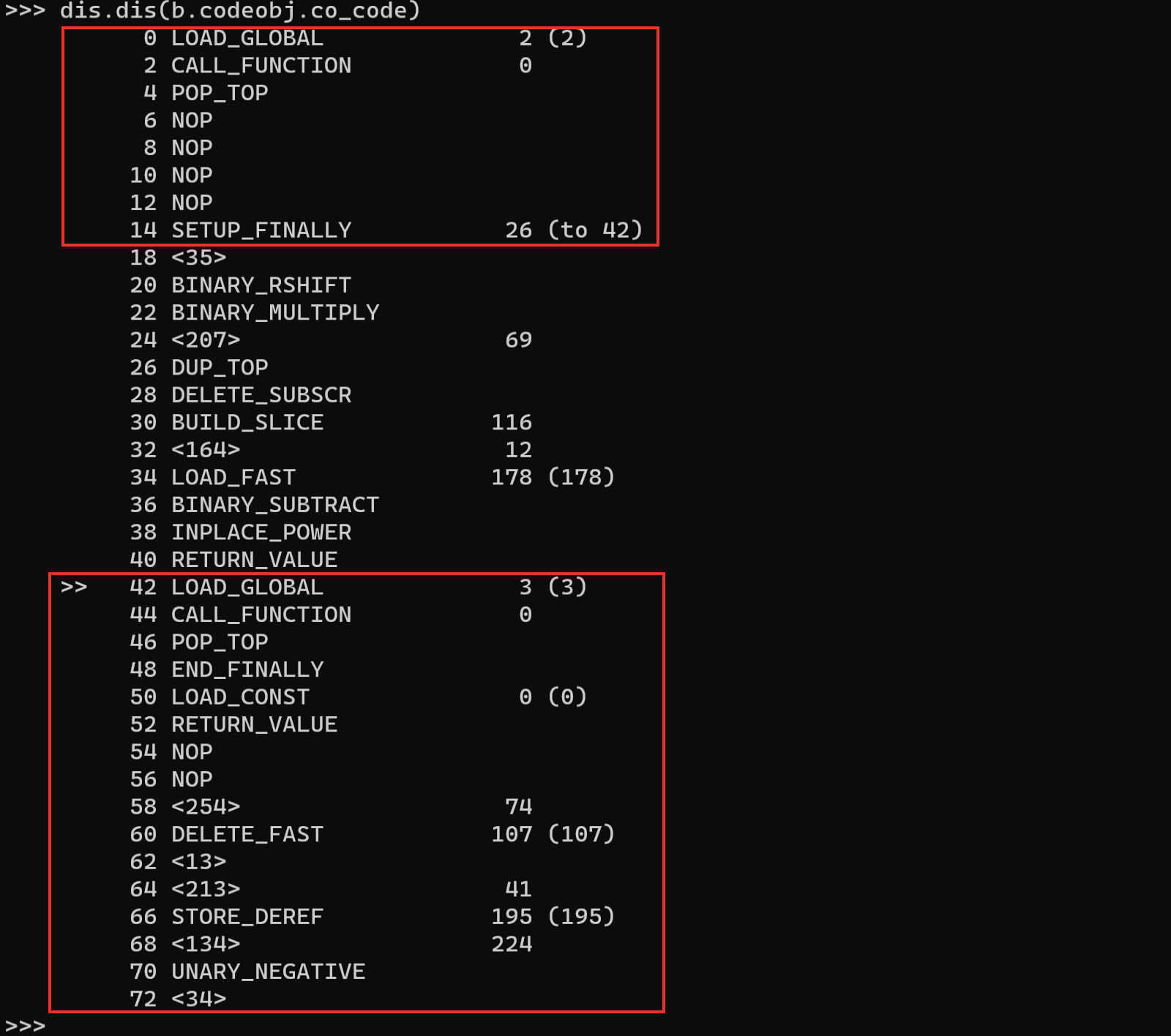
于是直接运行该代码块,在__armor_enter__的结束下钩子:
// 这里处理__armor_enter__的操作
function hookCrypt() {
let cryptAddr = pytransformBase.add(0x6874ABC0 - pytransformImageBase)
Interceptor.attach(cryptAddr, {
onEnter: function (args) {
let is_encrypt = args[0].toUInt32() == 1;
console.log(`is encrypt ${is_encrypt}`)
this.is_encrypt = is_encrypt
let codeAddr = ptr(this.context["edx"]);
let coCodeVal = getCodeBytes(codeAddr)
this.codeAddr = codeAddr
this.cipherText = coCodeVal
console.log(`flags :0x${codeAddr.add(0x18).readU32().toString(16)}`)
},
onLeave: function (retval) {
if (this.is_encrypt) return
console.log(`=====> 开始解密 <============`)
console.log(`解密前 :0x${hexdump(this.cipherText)}`)
patch(this.codeAddr)
let plainText = getCodeBytes(this.codeAddr)
console.log(`解密后:${hexdump(plainText)}`)
replaceArraryBufferAll(pycBuf, this.cipherText, plainText)
console.log(`=============================================`)
}
})
}
就能得到解密后的代码:
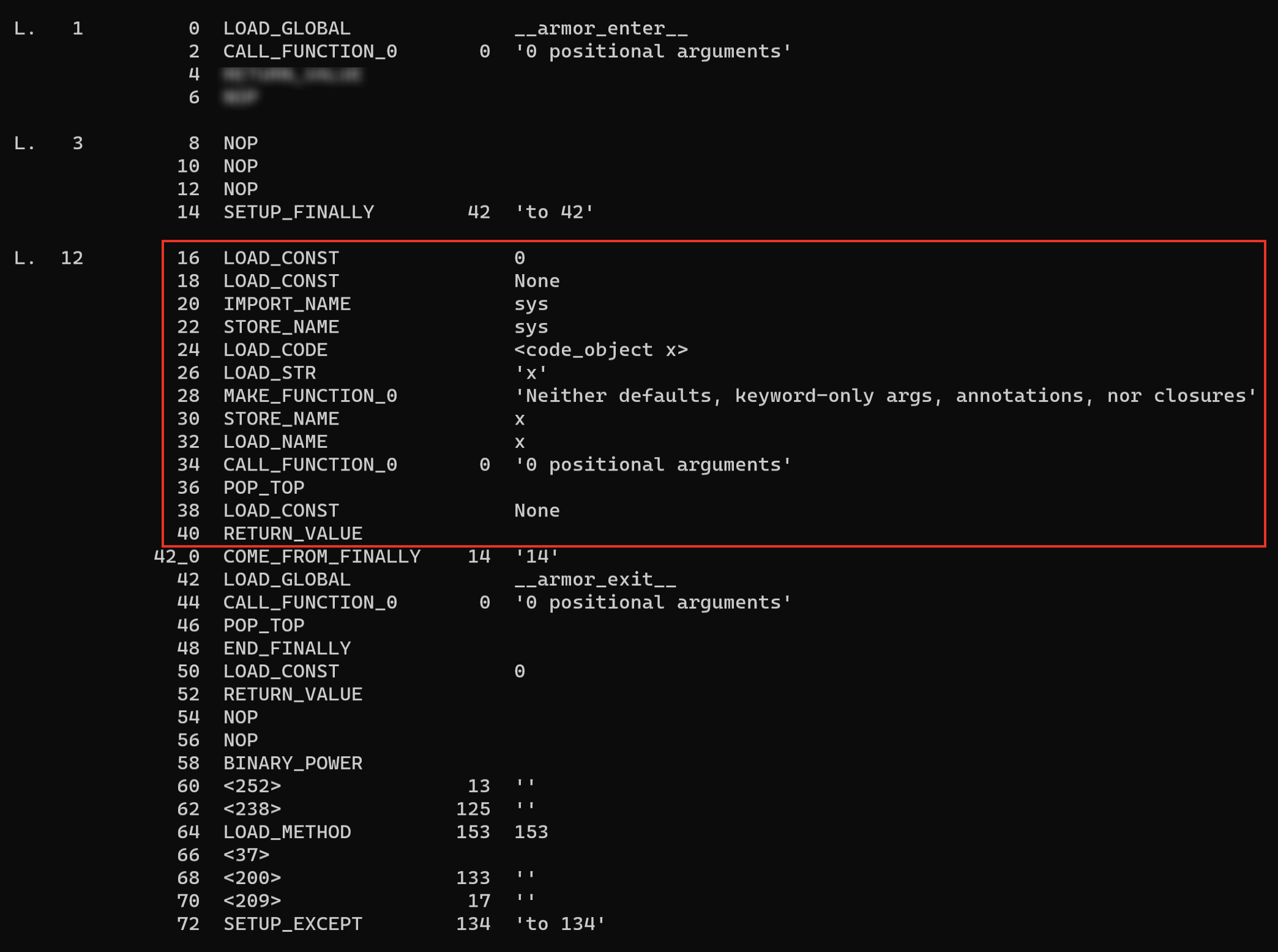
有了如上的代码,再按照上文提到的方式对其进行修复,去掉首位多余的部分就可以反编译了。但是这有个副作用,就是原本的代码也会运行,对此的修复方式是修补__armor_enter__之后的指令,令其直接返回。至于如何触发所有的代码块,方式是直接递归遍历所有的co并使用exec去执行它:
def triger_enter_code(code_object):
exec(code_object, {}, {})
# 注意这里当存在参数时,需要构造个跳板函数才能成功调用,参数个数通过co属性获取
'''import marshal
co=marshal.loads(bytes.fromhex(a))
s="""def a(x,y,z):
...
a.__code__=co
a(1,2,3)
"""
eval(s)
'''
code_consts = list(code_object.co_consts)
for i, const in enumerate(code_consts):
if isinstance(const, CodeType):
triger_enter_code(const)
如上,通过frida下钩子可以不分析算法,但是缺点就是对每个动态库需要分析hook点,反正就各有优劣吧...
短小的尾巴
以后自己没弄过的还是别瞎推荐了...
