抽象(🐶)
之前分析过v8的字节码反编译,那个是直接借助ghidra这个框架去实现,那个工作主要聚焦在怎么讲v8 bytecode转换为ghidra p-code,而这次打算更深入的了解一个完整的过程。现在先说明下编译与反编译过程中常见的几个角色:
角色
AST
它是源代码的第一个结构化表示。它精确地反映了代码的语法结构,比如一个函数调用节点会包含函数名和所有参数子节点。
IR
广义的说所有非目标机器代码都是中间表示,如AST,ByteCode等,而本文说的是狭义的IR,它是一个独立于源语言和目标平台的通用表示,专门用于做各种优化和分析的指令集。
ByteCode
正向编译的最终产物,它是一种可移植、紧凑的二进制表示,也是本文反编译的目标。
正向编译过程
这是将高级语言代码转换成机器可执行指令的常规流程。
1.词法分析 & 语法分析 -> 抽象语法树 (AST):这个阶段的代码非常接近源语言,易于理解和静态检查。
2.语义分析 & 类型检查 (在AST上进行):编译器遍历AST,检查代码的语义是否正确。例如,变量是否已经声明,函数调用的参数数量和类型是否匹配,是否存在类型转换错误等。它确保了代码在逻辑上是有效的,为后续生成正确的IR和字节码打下基础。
3.AST -> 中间表示 (IR) -> 优化:AST虽然结构化,但对于复杂的优化(如循环优化、公共子表达式消除)来说不够方便。因此,编译器会将AST“降级”(Lowering)到一个更适合分析和优化的中间表示(IR),比如接下来要讨论的Panda IR。Panda IR通常是基于图的结构,包含了控制流图 (CFG) 和使用静态单赋值 (SSA) 形式的数据流信息,重要步骤为:
-
控制流分析 (CFA):在IR层面,编译器通过构建CFG来分析代码的执行路径,识别出循环、分支和基本块,这是进行循环优化、死代码消除等的基础。
-
数据流分析 (DFA):同样在IR上,编译器分析数据如何在代码中定义和使用。例如,常量传播(如果一个变量总是同一个常量,就直接替换它)、活跃变量分析(判断哪些变量在某一点仍然有用,用于寄存器分配)等。
4.IR -> 字节码生成:经过充分优化后,IR被转换成最终的Panda Bytecode。这个过程包括:
-
指令选择:为IR操作选择最合适的字节码指令
-
寄存器分配:为IR中的变量和临时值分配虚拟寄存器(v0, v1, ...)
5.abc文件生成:将生成的字节码、元信息和调试信息等写入文件
逆向反编译过程
这是我们的分析重点,即将二进制字节码还原成可读的高级语言形式。
1.abc文件解析:解析文件到class和method,反编译以method为单位,这里主要是获取其字节码信息
2.字节码反汇编:这是最简单的一步,将二进制的字节码指令逐条翻译成人类可读的助记符,例如将二进制0xAB 01 02 03翻译成add v1, v2, v3
3.转换为中间表示 (IR) - (Lifting & Analysis):这是反编译过程中最核心、最复杂的一步,通常被称为“提升”(Lifting)。目标是将在低级的、线性的指令,转换成一个高级的、基于图的、适合分析的结构,包括:
-
构建控制流图 (CFG):首先,通过识别所有跳转指令,将线性指令流切分成基本块(Basic Block),并构建出控制流图。
-
构建数据流图 (SSA Form):接着,在CFG的基础上,反编译器会进行数据流分析,将基于寄存器的读写操作转换成静态单赋值(SSA)形式。这意味着每个变量只会被赋值一次。在控制流的交汇点,会插入phi函数来合并不同路径的值。
-
在IR上分析与优化:一旦有了SSA形式的IR,就可以利用大量成熟的编译器算法来进行分析和简化。
这一步能输出一个经过分析和简化的、高层次的、基于图的中间表示 (IR),这个IR已经摆脱了具体寄存器的限制,转而使用带类型的、有明确依赖关系的虚拟变量,并且包含了丰富的控制流和数据流信息。
4.转换为抽象语法树 (AST) - (Structural Analysis):这一步的重点是恢复程序原始的语法结构,反编译器会分析IR的控制流图,识别出高级语言中的典型编程结构。
- 控制结构识别:通过图论算法(如支配树分析、循环查找等)在CFG上识别特定的区域(循环/条件分支),再根据各种算法(如最简单的递归规约)识别结构。
- 构建AST:每当识别出一个高级结构,反编译器就会创建一个对应的AST节点(如IfStatementNode,WhileLoopNode)。IR中经过简化的表达式树则被用作填充这些AST节点的内容(例如,if语句的条件表达式、循环体内的语句等)。
5.转换为源码 (Pretty Printing):这是反编译的最后一步,它相对机械,主要是对AST进行一次深度优先遍历:
- 遍历器会访问AST的每个节点,并根据节点的类型,按照特定语言(如ArkTS)的语法规则,将其“打印”成文本。
- 例如,当访问一个IfStatementNode时,它会先打印if (,然后递归访问并打印条件表达式子节点,接着打印) {,再递归访问并打印then分支的语句块子节点,以此类推。
- 这个过程还会负责处理代码的缩进、换行、花括号等格式,使其看起来像人类编写的代码。
ECMA/JS/TS与arkTs
先说几个容易懵的东西:
-
ECMAScript (ES):是一个由Ecma国际制定的脚本语言规范。它定义了语言的语法、类型、对象、操作符等核心部分。
-
JavaScript (JS):是 ECMAScript 规范最著名的一种实现。我们日常在浏览器和Node.js中使用的JS都遵循ECMAScript标准。
-
TypeScript (TS):是建立在 JavaScript之上的一个强类型超集。它在JS的基础上增加了静态类型、接口、泛型等,最终会被“转译”(transpile)成普通的JavaScript代码来运行,任何合法的JS代码都是合法的TS代码。
-
ArkTS:是建立在 TypeScript 之上,并针对鸿蒙应用开发场景进行优化的语言扩展。它继承了TS的所有静态类型能力,并进一步强化,同时为了AOT编译和高效运行,舍弃了TS/JS中的部分动态特性。
即ArkTS 从根本上是遵循 ECMAScript 核心规范的,但它在 TypeScript 的基础上,走上了一条更偏向“静态化”和“原生编译”的道路。
这里主要关注他们的差异点,Ark TS为了性能和安全性对TS/JS做了一些删减和强制语法:
-
ArkTS:它致力于成为一门真正的静态类型语言,所有变量在编译时都必须有明确的类型。所以不能使用
any! -
ArkTS:原生集成了声明式UI描述能力。它引入了一套以 @ 符号开头的装饰器来构建UI,这是它最显著的扩展,如
@Component定义一个自定义UI组件,@Entry标记一个组件为页面的入口等。 - 动态特性的限制:为了实现高效的AOT编译和安全性,ArkTS限制或禁用了JS/TS中一些过于动态、难以在编译期预测行为的特性。比如禁止
eval()和with(),这些动态执行代码或修改作用域的特性被完全禁止。对Object.defineProperty的限制,不能在运行时随意修改对象的结构。更严格的类定义,ArkTS的类在编译后结构是固定的,不能在运行时动态添加或删除属性和方法。
OK,你已经学会了arkts咯,咱们开始看它的编译器和运行时吧!
ABC
Panda字节码存储在后缀为.abc的文件里,所以这些反编译器都叫他abc文件,它的详细描述可见Panda File Format,或者看看010Edit的abc.bt模板文件,这里就简单说明下,总的来说,运行时所需要的信息都有,如果要调试(默认支持),调试所需的信息也都有!
PandaBC
先看看assembly_format.md,然后看isa.yaml,Panda ByteCode就是基于这个文件和同目录下的模板文件生成的。
指令细节
数据操作 (Data Movement)
这类指令负责在寄存器、累加器和内存之间移动数据:
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| No operation | nop | nop |
none |
skip |
执行一个无任何行为的操作,含一种格式['op_none'] |
| Move register-to-register | mov | mov v1:out:b32, v2:in:b32 |
none |
vd = vs |
在寄存器之间移动值,含三种格式['op_v1_4_v2_4', 'op_v1_8_v2_8', 'op_v1_16_v2_16'] |
| mov.64 | mov.64 v1:out:b64, v2:in:b64 |
none |
在寄存器之间移动值,含二种格式['op_v1_4_v2_4','op_v1_16_v2_16'] | ||
| mov.obj | mov.obj v1:out:ref, v2:in:ref |
none |
在寄存器之间移动值,含三种格式['op_v1_4_v2_4', 'op_v1_8_v2_8', 'op_v1_16_v2_16'] | ||
| Move immediate-to-register | movi | movi v:out:i32, imm:i32 |
none |
vd = imm |
将立即数移入寄存器。对于短格式,立即数会符号位扩展到操作数大小,含四种格式['op_v_4_imm_4', 'op_v_8_imm_8', 'op_v_8_imm_16', 'op_v_8_imm_32'] |
| movi.64 | movi.64 v:out:i64, imm:i64 |
none |
将立即数移入寄存器。对于短格式,立即数会符号位扩展到操作数大小,含一种格式['op_v_8_imm_64'] | ||
| fmovi | fmovi v:out:f32, imm:f32 |
none |
将立即数移入寄存器。对于短格式,立即数会符号位扩展到操作数大小,含一种格式['pref_op_v_8_imm_32'] | ||
| fmovi.64 | fmovi.64 v:out:f64, imm:f64 |
none |
将立即数移入寄存器。对于短格式,立即数会符号位扩展到操作数大小,含一种格式['op_v_8_imm_64'] | ||
| Move null reference into register | mov.null | mov.null v:out:ref |
none |
vd = null
|
将 null 引用移入寄存器,含一种格式['op_v_8'] |
| Load accumulator from register | lda | lda v:in:b32 |
out:b32 |
acc = vs |
将寄存器内容移入累加器,含一种格式['op_v_8'] |
| lda.64 | lda.64 v:in:b64 |
out:b64 |
|||
| lda.obj | lda.obj v:in:ref |
out:ref |
|||
| Load accumulator from immediate | ldai | ldai imm:i32 |
out:i32 |
acc = imm |
将立即数加载到累加器。对于短格式,立即数会符号位扩展到操作数大小,含三种格式['op_imm_8', 'op_imm_16', 'op_imm_32'] |
| ldai.64 | ldai.64 imm:i64 |
out:i64 |
将立即数加载到累加器。对于短格式,立即数会符号位扩展到操作数大小,含一种格式['op_imm_64'] | ||
| fldai | fldai imm:f32 |
out:f32 |
将立即数加载到累加器。对于短格式,立即数会符号位扩展到操作数大小,含一种格式['pref_op_imm_32'] | ||
| fldai.64 | fldai.64 imm:f64 |
out:f64 |
将立即数加载到累加器。对于短格式,立即数会符号位扩展到操作数大小,含一种格式['op_imm_64'] | ||
| Load accumulator from string constant pool | lda.str | lda.str string_id |
out:ref |
acc = load(id) |
根据ID将指定字符串加载到累加器。在动态类型语言上下文中,作为 'any' 类型加载,含一种格式['op_id_32'] |
| Load accumulator from type constant pool | lda.type | lda.type type_id |
out:ref |
|
根据ID将指定类型加载到累加器,含一种格式['op_id_16'] |
| Load null reference into accumulator | lda.null | lda.null |
out:ref |
acc = null
|
将 null 引用加载到累加器,含一种格式['op_none'] |
| Store accumulator | sta | sta v:out:b32 |
in:b32 |
vd = acc
|
将累加器内容移入寄存器,含一种格式['op_v_8'] |
| sta.64 | sta.64 v:out:b64 |
in:b64 |
|||
| sta.obj | sta.obj v:out:ref |
in:ref |
|||
| Load from array | ldarr.8 | ldarr.8 v:in:i8[] |
inout:i32 |
|
使用累加器作为索引从数组加载一个元素,并将其放入累加器,含一种格式['op_v_8'] |
| ldarru.8 | ldarru.8 v:in:u8[] |
inout:i32 |
|||
| ldarr.16 | ldarr.16 v:in:i16[] |
inout:i32 |
|||
| ldarru.16 | ldarru.16 v:in:u16[] |
inout:i32 |
|||
| ldarr | ldarr v:in:i32[] |
inout:i32 |
|||
| ldarr.64 | ldarr.64 v:in:i64[] |
inout:i32->i64 |
|||
| fldarr.32 | fldarr.32 v:in:f32[] |
inout:i32->f32 |
|||
| fldarr.64 | fldarr.64 v:in:f64[] |
inout:i32->f64 |
|||
| ldarr.obj | ldarr.obj v:in:ref[] |
inout:i32->ref |
|||
| Store to array | starr.8 | starr.8 v1:in:i8[], v2:in:i32 |
in:i8 |
|
将累加器内容存储到由索引指向的数组槽中,含一种格式['op_v1_4_v2_4'] |
| starr.16 | starr.16 v1:in:i16[], v2:in:i32 |
in:i16 |
|||
| starr | starr v1:in:i32[], v2:in:i32 |
in:i32 |
|||
| starr.64 | starr.64 v1:in:i64[], v2:in:i32 |
in:i64 |
|||
| fstarr.32 | fstarr.32 v1:in:f32[], v2:in:i32 |
in:f32 |
|||
| fstarr.64 | fstarr.64 v1:in:f64[], v2:in:i32 |
in:f64 |
|||
| starr.obj | starr.obj v1:in:ref[], v2:in:i32 |
in:ref |
|||
| Get field from object to accumulator | ldobj | ldobj v:in:ref, field_id |
out:b32 |
|
通过字段id从对象获取字段值,并将其放入累加器,含一种格式['op_v_8_id_16'] |
| ldobj.64 | ldobj.64 v:in:ref, field_id |
out:b64 |
|||
| ldobj.obj | ldobj.obj v:in:ref, field_id |
out:ref |
|||
| Store accumulator content into object field | stobj | stobj v:in:ref, field_id |
in:b32 |
|
通过字段id将累加器内容存储到对象字段中,含一种格式['op_v_8_id_16'] |
| stobj.64 | stobj.64 v:in:ref, field_id |
in:b64 |
|||
| stobj.obj | stobj.obj v:in:ref, field_id |
in:ref |
|||
| Get field from object to register | ldobj.v | ldobj.v v1:out:b32, v2:in:ref, field_id |
none |
|
通过字段id从对象获取字段值,并将其放入寄存器,含一种格式['op_v1_4_v2_4_id_16'] |
| ldobj.v.64 | ldobj.v.64 v1:out:b64, v2:in:ref, field_id |
none |
|||
| ldobj.v.obj | ldobj.v.obj v1:out:ref, v2:in:ref, field_id |
none |
|||
| Store register content into object field | stobj.v | stobj.v v1:in:b32, v2:in:ref, field_id |
none |
|
通过字段id将寄存器内容存储到对象字段中,含一种格式['op_v1_4_v2_4_id_16'] |
| stobj.v.64 | stobj.v.64 v1:in:b64, v2:in:ref, field_id |
none |
|||
| stobj.v.obj | stobj.v.obj v1:in:ref, v2:in:ref, field_id |
none |
|||
| Get static field | ldstatic | ldstatic field_id |
out:b32 |
|
通过字段id获取静态字段值,并将其放入累加器,含一种格式['op_id_16'] |
| ldstatic.64 | ldstatic.64 field_id |
out:b64 |
|||
| ldstatic.obj | ldstatic.obj field_id |
out:ref |
|||
| Store to static field | ststatic | ststatic field_id |
in:b32 |
|
通过字段id将累加器内容存储到静态字段中,含一种格式['op_id_16'] |
| ststatic.64 | ststatic.64 field_id |
in:b64 |
|||
| ststatic.obj | ststatic.obj field_id |
in:ref |
|||
| Create and initialize new constant array | lda.const | lda.const v:out:ref, literalarray_id |
none |
|
创建新一维常量字面量数组,并将其引用放入寄存器,含一种格式['op_v_8_id_16'] |
算术与逻辑运算 (Arithmetic & Logic)
这类指令执行数学计算、比较和位运算:
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| Integer comparison | cmp.64 | cmp.64 v:in:i64 |
inout:i64->i32 |
|
在寄存器和累加器之间执行指定的有符号或无符号整数比较,含一种格式['op_v_8'] |
| ucmp | ucmp v:in:u32 |
inout:u32->i32 |
在寄存器和累加器之间执行指定的有符号或无符号整数比较,含一种格式['pref_op_v_8'] | ||
| ucmp.64 | ucmp.64 v:in:u64 |
inout:u64->i32 |
在寄存器和累加器之间执行指定的有符号或无符号整数比较,含一种格式['pref_op_v_8'] | ||
| Floating-point comparison | fcmpl | fcmpl v:in:f32 |
inout:f32->i32 |
|
在寄存器和累加器之间执行指定的浮点数比较,含一种格式['pref_op_v_8'] |
| fcmpl.64 | fcmpl.64 v:in:f64 |
inout:f64->i32 |
在寄存器和累加器之间执行指定的浮点数比较,含一种格式['op_v_8'] | ||
| fcmpg | fcmpg v:in:f32 |
inout:f32->i32 |
在寄存器和累加器之间执行指定的浮点数比较,含一种格式['pref_op_v_8'] | ||
| fcmpg.64 | fcmpg.64 v:in:f64 |
inout:f64->i32 |
在寄存器和累加器之间执行指定的浮点数比较,含一种格式['op_v_8'] | ||
| Floating-point unary | fneg | fneg |
inout:f32 |
|
对累加器执行指定的浮点一元运算,含一种格式['pref_op_none'] |
| fneg.64 | fneg.64 |
inout:f64 |
对累加器执行指定的浮点一元运算,含一种格式['op_none'] | ||
| Unary | neg | neg |
inout:i32 |
|
对累加器执行指定的一元运算,含一种格式['op_none'] |
| neg.64 | neg.64 |
inout:i64 |
对累加器执行指定的一元运算,含一种格式['op_none'] | ||
| not | not |
inout:i32 |
对累加器执行指定的一元运算,含一种格式['pref_op_none'] | ||
| not.64 | not.64 |
inout:i64 |
对累加器执行指定的一元运算,含一种格式['pref_op_none'] |
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| Two address binary operation on accumulator | add2 | add2 v:in:i32 |
inout:i32
|
|
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v_8'] |
| add2.64 | add2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v_8'] | ||
| sub2 | sub2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v_8'] | ||
| sub2.64 | sub2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v_8'] | ||
| mul2 | mul2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v_8'] | ||
| mul2.64 | mul2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v_8'] | ||
| and2 | and2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| and2.64 | and2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| or2 | or2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| or2.64 | or2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| xor2 | xor2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| xor2.64 | xor2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| shl2 | shl2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| shl2.64 | shl2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| shr2 | shr2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| shr2.64 | shr2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| ashr2 | ashr2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| ashr2.64 | ashr2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| Two address binary operation on accumulator with result in register | add2v | add2v v1:out:i32, v2:in:i32
|
in:i32 |
|
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] |
| add2v.64 | add2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] | ||
| sub2v | sub2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] | ||
| sub2v.64 | sub2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] | ||
| mul2v | mul2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] | ||
| mul2v.64 | mul2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] | ||
| and2v | and2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| and2v.64 | and2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| or2v | or2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| or2v.64 | or2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| xor2v | xor2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| xor2v.64 | xor2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| shl2v | shl2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| shl2v.64 | shl2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| shr2v | shr2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| shr2v.64 | shr2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| ashr2v | ashr2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| ashr2v.64 | ashr2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| Two address floating-point binary operation on accumulator | fadd2 | fadd2 v:in:f32 |
inout:f32 |
|
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v_8'] |
| fadd2.64 | fadd2.64 v:in:f64 |
inout:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['op_v_8'] | ||
| fsub2 | fsub2 v:in:f32 |
inout:f32 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v_8'] | ||
| fsub2.64 | fsub2.64 v:in:f64 |
inout:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['op_v_8'] | ||
| fmul2 | fmul2 v:in:f32 |
inout:f32 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v_8'] | ||
| fmul2.64 | fmul2.64 v:in:f64 |
inout:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['op_v_8'] | ||
| fdiv2 | fdiv2 v:in:f32 |
inout:f32 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v_8'] | ||
| fdiv2.64 | fdiv2.64 v:in:f64 |
inout:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['op_v_8'] | ||
| fmod2 | fmod2 v:in:f32 |
inout:f32 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v_8'] | ||
| fmod2.64 | fmod2.64 v:in:f64 |
inout:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入累加器。指令结果遵循IEEE-754算术规则,含一种格式['op_v_8'] | ||
| Two address floating-point binary operation on accumulator with result in register | fadd2v | fadd2v
v1:out:f32, v2:in:f32 |
in:f32 |
|
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v1_8_v2_8'] |
| fadd2v.64 | fadd2v.64 v1:out:f64, v2:in:f64 |
in:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['op_v1_8_v2_8'] | ||
| fsub2v | fsub2v v1:out:f32, v2:in:f32 |
in:f32 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v1_8_v2_8'] | ||
| fsub2v.64 | fsub2v.64 v1:out:f64, v2:in:f64 |
in:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['op_v1_8_v2_8'] | ||
| fmul2v | fmul2v v1:out:f32, v2:in:f32 |
in:f32 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v1_8_v2_8'] | ||
| fmul2v.64 | fmul2v.64 v1:out:f64, v2:in:f64 |
in:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['op_v1_8_v2_8'] | ||
| fdiv2v | fdiv2v v1:out:f32, v2:in:f32 |
in:f32 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v1_8_v2_8'] | ||
| fdiv2v.64 | fdiv2v.64 v1:out:f64, v2:in:f64 |
in:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['op_v1_8_v2_8'] | ||
| fmod2v | fmod2v v1:out:f32, v2:in:f32 |
in:f32 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['pref_op_v1_8_v2_8'] | ||
| fmod2v.64 | fmod2v.64 v1:out:f64, v2:in:f64 |
in:f64 |
对累加器和寄存器执行指定的浮点二元运算,并将结果存入寄存器。指令结果遵循IEEE-754算术规则,含一种格式['op_v1_8_v2_8'] | ||
| Two address integer division and modulo on accumulator | div2 | div2 v:in:i32 |
inout:i32 |
|
对累加器和寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['op_v_8'] |
| div2.64 | div2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['op_v_8'] | ||
| mod2 | mod2 v:in:i32 |
inout:i32 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['op_v_8'] | ||
| mod2.64 | mod2.64 v:in:i64 |
inout:i64 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['op_v_8'] | ||
| divu2 | divu2 v:in:u32 |
inout:u32 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| divu2.64 | divu2.64 v:in:u64 |
inout:u64 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| modu2 | modu2 v:in:u32 |
inout:u32 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| modu2.64 | modu2.64 v:in:u64 |
inout:u64 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['pref_op_v_8'] | ||
| Two address integer division and modulo on accumulator with result in register | div2v | div2v v1:out:i32,
v2:in:i32 |
in:i32 |
|
对累加器和寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] |
| div2v.64 | div2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] | ||
| mod2v | mod2v v1:out:i32, v2:in:i32 |
in:i32 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] | ||
| mod2v.64 | mod2v.64 v1:out:i64, v2:in:i64 |
in:i64 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['op_v1_8_v2_8'] | ||
| divu2v | divu2v v1:out:u32, v2:in:u32 |
in:u32 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| divu2v.64 | divu2v.64 v1:out:u64, v2:in:u64 |
in:u64 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| modu2v | modu2v v1:out:u32, v2:in:u32 |
in:u32 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] | ||
| modu2v.64 | modu2v.64 v1:out:u64, v2:in:u64 |
in:u64 |
对累加器和寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['pref_op_v1_8_v2_8'] |
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| Two address binary operation with immediate on accumulator | addi | addi imm:i32 |
inout:i32 |
|
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_8'] |
| subi | subi imm:i32 |
inout:i32 |
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_8'] | ||
| muli | muli imm:i32 |
inout:i32 |
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_8'] | ||
| andi | andi imm:i32 |
inout:i32 |
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_32'] | ||
| ori | ori imm:i32 |
inout:i32 |
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_32'] | ||
| xori | xori imm:i32 |
inout:i32 |
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['pref_op_imm_32'] | ||
| shli | shli imm:i32 |
inout:i32 |
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_8'] | ||
| shri | shri imm:i32 |
inout:i32 |
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_8'] | ||
| ashri | ashri imm:i32 |
inout:i32 |
对累加器和立即数执行指定的二元运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_8'] | ||
| Two address binary operation with immediate | addiv | addiv v1:out:i32, v2:in:i32, imm:i32 |
none |
|
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_8'] |
| subiv | subiv v1:out:i32, v2:in:i32, imm:i32 |
none |
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_8'] | ||
| muliv | muliv v1:out:i32, v2:in:i32, imm:i32 |
none |
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_8'] | ||
| andiv | andiv v1:out:i32, v2:in:i32, imm:i32 |
none |
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_32'] | ||
| oriv | oriv v1:out:i32, v2:in:i32, imm:i32 |
none |
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_32'] | ||
| xoriv | xoriv v1:out:i32, v2:in:i32, imm:i32 |
none |
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['pref_op_v1_4_v2_4_imm_32'] | ||
| shliv | shliv v1:out:i32, v2:in:i32, imm:i32 |
none |
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_8'] | ||
| shriv | shriv v1:out:i32, v2:in:i32, imm:i32 |
none |
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_8'] | ||
| ashriv | ashriv v1:out:i32, v2:in:i32, imm:i32 |
none |
对寄存器和立即数执行指定的二元运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_8'] | ||
| Two address integer division or modulo with immediate on accumulator | divi | divi imm:i32 |
inout:i32 |
|
对累加器和立即数执行整数除法或取模运算,并将结果存入累加器。立即数会符号位扩展到操作数大小,含一种格式['op_imm_8'] |
| modi | modi imm:i32 |
inout:i32 |
|||
| Two address integer division or modulo with immediate | diviv | diviv v1:out:i32, v2:in:i32, imm:i32 |
none
|
|
对寄存器和立即数执行整数除法或取模运算,并将结果存入另一个寄存器。立即数会符号位扩展到操作数大小,含一种格式['op_v1_4_v2_4_imm_8'] |
| modiv | modiv v1:out:i32, v2:in:i32, imm:i32 |
none |
|||
| Increment register with immediate | inci | inci v:inout:i32, imm:i32 |
none |
vx = (vx + imm) % 2^32
|
使用指定的立即数增加虚拟寄存器的值。立即数会符号位扩展到操作数大小,含一种格式['op_v_4_imm_4'] |
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| Three address binary operation | add | add v1:in:i32, v2:in:i32 |
out:i32 |
|
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v1_4_v2_4'] |
| sub | sub v1:in:i32, v2:in:i32 |
out:i32 |
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v1_4_v2_4'] | ||
| mul | mul v1:in:i32, v2:in:i32 |
out:i32 |
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['op_v1_4_v2_4'] | ||
| and | and v1:in:i32, v2:in:i32 |
out:i32 |
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v1_4_v2_4'] | ||
| or | or v1:in:i32, v2:in:i32 |
out:i32 |
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v1_4_v2_4'] | ||
| xor | xor v1:in:i32, v2:in:i32 |
out:i32 |
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v1_4_v2_4'] | ||
| shl | shl v1:in:i32, v2:in:i32 |
out:i32 |
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v1_4_v2_4'] | ||
| shr | shr v1:in:i32, v2:in:i32 |
out:i32 |
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v1_4_v2_4'] | ||
| ashr | ashr v1:in:i32, v2:in:i32 |
out:i32 |
对两个寄存器执行指定的二元运算,并将结果存入累加器,含一种格式['pref_op_v1_4_v2_4'] | ||
| Three address binary operation with result in register | addv | addv v1:inout:i32, v2:in:i32 |
none
|
|
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_4_v2_4'] |
| subv | subv v1:inout:i32, v2:in:i32 |
none |
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_4_v2_4'] | ||
| mulv | mulv v1:inout:i32, v2:in:i32 |
none |
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['op_v1_4_v2_4'] | ||
| andv | andv v1:inout:i32, v2:in:i32 |
none |
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_4_v2_4'] | ||
| orv | orv v1:inout:i32, v2:in:i32 |
none |
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_4_v2_4'] | ||
| xorv | xorv v1:inout:i32, v2:in:i32 |
none |
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_4_v2_4'] | ||
| shlv | shlv v1:inout:i32, v2:in:i32 |
none |
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_4_v2_4'] | ||
| shrv | shrv v1:inout:i32, v2:in:i32 |
none |
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_4_v2_4'] | ||
| ashrv | ashrv v1:inout:i32, v2:in:i32 |
none |
对两个寄存器执行指定的二元运算,并将结果存入寄存器,含一种格式['pref_op_v1_4_v2_4'] | ||
| Three address integer division or modulo | div | div v1:in:i32, v2:in:i32 |
out:i32 |
|
对两个寄存器执行整数除法或取模运算,并将结果存入累加器,含一种格式['op_v1_4_v2_4'] |
| mod | mod v1:in:i32, v2:in:i32 |
out:i32 |
|||
| Three address integer division or modulo with result in register | divv | divv v1:inout:i32, v2:in:i32 |
none |
|
对两个寄存器执行整数除法或取模运算,并将结果存入寄存器,含一种格式['op_v1_4_v2_4'] |
| modv | modv v1:inout:i32, v2:in:i32 |
none |
控制流 (Control Flow)
这类指令控制程序的执行流程,如跳转、方法调用和返回:
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| Unconditional jump | jmp | jmp imm:i32 |
none |
pc += imm |
无条件地将执行转移到距离当前指令开头 offset 字节处的指令。Offset 会符号位扩展到指令地址的大小。含三种格式['op_imm_8', 'op_imm_16', 'op_imm_32'] |
| Conditional object comparison jump | jeq.obj | jeq.obj v:in:ref, imm:i32 |
in:ref
|
|
如果累加器和源寄存器中的对象引用按指定方式比较为真,则将执行转移到距离当前指令开头 offset 字节处的指令。Offset 会符号位扩展到指令地址的大小。含二种格式['op_v_8_imm_8', 'op_v_8_imm_16'] |
| jne.obj | jne.obj v:in:ref, imm:i32 |
in:ref |
|||
| Conditional compared to null jump | jeqz.obj | jeqz.obj imm:i32 |
in:ref |
|
如果累加器中的对象引用与 null 的比较按指定方式为真,则将执行转移到距离当前指令开头 offset 字节处的指令。Offset会符号位扩展到指令地址的大小。含二种格式['op_imm_8', 'op_imm_16'] |
| jnez.obj | jnez.obj imm:i32 |
in:ref |
|||
| Conditional compared to zero jump | jeqz | jeqz imm:i32 |
in:i32 |
|
如果累加器中的有符号32位整数与0的比较按指定方式为真,则将执行转移到距离当前指令开头 offset 字节处的指令。Offset会符号位扩展到指令地址的大小。含二种格式['op_imm_8', 'op_imm_16'] |
| jnez | jnez imm:i32 |
in:i32 |
|||
| jltz | jltz imm:i32 |
in:i32 |
|||
| jgtz | jgtz imm:i32 |
in:i32 |
|||
| jlez | jlez imm:i32 |
in:i32 |
|||
| jgez | jgez imm:i32 |
in:i32 |
|||
| Conditional compared to register jump | jeq | jeq v:in:i32, imm:i32 |
in:i32 |
|
如果累加器和寄存器中的有符号32位整数按指定方式比较为真,则将执行转移到距离当前指令开头 offset 字节处的指令。Offset 会符号位扩展到指令地址的大小。含二种格式['op_v_8_imm_8', 'op_v_8_imm_16'] |
| jne | jne v:in:i32, imm:i32 |
in:i32 |
|||
| jlt | jlt v:in:i32, imm:i32 |
in:i32 |
|||
| jgt | jgt v:in:i32, imm:i32 |
in:i32 |
|||
| jle | jle v:in:i32, imm:i32 |
in:i32 |
|||
| jge | jge v:in:i32, imm:i32 |
in:i32 |
|||
| Return value from method | return | return |
in:b32 |
return acc
|
从当前方法返回,返回值在累加器中。含一种格式['op_none'] |
| return.64 | return.64 |
in:b64 |
|||
| return.obj | return.obj |
in:ref |
|||
| Return from a void method | return.void | return.void |
none |
return
|
从无返回值的方法返回。调用者不能使用累加器的值。含一种格式['op_none'] |
| Throw exception | throw | throw v:in:ref |
none |
|
抛出寄存器中的异常对象。含一种格式['op_v_8'] |
| Static call | call.short | call.short method_id, v1:in:top, v2:in:top |
out:top
|
|
调用静态方法,创建新帧并传递参数。含一种格式['op_v1_4_v2_4_id_16'] |
| call | call method_id, v1:in:top, v2:in:top, v3:in:top, v4:in:top |
out:top |
调用静态方法,创建新帧并传递参数。含一种格式['op_v1_4_v2_4_v3_4_v4_4_id_16'] | ||
| call.range | call.range method_id, v:in:top |
out:top |
调用静态方法,创建新帧并传递参数。含一种格式['op_v_8_id_16'] | ||
| Static call with accumulator as input | call.acc.short | call.acc.short method_id, v:in:top, imm:u1
|
inout:top |
|
调用静态方法,累加器作为参数之一。含一种格式['op_v_4_imm_4_id_16'] |
| call.acc | call.acc method_id, v1:in:top, v2:in:top, v3:in:top, imm:u2 |
inout:top |
调用静态方法,累加器作为参数之一。含一种格式['op_v1_4_v2_4_v3_4_imm_4_id_16'] | ||
| Virtual calls | call.virt.short | call.virt.short method_id, v1:in:top, v2:in:top |
out:top |
|
调用虚方法,根据对象引用解析方法。含一种格式['op_v1_4_v2_4_id_16'] |
| call.virt | call.virt method_id, v1:in:top, v2:in:top, v3:in:top, v4:in:top |
out:top |
调用虚方法,根据对象引用解析方法。含一种格式['op_v1_4_v2_4_v3_4_v4_4_id_16'] | ||
| call.virt.range | call.virt.range method_id, v:in:top |
out:top |
调用虚方法,根据对象引用解析方法。含一种格式['op_v_8_id_16'] | ||
| Virtual calls with accumulator as input | call.virt.acc.short | call.virt.acc.short method_id, v:in:top,
imm:u1 |
inout:top |
|
调用虚方法,累加器作为参数之一。含一种格式['op_v_4_imm_4_id_16'] |
| call.virt.acc | call.virt.acc method_id, v1:in:top, v2:in:top, v3:in:top, imm:u2 |
inout:top |
调用虚方法,累加器作为参数之一。含一种格式['op_v1_4_v2_4_v3_4_imm_4_id_16'] |
类型与对象操作 (Type & Object Operations)
这类指令用于创建和操作对象、数组,以及进行类型检查:
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| Array length | lenarr | lenarr v:in:top[] |
out:i32 |
|
获取数组长度并放入累加器,含一种格式['op_v_8'] |
| Create new array | newarr | newarr v1:out:ref, v2:in:i32, type_id |
none |
|
创建给定类型和大小的新一维数组,并将其引用放入寄存器,含一种格式['op_v1_4_v2_4_id_16'] |
| Create new object | newobj | newobj v:out:ref, type_id |
none |
|
根据type_id解析类,为对象分配内存,并将其引用放入寄存器,含一种格式['op_v_8_id_16'] |
| Create new object and call initializer | initobj.short | initobj.short method_id, v1:in:none, v2:in:none |
< code>out:ref |
|
根据初始化方法的method_id解析类,分配内存,调用初始化方法,并将新对象的引用放入累加器,含一种格式['op_v1_4_v2_4_id_16'] |
| initobj | initobj method_id, v1:in:none, v2:in:none, v3:in:none, v4:in:none |
out:ref |
根据初始化方法的method_id解析类,分配内存,调用初始化方法,并将新对象的引用放入累加器,含一种格式['op_v1_4_v2_4_v3_4_v4_4_id_16'] | ||
| initobj.range | initobj.range method_id, v:in:none |
out:ref |
根据初始化方法的method_id解析类,分配内存,调用初始化方法,并将新对象的引用放入累加器,含一种格式['op_v_8_id_16'] | ||
| Check cast | checkcast | checkcast type_id |
in:ref |
|
根据ID解析对象类型,如果累加器中的对象可以转换为该类型,则累加器内容不变。否则抛出ClassCastException,含一种格式['op_id_16'] |
| Is instance | isinstance | isinstance type_id |
inout:ref->i32 |
|
根据ID解析对象类型,如果累加器中的对象是该类型的实例,则将1放入累加器,否则放入0,含一种格式['op_id_16'] |
类型转换 (Type Conversion)
这类指令用于在不同的原始数据类型之间进行转换:
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| Conversions between integer and floating point types | i32tof32 | i32tof32 |
inout:i32->f32
| (dest_type) acc = (src_type) acc |
对累加器执行指定的原始类型转换。从浮点到整数的转换遵循向零舍入的规则,并处理溢出、无穷大和NaN的情况,含一种格式['pref_op_none'] |
| i32tof64 | i32tof64 |
inout:i32->f64 |
|||
| u32tof32 | u32tof32 |
inout:u32->f32 |
|||
| u32tof64 | u32tof64 |
inout:u32->f64 |
|||
| i64tof32 | i64tof32 |
inout:i64->f32 |
|||
| i64tof64 | i64tof64 |
inout:i64->f64 |
|||
| u64tof32 | u64tof32 |
inout:u64->f32 |
|||
| u64tof64 | u64tof64 |
inout:u64->f64 |
|||
| f32tof64 | f32tof64 |
inout:f32->f64 |
|||
| f32toi32 | f32toi32 |
inout:f32->i32 |
|||
| f32toi64 | f32toi64 |
inout:f32->i64 |
|||
| f32tou32 | f32tou32 |
inout:f32->u32 |
|||
| f32tou64 | f32tou64 |
inout:f32->u64 |
|||
| f64toi32 | f64toi32 |
inout:f64->i32 |
|||
| f64toi64 | f64toi64 |
inout:f64->i64 |
|||
| f64tou32 | f64tou32 |
inout:f64->u32 |
|||
| f64tou64 | f64tou64 |
inout:f64->u64 |
|||
| f64tof32 | f64tof32 |
inout:f64->f32 |
|||
| Conversions from integer types to u1 | i32tou1 | i32tou1 |
inout:i32->u1 |
(dest_type) acc = (src_type) acc
|
从整数类型到u1(布尔)的转换:如果整数不为零,结果为1;否则结果为0,含一种格式['pref_op_none'] |
| i64tou1 | i64tou1 |
inout:i64->u1 |
|||
| u32tou1 | u32tou1 |
inout:u32->u1 |
|||
| u64tou1 | u64tou1 |
inout:u64->u1 |
|||
| Integer truncations and extensions. | i32toi64 | i32toi64 |
inout:i32->i64 |
(dest_type) acc = (src_type) acc |
对累加器执行指定的整数扩展或截断。截断保留目标类型的位数。扩展根据源类型是否为有符号,进行符号位扩展或零扩展,含一种格式['pref_op_none'] |
| i32toi16 | i32toi16 |
inout:i32->i16 |
|||
| i32tou16 | i32tou16 |
inout:i32->u16 |
|||
| i32toi8 | i32toi8 |
inout:i32->i8 |
|||
| i32tou8 | i32tou8 |
inout:i32->u8 |
|||
| i64toi32 | i64toi32 |
inout:i64->i32 |
|||
| u32toi64 | u32toi64 |
inout:u32->i64 |
|||
| u32toi16 | u32toi16 |
inout:u32->i16 |
|||
| u32tou16 | u32tou16 |
inout:u32->u16 |
|||
| u32toi8 | u32toi8 |
inout:u32->i8 |
|||
| u32tou8 | u32tou8 |
inout:u32->u8 |
|||
| u64toi32 | u64toi32 |
inout:u64->i32 |
|||
| u64tou32 | u64tou32 |
inout:u64->u32 |
动态语言支持 (Dynamic Language Support)
这些是专门为动态类型语言设计的特殊指令:
| 指令组 | 助记符 | 签名 | acc | 伪代码 | 中文说明 |
|---|---|---|---|---|---|
| Dynamic move register-to-register | mov.dyn | mov.dyn v1:out:any, v2:in:any |
none |
vd = vs |
在寄存器之间移动 'any' 类型的值,含两种格式['op_v1_8_v2_8', 'op_v1_16_v2_16'] |
| Dynamic load accumulator from register | lda.dyn | lda.dyn v:in:any |
out:any |
acc = v
|
将 'any' 类型的值从寄存器移动到累加器,含一种格式['op_v_8'] |
| Dynamic store accumulator | sta.dyn | sta.dyn v:out:any |
in:any |
v = acc |
将 'any' 类型的值从累加器移动到寄存器,含一种格式['op_v_8'] |
| Dynamic load accumulator from immediate | ldai.dyn | ldai.dyn imm:i32 |
out:any |
acc = imm |
将立即数作为 'any' 类型值移动到累加器,含一种格式['op_imm_32'] |
| fldai.dyn | fldai.dyn imm:f64 |
out:any |
将立即数作为 'any' 类型值移动到累加器,含一种格式['op_imm_64'] |
PandaIR
总述
Panda IR是方舟编译器(鸿蒙编译器)内部使用的中间表示,它在将高级语言代码转换为目标机器码的过程中扮演着至关重要的角色。设计文档可见ir_format.md,下面主要参考它做些解释。
核心设计目标
Panda IR的设计主要围绕以下几个核心目标:
- 强大的优化与分析能力:IR的结构必须清晰,能够方便地实现和集成各种复杂的代码优化算法和分析过程
- 全面的特性支持:完全支持Panda字节码的所有功能和指令
- 聚焦目标架构:当前主要以ARM64作为核心目标架构进行优化
- 可控的编译开销:在即时编译(JIT)场景下,力求将每条字节码指令的编译开销控制在约十万条本地指令以内,这是JIT编译器的行业标准
- 良好的兼容性:具备与其他IR(如LLVM IR)相互转换的能力,以便利用其他编译器的优化成果或进行性能对比
优化与分析框架
Panda IR的一个关键特性是其对优化与分析(即Pass)的灵活管理。编译器开发者可以根据需要调整Pass的执行顺序、增删Pass,从而为不同的优化创造有利条件。例如,某些优化会为后续的其他优化准备好代码上下文。
Panda IR支持一系列丰富的优化,包括但不限于:IR构建、分支消除、检查消除、Cleanup、常量折叠、内敛优化、循环不变量移出、Lowering、加载存储消除(LSE)等(所有文档直接看这个目录吧)。同时,它也内置了多种分析能力,如别名分析、边界分析、支配树和活跃度分析和,线性序和逆后续(RPO)访问(访问者模式),这些都是实现高级优化的基础。
双层指令集
为了平衡高级语言特性与底层硬件优化的需求,Panda IR巧妙地采用了一种包含高阶和低阶指令的混合设计。
- 高阶指令:在编译初期,Panda字节码被直接转换成与之一一对应的高阶IR指令。这个阶段主要进行与具体硬件架构无关的通用优化。
- 低阶指令:在后续阶段,高阶指令会被“降级”(Lowering)为多条更接近机器指令的低阶指令。这个阶段主要进行针对ARM64架构的特定优化。
这种设计使得Panda IR既能高效地表示源码的语义,又能精细地控制最终生成的机器码。
IR结构
Panda IR选择了“基于控制流图(CFG)和静态单赋值(SSA)”的结构,而非结构更复杂的“Sea-of-Nodes”。这使得它在保证强大功能的同时,构建IR的开销更小,特别适合需要快速生成代码的轻量级编译场景。
其核心结构由以下几个部分组成:
- Graph:这是最顶层的容器,包含了关于当前方法的所有编译信息,如基本块列表、运行时接口、Pass管理器等,它可以创建/添加新指令,增删BB,构造PRO和支配树等。
- BasicBlock(基本块):代表了一段线性的、没有分支的指令序列。每个基本块都维护着其前驱和后继块的列表,形成了控制流图。一个Graph总是从一个没有前驱的Start块开始,到没有后继的End块结束。
- Instruction(指令):指令通过类继承体系实现。所有指令都派生自一个基础的Inst类,它定义了操作码、对应字节码PC、所属BB、前驱和后继指令、类型、输入(每个源操作数数据来自的指令地址)、用户(User 目的操作数被使用的指令地址)等通用信息。根据输入操作数的数量是固定的还是动态的,又分为
FixedInputsInst和DynamicInputsInst等子类。常量和函数参数作为特殊的指令,统一存放在Start块中,并保证全局唯一。为了方便管理,所有指令的属性都通过一个名为instructions.yaml的配置文件来定义和生成。
数据流表示
指令之间的输入和输出关系构成了数据流图,其访问效率直接影响JIT编译的开销。Panda IR对此进行了专门优化。指令的输入数通常是确定的,所以它根据指令的输入数量是固定的还是动态的,采用了不同的内存存储策略。对于绝大多数输入固定的指令,其输入输出信息与指令对象本身连续存储,访问效率极高。对于少数动态输入的指令(如Phi指令),则采用可动态扩容的独立存储。而指令的用户数是无法预知的,所以没有相关区分:
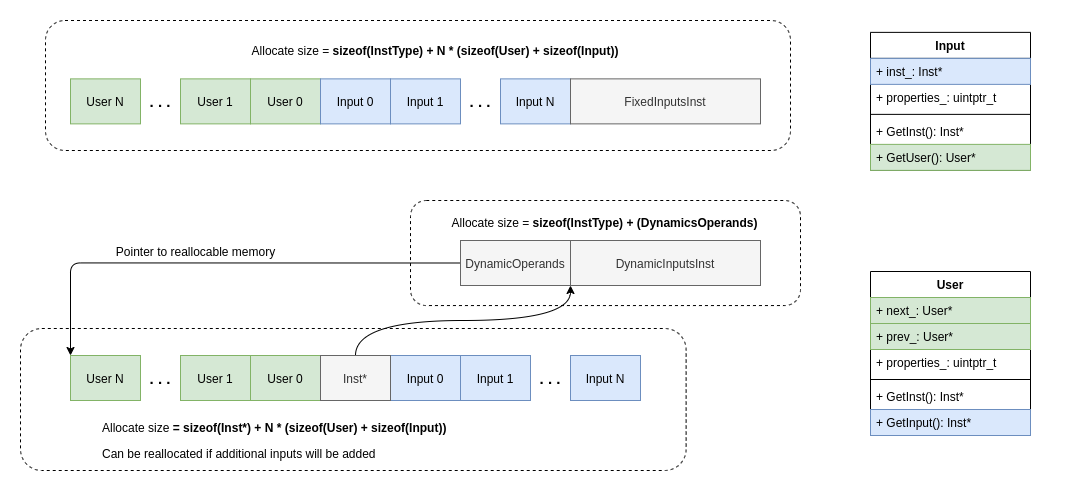
从IR到机器码的完整流程
Panda IR经过一系列优化后,会经历以下几个阶段最终生成可执行的机器码:
- Lowering(降级):将高阶IR指令转换为更接近机器码的低阶指令。
- Register Allocation(寄存器分配):负责将指令的操作数分配到CPU寄存器。Panda IR目前采用开销较低的“线性扫描”(Linear Scan)算法,这对于注重编译速度的JIT模式至关重要。
- Code Generation(代码生成):这是最后一步,将优化和分配好寄存器的IR转换为真正的ARM64机器码。为了快速实现和保证可靠性,Panda IR选择了ARM官方开发的vixl库来完成这一过程。
指令细节
对Panda IR有个大概了解后,可以看指令细节了,前面提到Panda IR也是使用yaml定义,配合templates目录下的大量模板来生成实际代码的,我就从对这个文件的解析开始,一条指令定义如下:
instructions:
- opcode: Neg # 操作码
base: UnaryOperation # 指令基类 一元操作
signature: [d-number, number] # 指令签名,即它的源和目的操作数信息
flags: [acc_write, acc_read, ifcvt] # 指令属性 如这里有acc的读写,可被用于ifcvt优化
description: Negate the value. # 指令描述
verification: # 验证模板
- $verify_unary
下面就先说下签名:
指令签名
先列出操作数类型token说明:
| 操作数标记 | 说明 |
|---|---|
| d | 标记该操作数为目的操作数(输出) |
| i8 | 8位有符号整数 |
| i16 | 16位有符号整数 |
| i32 | 32位有符号整数 |
| i64 | 64位有符号整数 |
| u8 | 8位无符号整数 |
| u16 | 16位无符号整数 |
| u32 | 32位无符号整数 |
| u64 | 64位无符号整数 |
| f32 | 单精度浮点数 |
| f64 | 双精度浮点数 |
| bool | 布尔类型 |
| ref | 对象引用类型 |
| ptr | 指针类型 |
| void | Void类型,表示无返回值 |
| int | 所有整数类型(bool, i8...u64)的并集 |
| float | f32 和 f64 的并集 |
| number | int 和 float 的并集,代表所有数字类型 |
| real | number 和 ref 的并集,代表数字或引用 |
| any | 类型未被静态定义(用于动态语言) |
| pseudo | 伪目的操作数,表示指令实际上不写入该寄存器 |
| zc | 零检查,表示该输入必须是ZeroCheck指令的结果 |
| bc | 边界检查,表示该输入必须是BoundsCheck指令的结果 |
| nc | 空检查,表示该输入必须是NullCheck指令的结果 |
| ngc | 负数检查,表示该输入应为NegativeCheck指令的结果 |
| save_state | 表示该输入必须是SaveState指令 |
| dyn | 动态操作数,表示该操作数可以重复零次或多次 |
签名中操作数间用逗号,分割,而单个操作数以短横线-分割指定多个属性或类型,如果有目的操作数那么它必须是第一个且有d类型。接着是指令的属性:
指令属性
| Flag | 含义 |
|---|---|
| cf | 指令影响代码的控制流(Control Flow),例如跳转、返回等 |
| terminator | 这是一个终结指令,表示当前基本块的执行会在此结束 |
| load | 指令会从内存中加载数据 |
| store | 指令会向内存中存储数据 |
| can_throw | 指令在执行过程中可能会抛出异常 |
| call | 这是一个函数或方法调用指令 |
| is_check | 这是一个运行时检查指令(如空指针检查、边界检查),通常也带有can_throw标志 |
| no_dce | 指令不能被死代码消除(Dead Code Elimination)优化所移除 |
| no_cse | 指令不能被公共子表达式消除(Common Subexpression Elimination)优化 |
| no_dst | 指令没有目标操作数(即不产生结果) |
| no_nullptr | 指令的执行结果不会是nullptr |
| pseudo_dst | 指令有一个伪目标操作数,它不实际影响数据流 |
| implicit_runtime_call | 指令在加载源操作数之前可能会调用运行时,这期间垃圾回收(GC)可能会移动对象 |
| low_level | 这是一个低阶指令,更接近于机器码 |
| no_hoist | 该指令不能被循环不变量外提(Loop Hoisting)等优化提前执行 |
| barrier | 该指令是指令调度(Instruction Scheduling)的一个屏障,不允许其他指令跨越它重排 |
| ref_special | 一个特殊的引用相关指令,不能被移动到运行时调用的另一侧 |
| ifcvt | 该指令可以被用于if-conversion优化(将分支转换为无分支的条件执行指令) |
| require_state | 该指令可能会调用运行时,因此需要一个SaveState作为其输入,以保存当前状态 |
| runtime_call | 该指令必定会调用运行时(Runtime) |
| commutative | 该指令满足交换律,即操作数的顺序不影响结果(如Add, Or, And) |
| alloc | 该指令会在堆(Heap)上分配一个新的对象 |
| acc_read | 该指令会读取累加器(Accumulator)寄存器 |
| acc_write | 该指令会写入累加器(Accumulator)寄存器 |
| heap_inv | 该指令会使已知的堆信息失效(Invalidates heap) |
| mem_barrier | 该指令之后需要插入一个内存屏障 |
| native | 该指令用于生成非托管(Native)代码 |
| can_deoptimize | 该指令的执行可能会触发去优化(Deoptimization),并切换到解释器执行 |
| catch_input | 该指令用于catch块中 |
| require_tmp | 该指令的实现需要一个额外的通用临时寄存器 |
指令表
Panda IR本身不是拿来手写的,通常使用它会直接使用CreateXX去创建指令,它的构造函数会也会设置Input,所以它不像字节码有助记形式的表达式,不过官方也提供了一个口之,若想手写IR可使用irtoc,详见irtoc.md文档:
现在列出存在的所有指令与说明:
算数/比较运算
| 指令名称 | 指令签名 | 指令标志 | 指令说明 |
|---|---|---|---|
| Neg | d-number, number |
acc_write, acc_read, ifcvt | 取反 |
| Abs | d-number, number |
acc_write, ifcvt | 取绝对值 |
| Sqrt | d-float, float |
acc_write, ifcvt | 计算平方根 |
| Not | d-int-bool, int-bool |
acc_write, acc_read, ifcvt | 按位取反 |
| Add | d-number-ptr, number-ptr, number-ptr |
commutative, acc_write, acc_read, ifcvt | 将两个输入相加 |
| Sub | d-number-ptr, number-ptr, number-ptr |
acc_write, acc_read, ifcvt | 将两个输入相减 |
| Mul | d-number, number, number |
commutative, acc_write, acc_read, ifcvt | 将两个输入相乘 |
| MulOverflowCheck | d-int, int, int, save_state |
no_dce, no_hoist, no_cse, barrier, acc_read, require_state, can_deoptimize | 两数相乘,如果发生溢出则去优化 |
| Div | d-number, number, number-zc |
acc_write, acc_read | 将两个输入相除 |
| Mod | d-number, number, number-zc |
acc_write, acc_read | 取模 |
| Min | d-number, number, number |
commutative, ifcvt | 从两个输入中获取最小值 |
| Max | d-number, number, number |
commutative, ifcvt | 从两个输入中获取最大值 |
| Shl | d-int, int, int |
acc_write, acc_read, ifcvt | 左移 |
| Shr | d-int, int, int |
acc_write, acc_read, ifcvt | 右移 |
| AShr | d-int, int, int |
acc_write, acc_read, ifcvt | 算术左移 |
| And | d-int-bool, int-bool, int-bool |
commutative, acc_write, acc_read, ifcvt | 按位与 |
| Or | d-int-bool, int-bool, int-bool |
commutative, acc_write, acc_read, ifcvt | 按位或 |
| Xor | d-int-bool, int-bool, int-bool |
commutative, acc_write, acc_read, ifcvt | 按位异或 |
| Compare | d-bool, real-any, real-any |
acc_read, acc_write, ifcvt | 根据条件码比较两个整数或引用值 |
| Cmp | d-int, number, number |
acc_read, acc_write, ifcvt | 比较两个浮点数或整数值 |
| CompareAnyType | d-bool, any |
acc_read, acc_write, ifcvt | 比较任意动态类型的值和类型 |
| GetAnyTypeName | d-any |
acc_read, acc_write, ifcvt, no_hoist, ref_special | 获取带有任意类型名称的字符串 |
| CastAnyTypeValue | d-real, any |
acc_read, acc_write | 将任意动态类型值转换为编译器类型值 |
| CastValueToAnyType | d-any, real |
acc_read, acc_write | 将编译器类型值转换为任意动态类型值 |
| Cast | d-real, real |
acc_read, acc_write, ifcvt | 将值从一种类型转换到另一种 |
| Bitcast | d-real-ptr, real-ptr |
ifcvt | 将值从一种类型按位转换为另一种 |
| Constant | d-i32-i64-f32-f64-any |
no_cse, ifcvt | 常量值 |
| Parameter | d-real-any |
no_cse, no_hoist | 方法的参数 |
| NullPtr | d-ref |
no_cse, no_hoist, ifcvt | 空指针 |
| LoadUndefined | d-ref |
load | 从TLS加载Undefined对象 |
对象和数组指令
| 指令名称 | 指令签名 | 指令标志 | 指令说明 |
|---|---|---|---|
| NewArray | d-ref, ref, int-ngc, save_state |
can_throw, no_dce, no_hoist, no_cse, alloc, require_state, runtime_call, mem_barrier | 创建新数组 |
| NewObject | d-ref, ref, save_state |
can_throw, no_dce, no_hoist, no_cse, alloc, require_state, runtime_call, mem_barrier | 创建新对象 |
| InitObject | d-ref, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, alloc, require_state, runtime_call, acc_write | 创建新对象并调用其默认构造函数 |
| InitEmptyString | d-ref, save_state |
can_throw, no_dce, no_hoist, no_cse, alloc, require_state, runtime_call, acc_write | 创建并初始化空字符串 |
| InitString | d-ref, ref, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, alloc, require_state, runtime_call, acc_write | 创建并初始化字符串 |
| LoadArray | d-real-any, ref-any-nc, int-bc |
load, no_hoist, no_cse, acc_read, acc_write | 从数组加载值 |
| LoadCompressedStringChar | d-u16, ref-nc, int-bc, int |
load, no_cse, acc_read, acc_write | 当字符串压缩启用时,从字符串加载字符 |
| StoreArray | ref-nc-any, int-bc, real-any |
store, no_dce, no_hoist, no_cse, acc_read, require_tmp | 在数组中存储值 |
| LoadObject | d-real-any, ref-nc-any |
load, no_hoist, no_cse, acc_write | 从对象的字段加载值 |
| LoadObjectDynamic | d-any, ref-any, any, any |
load, no_hoist, no_cse, acc_write | 从动态对象的字段加载值 |
| Load | d-real-any, ptr-ref, int |
native, low_level, load, no_hoist, no_cse | 按偏移从内存加载值 |
| LoadI | d-real-any, ptr-ref |
native, low_level, load, no_hoist, no_cse | 按立即数偏移从内存加载值 |
| Store | ptr-ref-any, int, real-any |
native, low_level, store, no_dce, no_hoist, no_cse | 按偏移在内存中存储值 |
| StoreI | ptr-ref, real-any |
native, low_level, store, no_dce, no_hoist, no_cse | 按立即数偏移在内存中存储值 |
| ResolveObjectField | d-u32, save_state |
can_throw, no_dce, require_state, runtime_call | 解析对象的字段 |
| LoadResolvedObjectField | d-real, ref-nc, u32 |
load, no_hoist, no_cse, acc_write | 从已解析的对象字段加载值 |
| StoreObject | ref-nc, real-any |
store, no_dce, no_hoist, no_cse, acc_read | 在对象的字段中存储值 |
| StoreObjectDynamic | d-any, ref-any, any, any, any |
store, no_dce, no_hoist, no_cse, acc_read | 在动态对象的字段中存储值 |
| StoreResolvedObjectField | ref-nc, real, u32 |
store, no_dce, no_hoist, no_cse, acc_read, require_tmp | 在已解析的对象字段中存储值 |
| LoadStatic | d-real, ref |
load, no_hoist, no_cse, acc_write | 从类加载静态字段 |
| ResolveObjectFieldStatic | d-ref, save_state |
can_throw, no_dce, require_state, runtime_call | 解析对象的静态字段 |
| LoadResolvedObjectFieldStatic | d-real, ref |
load, no_hoist, no_cse, acc_write | 从已解析的静态对象字段加载值 |
| StoreStatic | ref, real |
store, no_dce, no_hoist, no_cse, acc_read | 将值存储到静态字段 |
| UnresolvedStoreStatic | real, save_state |
store, can_throw, no_dce, no_hoist, no_cse, barrier, require_state, runtime_call, implicit_runtime_call, require_tmp | 将值存储到未解析的静态字段 |
| StoreResolvedObjectFieldStatic | ref, real |
store, no_dce, no_hoist, no_cse | 将值存储到已解析的静态字段 |
| LenArray | d-int, ref-nc |
acc_write | 获取数组的长度 |
| LoadString | d-ref, save_state |
load, can_throw, no_hoist, no_cse, require_state, runtime_call, acc_write | 从常量池加载字符串 |
| LoadFromConstantPool | d-any, any |
load, acc_write | 从动态常量池加载对象 |
| LoadConstArray | d-ref, save_state |
load, can_throw, no_hoist, no_dce, no_cse, require_state, barrier, runtime_call | 通过id创建新的常量数组并填充其内容 |
| LoadConstantPool | d-any, any |
load | 从函数对象加载常量池 |
| LoadLexicalEnv | d-any, any |
load | 从函数对象加载词法环境 |
| FillConstArray | ref, save_state |
store, no_hoist, no_dce, no_cse, no_dst, require_state, barrier, runtime_call, require_tmp | 填充常量数组的内容 |
| LoadType | d-ref, save_state |
load, can_throw, no_hoist, no_cse, require_state, runtime_call, acc_write | 从常量池加载类型 |
| UnresolvedLoadType | d-ref, save_state |
load, can_throw, no_dce, no_hoist, barrier, no_cse, require_state, runtime_call | 从常量池加载未解析的类型 |
| CheckCast | ref, ref, save_state |
can_throw, no_dce, no_hoist, no_cse, require_state, runtime_call, acc_read | 检查对象是否可以转换为指定类型 |
| IsInstance | d-bool, ref, ref, save_state |
require_state, runtime_call, acc_read, acc_write | 检查对象是否是指定类型的实例 |
| InitClass | save_state |
can_throw, no_hoist, barrier, no_dce, require_state, runtime_call | 在内联函数前调用类的初始化 |
| LoadClass | d-ref, save_state |
can_throw, no_hoist, barrier, no_dce, require_state, runtime_call | 加载类 |
| LoadAndInitClass | d-ref, save_state |
can_throw, no_dce, no_hoist, barrier, require_state, runtime_call | 在LoadStatic和StoreStatic之前调用类的初始化 |
| UnresolvedLoadAndInitClass | d-ref, save_state |
can_throw, no_dce, no_cse, no_hoist, barrier, require_state, runtime_call | 为未解析的类调用初始化 |
| LoadRuntimeClass | d-ref |
ref_special | 从线程寄存器获取特殊的运行时类 |
| GetInstanceClass | d-ref, ref |
ref_special | 从输入对象获取类 |
| LoadImmediate | d-ref-ptr-any |
ifcvt | 从立即数获取对象 |
| FunctionImmediate | d-any |
load, ifcvt | 从立即数获取函数 |
| LoadObjFromConst | d-ref-any |
load, ifcvt | 从句柄/常量内存加载对象 |
| GetGlobalVarAddress | d-ref, any, save_state |
can_throw, no_hoist, barrier, no_dce, require_state, runtime_call | 获取全局变量地址 |
检查指令
| 指令名称 | 指令签名 | 指令标志 | 指令说明 |
|---|---|---|---|
| NullCheck | d-ref-pseudo, ref, save_state |
can_throw, is_check, no_dce, no_hoist, no_cse, require_state | 检查对象是否不为null |
| BoundsCheck | d-int-pseudo, int, int, save_state |
can_throw, is_check, no_dce, no_cse, no_hoist, require_state, acc_read | 检查值是否在指定边界内 |
| RefTypeCheck | d-ref-pseudo, ref, ref, save_state |
can_throw, no_dce, is_check, no_hoist, no_cse, require_state, runtime_call | 检查存储的引用类型是否与数组类型匹配 |
| ZeroCheck | d-int-pseudo, int, save_state |
can_throw, is_check, no_dce, no_cse, no_hoist, require_state | 检查整数值是否不为零 |
| NegativeCheck | d-int-pseudo, int, save_state |
can_throw, is_check, no_dce, no_cse, no_hoist, require_state | 检查整数值是否小于零 |
| NotPositiveCheck | d-int-pseudo, int, save_state |
can_throw, is_check, no_dce, no_cse, no_hoist, require_state | 检查整数值是否小于或等于零 |
| ObjByIndexCheck | d-any-pseudo, any, save_state |
can_throw, is_check, no_dce, no_cse, no_hoist, require_state, can_deoptimize | 检查按索引访问对象是否是访问数组 |
| AnyTypeCheck | d-any-pseudo, any, save_state |
can_throw, no_dce, no_cse, is_check, no_hoist, require_state, runtime_call, can_deoptimize | 比较任意类型值和类型,如果类型不同则去优化 |
| HclassCheck | ref, save_state |
can_throw, no_dce, no_cse, is_check, no_hoist, require_state, runtime_call, can_deoptimize | 检查对象的hclass是否适用于动态调用 |
| Deoptimize | save_state |
cf, can_throw, no_dce, no_cse, no_hoist, require_state, barrier, can_deoptimize, terminator | 无条件切换到解释器 |
| DeoptimizeIf | any-int-bool, save_state |
can_throw, no_dce, no_cse, no_hoist, require_state, acc_read, barrier, can_deoptimize | 如果值为true,则跳转到解释器 |
| DeoptimizeCompare | any-int-bool-ref-ptr, any-int-bool-ref-ptr, save_state |
can_throw, no_dce, no_cse, no_hoist, require_state, acc_read, barrier, can_deoptimize, low_level | 比较,如果结果为true,则跳转到解释器 |
| DeoptimizeCompareImm | any-int-bool-ref, save_state |
can_throw, no_dce, no_cse, no_hoist, require_state, acc_read, barrier, can_deoptimize, low_level | 与立即数比较,如果结果为true,则跳转到解释器 |
| IsMustDeoptimize | d-bool |
no_cse, no_hoist | 检查当前方法是否必须去优化 |
控制流指令
| 指令名称 | 指令签名 | 指令标志 | 指令说明 |
|---|---|---|---|
| ReturnVoid | cf, no_dce, no_hoist, no_cse, barrier, terminator | 从方法返回 | |
| Return | real-any |
cf, no_dce, no_hoist, no_cse, barrier, acc_read, terminator | 从方法返回一个值 |
| ReturnInlined | save_state |
no_dce, no_hoist, no_cse, barrier, require_state, acc_read | 从内联方法返回 |
| Throw | ref, save_state |
cf, can_throw, no_dce, no_hoist, no_cse, barrier, require_state, terminator | 抛出异常 |
调用指令
| 指令名称 | 指令签名 | 指令标志 | 指令说明 |
|---|---|---|---|
| CallStatic | d-real-void, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, runtime_call, call, acc_write, acc_read | 调用静态方法 |
| ResolveStatic | d-ptr, save_state |
can_throw, barrier, require_state, runtime_call | 为CallResolvedStatic准备方法地址 |
| CallResolvedStatic | d-real-void, ptr, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require _state, call, acc_write, acc_read | 调用由ResolveStatic解析的静态方法 |
| CallVirtual | d-real-void, ref-nc, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, runtime_call, call, acc_write, acc_read | 调用虚方法 |
| ResolveVirtual | d-ptr, ref-nc, save_state |
can_throw, barrier, require_state, runtime_call | 为CallResolvedVirtual准备方法地址 |
| CallResolvedVirtual | d-real-void, ptr, ref-nc, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, call, acc_write, acc_read | 调用由ResolveVirtual解析的虚方法 |
| CallLaunchStatic | d-real-void, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, runtime_call, call, acc_write, acc_read | 启动静态方法 |
| CallResolvedLaunchStatic | d-real-void, ptr, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, call, acc_write, acc_read | 启动由ResolveStatic解析的静态方法 |
| CallLaunchVirtual | d-real-void, ref-nc, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, runtime_call, call, acc_write, acc_read | 启动虚方法 |
| CallResolvedLaunchVirtual | d-real-void, ptr, ref-nc, real-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, call, acc_write, acc_read | 启动由ResolveVirtual解析的虚方法 |
| CallDynamic | d-any-void, any-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, runtime_call, call | 调用动态方法 |
| CallIndirect | d-real-void, ptr, real-dyn |
can_throw, no_dce, no_hoist, no_cse, barrier, call, low_level | 通过给定地址进行低阶调用 |
| Call | d-real-void-any, real-dyn |
can_throw, no_dce, no_hoist, no_cse, barrier, call, low_level | 低阶调用 |
| MultiArray | d-ref, ref, int-ngc-dyn, save_state |
can_throw, no_dce, no_hoist, no_cse, alloc, barrier, require_state, runtime_call, mem_barrier | 创建多维数组 |
| Monitor | ref-nc, save_state |
can_throw, no_dce, no_hoist, no_cse, barrier, require_state, runtime_call, acc_read | 为对象启用或禁用监视器锁 |
| Intrinsic | d-real-void-any, real-dyn |
can_throw, heap_inv, no_dce, no_hoist, no_cse, barrier, require_state, runtime_call, call, acc_write, acc_read | 直接调用运行时内置函数 |
| Builtin | d-real-void, real-dyn |
使用Encoder展开已知的内置函数 |
低级指令
| 指令名称 | 指令签名 | 指令标志 | 指令说明 |
|---|---|---|---|
| AddI | d-number-ptr, real-ptr |
low_level, acc_write, acc_read, ifcvt | 将一个值与立即数相加 |
| SubI | d-number-ptr, real-ptr |
low_level, acc_write, acc_read, ifcvt | 从一个值中减去立即数 |
| MulI | d-int, int |
low_level, acc_write, acc_read, ifcvt | 将值与立即数相乘 |
| DivI | d-int, int |
low_level, acc_write, acc_read, ifcvt | 将值除以立即数 |
| ModI | d-int, int |
low_level, acc_write, acc_read, ifcvt | 与立即数的取模指令 |
| ShlI | d-int, int |
low_level, acc_write, acc_read, ifcvt | 左移 |
| ShrI | d-int, int |
low_level, acc_write, acc_read, ifcvt | 右移 |
| AShrI | d-int, int |
low_level, acc_write, acc_read, ifcvt | 算术右移 |
| AndI | d-int-bool, int-bool |
low_level, acc_write, acc_read, ifcvt | 按位与 |
| OrI | d-int-bool, int-bool |
low_level, acc_write, acc_read, ifcvt | 按位或 |
| XorI | d-int-bool, int-bool |
low_level, acc_write, acc_read, ifcvt | 按位异或 |
| MAdd | d-number, number, number, number |
low_level, ifcvt | 乘加 |
| MSub | d-number, number, number, number |
low_level, ifcvt | 乘减 |
| MNeg | d-number, number, number |
low_level, ifcvt | 乘加取负 |
| OrNot | d-int-bool, int-bool, int-bool |
low_level, ifcvt | 第一个操作数与第二个操作数按位取反的结果进行按位或 |
| AndNot | d-int, int-bool, int-bool |
low_level, ifcvt | 第一个操作数与第二个操作数按位取反的结果进行按位与 |
| XorNot | d-int-bool, int-bool, int-bool |
low_level, ifcvt | 第一个操作数与第二个操作数按位取反的结果进行按位异或 |
| AndSR | d-int, int, int |
low_level, ifcvt | 第一个操作数与第二个操作数的移位值进行按位与 |
| OrSR | d-int, int, int |
low_level, ifcvt | 第一个操作数与第二个操作数的移位值进行按位或 |
| XorSR | d-int, int, int |
low_level, ifcvt | 第一个操作数与第二个操作数的移位值进行按位异或 |
| AndNotSR | d-int, int, int |
low_level, ifcvt | 第一个操作数与第二个操作数移位值的取反进行按位与 |
| OrNotSR | d-int, int, int |
low_level, ifcvt | 第一个操作数与第二个操作数移位值的取反进行按位或 |
| XorNotSR | d-int, int, int |
low_level, ifcvt | 第一个操作数与第二个操作数移位值的取反进行按位异或 |
| AddSR | d-int, int, int |
low_level, ifcvt | 第一个操作数与第二个操作数的移位值相加 |
| SubSR | d-int, int, int |
low_level, ifcvt | 从第一个操作数中减去第二个操作数的移位值 |
| NegSR | d-int, int |
low_level, ifcvt | 移位然后取反操作数的值 |
| BoundsCheckI | d-int-pseudo, int, save_state |
can_throw, is_check, no_dce, no_hoist, no_cse, require_state, low_level | 检查值是否在指定边界内 |
| LoadArrayI | d-real-any, ref-any-nc |
load, no_hoist, no_cse, low_level, acc_read, acc_write | 从数组加载值 |
| LoadCompressedStringCharI | d-u16, ref-nc, int |
load, no_cse, low_level, acc_read, acc_write | 当字符串压缩启用时,从字符串加载字符 |
| StoreArrayI | ref-nc, real-any |
store, no_dce, no_hoist, no_cse, low_level, acc_read | 在数组中存储值 |
| LoadArrayPair | d-real-any, ref-any-nc, int-bc |
load, no_hoist, no_cse, low_level, acc_write | 一次从数组加载多个值 |
| LoadArrayPairI | d-real-any, ref-any-nc |
load, no_hoist, no_cse, low_level, acc_write | 在立即数索引处一次从数组加载多个值 |
| LoadPairPart | d-real-any-pseudo, real-any |
load, low_level, acc_write, no_hoist, no_cse | 从向量加载元素 |
| LoadObjectPair | d-real-any, ref-any-nc |
load, no_hoist, no_cse, low_level | 一次从对象加载多个值 |
| StoreArrayPair | ref-nc, int-bc, real-any, real-any |
store, no_dce, no_hoist, no_cse, low_level, acc_read, require_tmp | 一次向数组存储多个值 |
| StoreArrayPairI | ref-nc, real-any, real-any |
store, no_dce, no_hoist, no_cse, low_level, acc_read | 在立即数索引处一次向数组存储多个值 |
| StoreObjectPair | ref-nc, real-any, real-any |
store, no_dce, no_hoist, no_cse, low_level, require_tmp | 一次向对象存储多个值 |
| ReturnI | cf, no_dce, no_hoist, no_cse, barrier, low_level, acc_read, terminator | 从方法返回一个值 |
特殊伪指令
| 指令名称 | 指令签名 | 指令标志 | 指令说明 |
|---|---|---|---|
| Phi | d-real-ref-any, real-ref-any-dyn |
no_cse, no_hoist | Phi指令 |
| SpillFill | no_cse, no_dce | 由寄存器分配器插入的伪指令 | |
| SaveState | d-real-pseudo, real-dyn |
no_hoist, no_cse | 包含在离开编译代码前必须保存的虚拟寄存器信息 |
| SafePoint | real-dyn |
no_dce, no_hoist, no_cse, barrier, runtime_call | GC安全点指令 |
| SaveStateDeoptimize | d-real-pseudo, real-dyn |
no_dce, no_hoist, no_cse, barrier | 包含在离开编译代码前必须保存的虚拟寄存器信息 |
| SaveStateOsr | d-real-pseudo, real-dyn |
no_dce, no_hoist, no_cse, barrier | 包含用于填充OSR栈图的虚拟寄存器信息 |
| Select | d-real-any, real-any, real-any, real-any, real-any |
low_level, ifcvt | 根据比较结果选择要移动到目标的值 |
| SelectImm | d-real-any, real-any, real-any, real-any |
low_level, ifcvt | 根据与立即数的比较结果选择要移动到目标的值 |
| AddOverflow | d-int, int, int |
cf, no_dce, no_hoist, no_cse, barrier, acc_read | 两数相加并检查溢出 |
| SubOverflow | d-int, int, int |
cf, no_dce, no_hoist, no_cse, barrier, acc_read | 两数相减并检查溢出 |
| AddOverflowCheck | d-int, int, int, save_state |
no_dce, no_hoist, no_cse, barrier, acc_read, require_state, can_deoptimize | 两数相加,如果发生溢出则去优化 |
| SubOverflowCheck | d-int, int, int, save_state |
no_dce, no_hoist, no_cse, barrier, acc_read, require_state, can_deoptimize | 两数相减,如果发生溢出则去优化 |
| NegOverflowAndZeroCheck | d-int, int, save_state |
no_dce, no_hoist, no_cse, barrier, acc_read, require_state, can_deoptimize | 取反,如果发生溢出则去优化 |
| If | real-any, real-any |
cf, no_dce, no_hoist, no_cse, barrier, low_level, acc_read | 执行比较和跳转 |
| IfImm | real-any |
cf, no_dce, no_hoist, no_cse, barrier, acc_read | 执行与立即数的比较和跳转 |
| NOP | no_dst, ifcvt, no_hoist | 伪指令,替换要删除的指令 | |
| Try | no_dce, no_hoist, no_cse, barrier | 伪指令,插入在try块的开头 | |
| CatchPhi | d-real-ref-any, real-ref-any-dyn |
no_hoist, no_cse | 伪指令,插入在Catch处理程序基本块中 |
| LiveIn | d-real-any |
no_dce, no_hoist, no_cse, low_level | 伪指令,定义活跃的入参寄存器 |
| LiveOut | d-real, real-any |
no_dce, no_hoist, no_cse, low_level | 伪指令,定义活跃的出参寄存器 |
伪指令
这些伪指令只是为了手动编写IR指令方便而提供的
| 指令名称 | 指令签名 | 指令标志 | 指令说明 |
|---|---|---|---|
| Else | pseudo, cf | ||
| While | pseudo, cf | ||
| Goto | pseudo, cf | ||
| Label | pseudo, cf | ||
| Register | d-real |
pseudo | |
| WhilePhi | pseudo |
arkdecompiler
现在网上有多个abc反编译项目,包括深蓝的abcd、abc-decompiler、xpanda、dayu等,这里面abcd闭源不知道咋实现的,abc-decompiler是基于jadx,xpanda和dayu似乎是完全重头实现的,俺选择arkdecompiler,因为它是在鸿蒙编译器已有框架下做了最少量工作而实现的!
编译说明
项目建议使用x64 ubuntu20.04编译,试过arm64 mac以失败告终,目前官方代码似乎有点小问题需修改:
- 直接打开dockerfile去执行里面的命令下载相关源码和预编译工具
- 打补丁,有个补丁搞反了,需要加参数反着打
- arkdecompiler里依赖的protobuf和arkcompiler不一致会造成冲突,需要改成同一个
改完这些就能编译啦
项目分析
鸿蒙编译器和运行时是开源的,arkdecompiler直接借助了鸿蒙编译器已有的能力:
1.使用panda::disasm::Disassembler解析abc文件,获取方法的汇编代码和元信息
2.使用compiler:IRBuilder完成汇编转IR,这个过程也使用了内建的的Pass优化代码
接下来,它自己实现了两个关键的步骤:
1.实现AstGen来将IR转换为AST节点,当然了这里的AST节点定义也是用的es2panda里的
2.实现ArkTSGen来将AST转换为ArkTS源码
之后有空再详细分析,溜了溜了~