已有的方案啥问题?
一. 编译为pyc或打包为exe
.pyc文件为python字节码缓存文件,其结构如下:
struct _pyc{
char magic[4], // 魔数,表明该pyc所对应的版本号
u32 flag, // 表示该pyc是否使用hash判断与其对应py文件一致性
union{
u32 hash, // 用以和py文件做对应,hash
u32 timestamp // 用以和py文件做对应,时间戳
}ht,
u32 size,
PyCodeObject codeobj
}
其中最关键的是最后的PyCodeObject,在python中一个模块,类,函数或方法会被编译为一个单独的PyCodeObject,其定义如下:
typedef struct {
PyObject_HEAD
int co_argcount; /* #arguments, except *args */
int co_kwonlyargcount; /* #keyword only arguments */
int co_nlocals; /* #local variables */
int co_stacksize; /* #entries needed for evaluation stack */
int co_flags; /* CO_..., see below */
int co_firstlineno; /* first source line number */
PyObject *co_code; /* instruction opcodes */
PyObject *co_consts; /* list (该块所定义的所有常量,例如类,) */
PyObject *co_names; /* list of strings (names used) */
PyObject *co_varnames; /* tuple of strings (local variable names) */
PyObject *co_freevars; /* tuple of strings (free variable names) */
PyObject *co_cellvars; /* tuple of strings (cell variable names) */
Py_ssize_t *co_cell2arg; /* Maps cell vars which are arguments. */
PyObject *co_filename; /* unicode (where it was loaded from) */
PyObject *co_name; /* unicode (name, for reference) */
PyObject *co_lnotab; /* string (encoding addr<->lineno mapping) See
Objects/lnotab_notes.txt for details. */
void *co_zombieframe; /* for optimization only (see frameobject.c) */
PyObject *co_weakreflist; /* to support weakrefs to code objects */
void *co_extra;
} PyCodeObject;
其中含有源代码出普通注释外的所有内容,一级字节码与源码的对应关系,有大量成熟的工具可以实现反编译,如uncompile。类似的,打包为可执行文件,它内部数据和代码是分开的,以pyinstaller为例,可执行文件的代码只是为了对环境进行初始化并使用子进程运行python,根据其官网描述,.py文件会被编译为.pyc文件,之后去掉头部(因为头部是为了指明版本信息,frozen后不需要了)后使用toc结构放置在文件尾部,其格式如下:
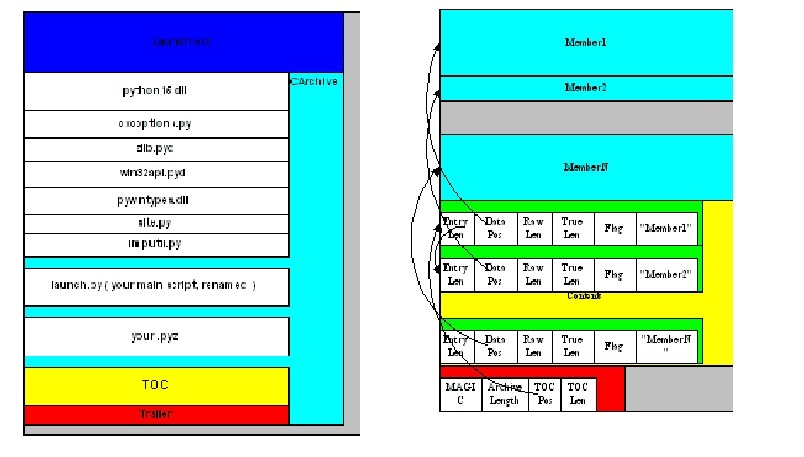
左图为onefile形式的可执行文件,其尾部细节如右所示,因此通过解析此结构,就能提取出所有无头pyc文件,再添加头部后由uncompyle6还原代码,提取代码已有实现(或pydeinstaller/pydecipher),其部分代码如下,它通过判断文件结尾24或84字节是否以'MEI\014\013\012\013\016'来判断是否为pyinstaller打包的文件,判断其版本,之后再解析其toc并提取文件:
PYINST20_COOKIE_SIZE = 24 # For pyinstaller 2.0
PYINST21_COOKIE_SIZE = 24 + 64 # For pyinstaller 2.1+
MAGIC = b'MEI\014\013\012\013\016' # Magic number which identifies pyinstaller
def checkFile(self):
print('[+] Processing {0}'.format(self.filePath))
# Check if it is a 2.0 archive
self.fPtr.seek(self.fileSize - self.PYINST20_COOKIE_SIZE, os.SEEK_SET)
magicFromFile = self.fPtr.read(len(self.MAGIC))
if magicFromFile == self.MAGIC:
self.pyinstVer = 20 # pyinstaller 2.0
print('[+] Pyinstaller version: 2.0')
return True
# Check for pyinstaller 2.1+ before bailing out
self.fPtr.seek(self.fileSize - self.PYINST21_COOKIE_SIZE, os.SEEK_SET)
magicFromFile = self.fPtr.read(len(self.MAGIC))
if magicFromFile == self.MAGIC:
print('[+] Pyinstaller version: 2.1+')
self.pyinstVer = 21 # pyinstaller 2.1+
return True
print('[!] Error : Unsupported pyinstaller version or not a pyinstaller archive')
return False
...........
其实这类工具的原理就是做importhook(下面会提到),并将py代码及其依赖打包到可执行文件里,运行时再解压,基本不存在保护,不过如果自定义一下打包方式,也可以使工具无法直接提取文件,当然意义不大。
二. python级的名称混淆
即对里面的变量名,函数名类名等进行混淆,如下左图为原始的代码,右图为使用pyminifier混淆后的代码,显然混淆后的代码更加难以阅读,对右侧的代码需要通过交叉引用逐行分析重命名:
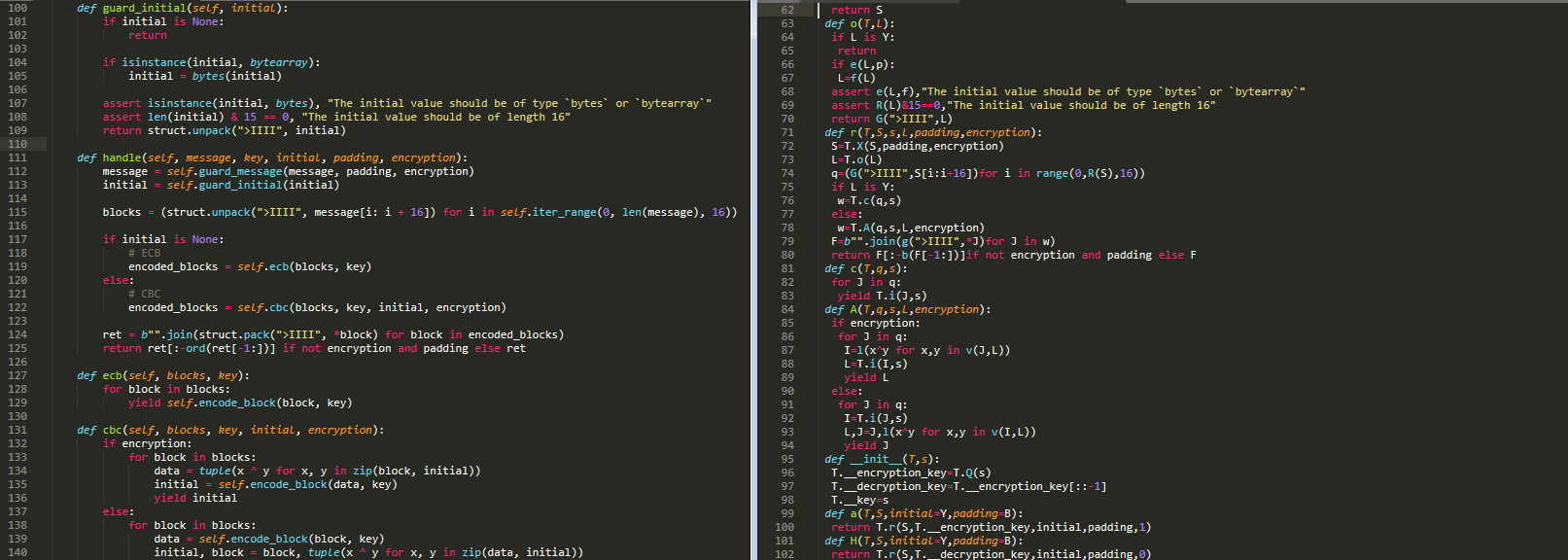 它们一般会有如下操作:
它们一般会有如下操作:
- 删除注释与文档注释
- 字符串常量变换
- 内建函数与导入混淆
- 类,方法,变量名混淆
这种变换网上的实现有两种,一种是正则表达式进行匹配替换,另一类是使用词法分析后做替换,由于python动态特性以及编码时各种hack操作,难以保证在未运行时所有符号替换无误,例如跨文件时,可以使用__all__申明要导出的符号,但是用户只要指定名称仍然可以导入它的任意符号,对一个类,使用__methodname来说明一个方法是私有的但是依然可以被外界调用,以及一些其他的猴子补丁,inspect等动态操作,使其难以在词法甚至语法分析上保证混淆无误,一般我们只能说在大概率下函数或方法内部的局部变量名混淆是安全的,但是明显这种级别的混淆实在太弱。
三. python级的流程混淆,如执行流扁平化
PyCodeObject里面的co_code最终都会在_PyEval_EvalFrameDefault中被执行,该函数实现了一个栈机,使用next_instr模拟PC寄存器顺序读取co_code里指令并执行,整体流程如下:
while(not_eof(PC)){
param=instr_param(PC); // 获取当前PC指向指令的参数
ins=instr_ins(PC); // 获取当前PC指向指令的操作数
switch PC:{
case POP:...;break;
case PUSH:...;break;
case CALL:...;break;
....
}
PC=next_instr(PC);
}
正常情况下,每次循环next_instr将会自增指令长度(在python3.7中统一为2,在python2.7中根据操作码是否存在参数增长1或3),但当遇到跳转指令时,C层面将通过如下两种宏所定义的操作改变next_instr的值:
#define JUMPTO(x) (next_instr = first_instr + (x) / sizeof(_Py_CODEUNIT)) //绝对跳转
#define JUMPBY(x) (next_instr += (x) / sizeof(_Py_CODEUNIT)) // 相对跳转
修改该值后,当C层面进入下一次循环时将会读取next_instr,于是实现了python层面的跳转。类似C的执行流混淆,我们可以在co_code中插入大量跳转指令,只要在C层面它的最终执行顺序没有改变代码逻辑就不会有任何差别,但是这些代码将扰乱分析人员的思路,或使自动化工具无法使用。需要注意,插入代码后,原指令的跳转偏移可能会改变,需要对其进行重定位,经统计有如下指令的参数代表跳转,这些指令的操作数需要根据插入的指令做修正:
FOR_ITER,JUMP_FORWARD,JUMP_IF_FALSE_OR_POP,JUMP_IF_TRUE_OR_POP,POP_JUMP_IF_FALSE,POP_JUMP_IF_TRUE,JUMP_ABSOLUTE,CONTINUE_LOOP,SETUP_LOOP,SETUP_EXCEPT,SETUP_FINALLY,SETUP_WITH,SETUP_ASYNC_WITH,
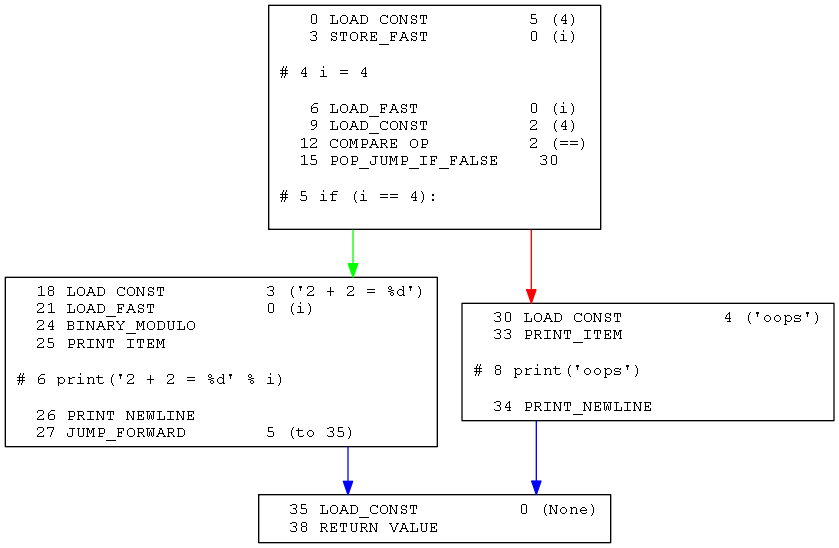
另外,PyCodeObject中还有一个与指令相关的域co_lnotab,它表示指令与源码之间的对应关系,它也需要被修正否则将影响排错(不在意可以略)。不过类似C的执行流分析,但是python显然更简单,只要画出其控制流图,以基本块为单位,去掉无用的跳转就能换原这种混淆:
四. python级的代码加密
加密是不容易出现异常的保护方式,流程是对外发布的文件是加密的,在python解释器加载文件后在内存中解密并运行,明文不写回文件,这里的被加密对象可以是.py,.pyc等任何能被python解释器使用的文件,对.so等文件,由于它是由dl加载的,需要再特殊处理。此处只以.pyc文件为例(因为很多人能意外的神奇的导入加密后.py文件并得到明文.pyc文件),对其加密方式有:
- 全文件加密
- 加密关键结构,如常量表,名称表,字节码对象
根据加密位置有如下解密点设置方式:
1.import hook(python)
首先介绍下python的import机制,对于一个单独的文件其导入流程(无缓存)如下:
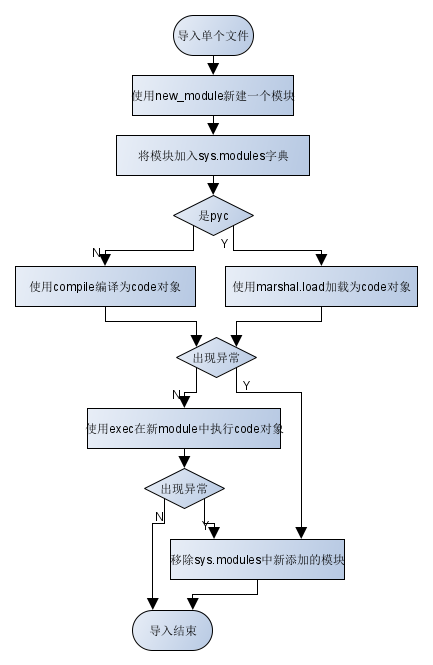
主要导入逻辑存在于lib/importlib目录下,并且在编译时,它们将会作为冻结模块被编译为PyObjectCode后嵌入二进制文件,并在解释器初始化时反序列化为code对象。
这里简单的介绍下Python提供的导入Hook机制,它将importer分为finder和loader,前者用于查找哪个loader可加载模块,后者对模块进行一些设置,这涉及sys下的几个列表:
- modules:缓存已加载的模块,其他空间想导入模块先尝试从这里查找缓存,不存在再加载并存入缓存。
- path:模块加载的搜索路径,它会被path based finder(基于路径的查找器,它属于元路径查找器)使用,这个finder通常位于meta_path的末尾,它调用path entry finder(路径条目查找器)
- meta_path:里面存放元路径查找器对象,如frozen等可以在这里实现。
- path_hooks:里面存放路径条目查找器,如通用的查找器和Zip的查找器,还可自己实现如网络位置的查找器等。
在导入时先遍历meta_path,若前面的元路径查找器都无法加载则由最后的基于路径的查找器尝试加载,它会遍历path_hooks查找是否有能加载的,都不行就表示无法加载,详见import与importlib官方文档。由于它是python编写的,因此对它进行修改或者hook是比较容易的,事实上cpython已经为用户提供了hook接口可以轻松实现自己的导入器,demo如下:
class CryptPathFinder(importlib.abc.PathEntryFinder):
def find_loader(self, fullname):
path = fullname.replace('.','/')
try:
with open(path, 'rb') as f:
if f.read(4) == CRYPT_MAGIC: # 通过魔数判断是否应该使用自定义的loader加载
return CryptModuleLoader()
except:
return None
class CryptModuleLoader(importlib.abc.SourceLoader):
def load_module(self, fullname):
code = self.get_code(fullname)
mod = sys.modules.setdefault(fullname, imp.new_module(fullname))
mod.__file__ = self.get_filename(fullname)
mod.__loader__ = self
mod.__package__ = fullname.rpartion('.')[0]
exec(code, mod.__dict__)
def get_code(self, fullname):
code = self.get_source(fullname)
code = decrypt_pyc(code) # 解密函数
return marshal.loads(code[16:])
sys.path_hooks.insert(0, CryptPathFinder())
在执行完该代码后,就能正常使用import导入被加密的代码了,当然这部分代码特征明显很容易被定位到并获取解密算法。
注:在import上,还支持site机制,它默认会在四个目录(两个前缀与两个后缀组合)里加载包,并搜索里面的以
pth为扩展名的文件,将里面的内容作为导入路径添加到sys.path里,另外它还支持在里面写python语句进行更灵活的导入,但是每次只能单行,用户可使用site.addsitedir方法将其他路径设置为site目录,它会将目录添加到sys.path里并搜索其下的pth文件,也可以设置PYTHONPATH环境变量修改site搜索目录。
2.import hook(c)
它可能涉及如下四个函数:
imp.new_module(name) // PyModule_NewObject
marshal.loads(bytes) //PyMarshal_ReadLastObjectFromFile
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1) // PyAST_CompileObject
exec(object[, globals[, locals]]) // PyEval_EvalCode
因此只要hook这些函数就能运行加密的代码,并在hook的代码处解密,尽管这比上一种方式更底层,但它们依然是比较上层的函数,可以在python内部通过更底层的接口获取解密后的数据。
3. try-hook
以pyarmor为例,类似于php中前几代代码保护方案,它也是对python源码进行编译与加密,并为解释器提供一个可加载的解密模块,加密的python代码会先导入解密模块,并在真实代码执行前进行解密操作,这种方案相比前两种一方面可以更好的保护加密算法,因为这个解密模块可以进行各种保护,另一方面又不需要修改解释器,更容易使用。

但是它拥有和php前几代保护方案同样的弱点---不用分析算法,只要修改python解释器,令其解密完毕再dump数据即可获取codeobject。
五、C语言级的代码编译
如使用cython将python代码转换为c代码或者关键代码直接使用c实现。这比单纯的python安全性更好但是从二进制逆向角度看它是无任何保护的而且由于python动态性符号会被保留,算是较简单的类型了。要使用cython需要先安装vc编译器与cython库,安装后直接可直接将py文件编译为二进制形式的动态库,如:
# 小文件可直接使用cythonize编译:
cythonize.exe -b test.py
# 若文件过多最好使用distutils工具组织为setup.py文件
from distutils.core import setup
from Cython.Build import cythonize
setup(
name = 'test',
ext_modules = cythonize("test.py")
)
可以看到编译后的文件变大了很多:
ls -lh
-rw-r--r-- 1 xxxxxxx 197121 108K 七月 4 14:56 test.c
-rw-r--r-- 1 xxxxxxx 197121 157 六月 15 18:35 test.py
而编译出的二进制文件尽管会保留符号,但是分析实现逻辑已经更加复杂了:
 当然为了增大分析难度还能先做python的混淆再编译为动态库。不过混淆与编译为动态库都可能遇到兼容性问题,编译为动态库后只能在对应的平台运行,因此这类保护只适合不常变动的少量代码,需要对相应代码做调试与兼容性修改,另外像inspect这种模块也会失效。
当然为了增大分析难度还能先做python的混淆再编译为动态库。不过混淆与编译为动态库都可能遇到兼容性问题,编译为动态库后只能在对应的平台运行,因此这类保护只适合不常变动的少量代码,需要对相应代码做调试与兼容性修改,另外像inspect这种模块也会失效。
注,有些修改会把入口去掉,可使用pyrasite向运行中的python进程注入代码,它的原理就是gdb里直接调用
PyRun_SimpleString方法,类似的dump-pyc-with-gdb也是在PyEval_EvalCode处调用PyMarshal_WriteObjectToFile把内存中的codeobject给dump下来。
那咋改解释器捏?
总述
通过修改python解释器,对加密pyc进行执行,将保护技术从python级别转化为c级别,将易读的python字节码转换为晦涩的机器码。其中尽管pyc的转换是可逆的,但是由于直接解释执行bytecode的c部分不可逆变换导致整个过程仍然是不可逆的过程,该方式存在如下特点:
- 兼容未保护的的代码:本方案中会自动识别代码是否被保护并做相应的正确的操作。
- 从原理上避免非预期运行时错误:通过分析cpython源码,深入分析了python虚拟机的执行逻辑,使该方案能准确预期在哪些情况下会出现问题,防止非预期问题。
- 将对python源码保护最终转移为对C源码的保护,攻击者最终必须要逆向二进制文件才能破解源码。
相比于市面上保护最强的pyarmor,它们整体保护思路一致,但是这里是将解密代码嵌入解释器内部,解释器作为一个单独的二进制文件而不会将解密后数据暴露给外部接口,也就可以很方便的对解释器整体加强壳防止解释器被逆向,从而保护代码安全,而pyarmor由于是外部扩展模块,它一定要将解密后的代码交由原始解释器,因此攻击者可以直接使用一个恶意的解释器获取源码,破解难度更低。
这里演示的方法会从指令,代码块,文件三级对代码做做变换处理,并删除一些不影响运行的调试接口。这里首先可以对解释器做一些额外的初始化,有两种选择,若是解释器不会被内嵌可以在python这个工程里做操作,如:
+++ b/Modules/main.c
@@ -71,6 +71,205 @@ static int orig_argc = 0;
#define PROGRAM_OPTS BASE_OPTS
+/***********************************/
+ SomeInitCode(void*);
+ SomeDecryptCode(void* inData, void* outData, unsigned int size);
+/****************************************/
+
@@ -3027,6 +3226,8 @@ pymain_init(_PyMain *pymain)
_PyCoreConfig_GetGlobalConfig(config);
int res = pymain_cmdline(pymain, config);
+
+ SomeInitCode(args);
if (res < 0) {
_Py_FatalInitError(pymain->err);
}
若要提供动态库给其他程序调用还需要在这里初始化,或者更深入点统一做初始化:
+++ b/Python/pylifecycle.c
@@ -1029,6 +1029,7 @@ Py_InitializeEx(int install_sigs)
/* bpo-33932: Calling Py_Initialize() twice does nothing. */
return;
}
+ SomeInitCode(args);
_PyInitError err;
_PyCoreConfig config = _PyCoreConfig_INIT;
这里做什么寄籍想不多说。
指令级保护
这里可以对每条指令的操作码做某种快速变换,这些操作都是在寄存器中完成不写入内存,这能使内存中始终不会出现原始的字节码:
+++ b/Python/ceval.c
@@ -22,6 +22,14 @@
#include <ctype.h>
+#define CO_ENCRYPTED_CODE 0x0400
+#define CO_SUBSITUTE_CODE 0X0800
+#ifdef _Py_OPCODE
+#undef _Py_OPCODE
+#endif
+#define _Py_OPCODE(word) SomeAlternate(word)
在执行时,解释器会根据代码块的标志判断是否存在指令级保护,若存在则做变换恢复,故该级能兼容未受保护的代码,注意定义的标志位需要时CPython未使用的,不同版本可能不同,而变换时需要注意之前的指令是变长的,后来固定了要特殊处理。
代码块级保护
在代码块级保护上,主要保护的是整个代码块的代码,默认情况下所有的python字节码最终都是由ceval中的_PyEval_EvalFrameDefault解释执行,它的参数是一个PyFrameObject对象,包括要执行的代码与上下文,因此可在该函数内部再做解密操作,代码如下:
+++ b/Python/ceval.c
co = f->f_code; // 获取代码对象
....
first_instr = (_Py_CODEUNIT *) PyBytes_AS_STRING(co->co_code); // 字节码首地址
decrypt(first_instr, first_instr, PyBytes_GET_SIZE(co->co_code)); // 解密字节码
for (;;) { // 开始循环解释字节码
switch (opcode) {
TARGET(NOP)
FAST_DISPATCH();
......
}
}
encrypt(first_instr, first_instr, PyBytes_GET_SIZE(co->co_code)); //运行结束,加密字节码
这里在解释前解密,运行完再加密,也可以运行前解密,运行完销毁内存,这能防止直接通过inspect和marshal去dump内存中的字节码。
文件级保护
一个代码中不仅逻辑重要,而且各种变量,常量等信息也十分重要,例如一个攻击脚本它的payload常数相对代码逻辑可能更重要,而上面两种保护主要保护的是代码逻辑,此处的却是一种整体保护,如下,受保护的代码和普通代码在导入时无任何区别,本方案在底层函数上做了判断,若是受保护方案则会先在内存中解密文件级加密:
+++ Python/marshal.c
@@ -1554,6 +1564,20 @@ PyMarshal_ReadLastObjectFromFile(FILE *fp)
char* pBuf = (char *)PyMem_MALLOC(filesize);
if (pBuf != NULL) {
size_t n = fread(pBuf, 1, (size_t)filesize, fp);
+ if (*(int*)s == XXXXXX) {
+ s = SomeDecrypt(s);
+ }
PyObject* v = PyMarshal_ReadObjectFromString(pBuf, n);
PyMem_FREE(pBuf);
return v;
@@ -1789,16 +1813,33 @@ marshal_loads_impl(PyObject *module, Py_buffer *bytes)
RFILE rf;
char *s = bytes->buf;
Py_ssize_t n = bytes->len;
+ if (*(int*)s == XXXXXX) {
+ s = SomeDecrypt(s);
+ }
PyObject* result;
rf.fp = NULL;
反调试与内存dump
首先,要防止攻击者使用python自带api获取python内部受保护的数据,为此做了如下修改:
- 当访问code对象时,若code对象被加密,则无法访问co_code,co_consts等属性:
+++ Objects/object.c
@@ -1197,6 +1197,7 @@ _PyObject_GetMethod(PyObject *obj, PyObject *name, PyObject **method)
}
/* Generic GetAttr functions - put these in your tp_[gs]etattro slot. */
+char* senstive[] = { "co_flags", "co_code","co_consts","co_varnames","__dir__" };
PyObject *
_PyObject_GenericGetAttrWithDict(PyObject *obj, PyObject *name,
@@ -1221,6 +1222,16 @@ _PyObject_GenericGetAttrWithDict(PyObject *obj, PyObject *name,
name->ob_type->tp_name);
return NULL;
}
+ if ((((PyObject*)(obj))->ob_type) == &PyCode_Type && ((PyCodeObject*)(obj))->co_flags & (CO_ENCRYPTED_CODE | CO_SUBSITUTE_CODE))) {
+ char* sp = (char*)&(((PyUnicodeObject*)name)->_base.utf8_length);
+ // CANT ACCESS these fileds
+ for (int i = 0; i < 5; i++) {
+ if (0==memcmp(senstive[i], sp, strlen(senstive[i]))) {
+ return res;
+ }
+ }
+ }
+
Py_INCREF(name);
if (tp->tp_dict == NULL) {
- 在获取对象的dict属性时,若为受保护的code则返回null:
+++ b/Objects/typeobject.c
@@ -1446,9 +1446,18 @@ PyType_IsSubtype(PyTypeObject *a, PyTypeObject *b)
PyObject *
_PyObject_LookupSpecial(PyObject *self, _Py_Identifier *attrid)
{
- PyObject *res;
+ PyObject *res = NULL;
+
+ if (PyCode_Check(self)) {
+ PyCodeObject* co = (PyCodeObject*)self;
+ // CANT DIR CODE
+ if (1 || co->co_flags & (CO_ENCRYPTED_CODE | CO_SUBSITUTE_CODE))) {
+ return res;
+ }
+ }
res = _PyType_LookupId(Py_TYPE(self), attrid);
+
if (res != NULL) {
descrgetfunc f;
if ((f = Py_TYPE(res)->tp_descr_get) == NULL)
- 在dump对象时,若对象是被保护的code则抛异常禁止dump:
+++ Python/marshal.c
@@ -14,6 +14,7 @@
/*[clinic input]
module marshal
[clinic start generated code]*/
@@ -547,6 +548,13 @@ w_complex_object(PyObject *v, char flag, WFILE *p)
}
else if (PyCode_Check(v)) {
PyCodeObject *co = (PyCodeObject *)v;
+ // CANT DUMP CODE THAT IS PROTECTED OR ENCRYPTED
+ if (co->co_flags & (CO_ENCRYPTED_CODE | CO_SUBSITUTE_CODE)) {
+ W_TYPE(TYPE_CODE, p);
+ p->error = WFERR_NOMEMORY;
+ return;
+ }
+
W_TYPE(TYPE_CODE, p);
w_long(co->co_argcount, p);
w_long(co->co_kwonlyargcount, p);
- 重写了解释器执行部分,受保护的代码将会进入自定义的分支,在该分支内删除了所有debug,profife,trace相关的桩代码,使攻击者无法通过python自带的调试接口调试追踪受保护的代码:
++ b/Python/ceval.c
+PyObject* _PyEval_EvalFrameStrong(PyFrameObject* f, int throwflag);
+
PyObject *
PyEval_EvalFrameEx(PyFrameObject *f, int throwflag)
{
- PyThreadState *tstate = PyThreadState_GET();
- return tstate->interp->eval_frame(f, throwflag);
+ // if encrypt todo:modify interpreter
+ if (f->f_code->co_flags & CO_ENCRYPTED_CODE) {
+ return _PyEval_EvalFrameStrong(f, throwflag);
+ }
+ else {
+ PyThreadState* tstate = PyThreadState_GET();
+ return tstate->interp->eval_frame(f, throwflag);
+ }
}
另外,通过修改PyCodeObject结构体的域顺序来修改其内存布局,能防止攻击者通过自定义pyd扩展来操作python解释器内部数据:
+++ Include/code.h
@@ -21,14 +21,14 @@ typedef uint16_t _Py_CODEUNIT;
typedef struct {
PyObject_HEAD
int co_argcount; /* #arguments, except *args */
- int co_kwonlyargcount; /* #keyword only arguments */
int co_nlocals; /* #local variables */
+ int co_kwonlyargcount; /* #keyword only arguments */
+ int co_firstlineno; /* first source line number */
int co_stacksize; /* #entries needed for evaluation stack */
int co_flags; /* CO_..., see below */
- int co_firstlineno; /* first source line number */
- PyObject *co_code; /* instruction opcodes */
PyObject *co_consts; /* list (constants used) */
PyObject *co_names; /* list of strings (names used) */
+ PyObject* co_code; /* instruction opcodes */
PyObject *co_varnames; /* tuple of strings (local variable names) */
PyObject *co_freevars; /* tuple of strings (free variable names) */
PyObject *co_cellvars; /* tuple of strings (cell variable names) */
@@ -38,12 +38,13 @@ typedef struct {
would collapse identical functions/lambdas defined on different lines.
*/
Py_ssize_t *co_cell2arg; /* Maps cell vars which are arguments. */
+ PyObject* co_name; /* unicode (name, for reference) */
+ PyObject* co_weakreflist; /* to support weakrefs to code objects */
PyObject *co_filename; /* unicode (where it was loaded from) */
- PyObject *co_name; /* unicode (name, for reference) */
PyObject *co_lnotab; /* string (encoding addr<->lineno mapping) See
Objects/lnotab_notes.txt for details. */
void *co_zombieframe; /* for optimization only (see frameobject.c) */
- PyObject *co_weakreflist; /* to support weakrefs to code objects */
现在把这些改好了,上个VMP啥的其实很难搞,照抄除外。其实还可以继续分析继续做很多修改,但是我觉得python代码保护接下来的路也是像PHP看齐,毕竟这么多年了。。。