本文主要关注硬件辅助虚拟化与QEMU+KVM,但为了学习思路会涉及很多其他产品,另外由于认知不足很多坑需要慢慢填,本文持续更新...

软件
先看看[20]里提供的,涉及的应用:
Bochs
它是开源的纯仿真IA32模拟器,能模拟CPU及各种外设,之前是使用解释执行[see0,see1],因此效率较低,它对CPU的各种特性模拟支持较好,若有什么特殊需求可以再来看看它(如提供完善的插桩接口),平时就扔垃圾桶吧...
QEMU+KVM
Qemu是一个开源的模拟器(emulator)与虚拟化器(virtualizer),有如下三大功能:
- 用户模式仿真:在Linux下直接仿真运行其他ISA的程序,轻量且不受硬件指令集限制,但依赖Linux系统调用的ABI
-
全系统仿真:可仿真任何架构与操作系统,缺点是速度慢
-
虚拟化:使用硬件辅助虚拟化获取接近本地的速度,但只能用于架构一致且CPU支持虚拟化
Qemu除支持TCG二进制翻译外,还支持硬件加速,其依赖于具体框架:KVM(Linux),XEN,HAXM(Intel),HVF(macos),NVMM(netbsd),WHPX(windows)
本文重点关注QEMU+KVM组合,如下是QEMU+KVM的架构图:
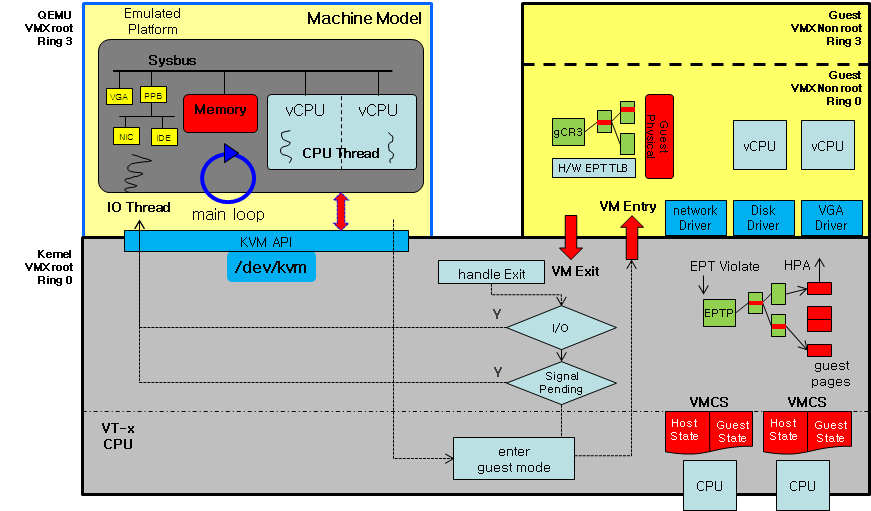
KVM是Linux内核模块,由两部分组成:
1.kvm.ko: 核心模块,提供CPU/MMU/高效设备(APIC/RTC等)的虚拟化,导出ioctl接口(/dev/kvm)与用户态通信
2.kvm-intel.ko/kvm-amd.ko: 硬件指定的虚拟化实现,如在Intel CPU上,加载kvm-intel.ko实现VMX
通过Git获取源码,昂和内核一样:
git clone https://git.kernel.org/pub/scm/virt/kvm/kvm.git
git clone https://github.com/qemu/qemu.git
昂,窑鸡用的是它,我感觉阿里云应该也有用它。
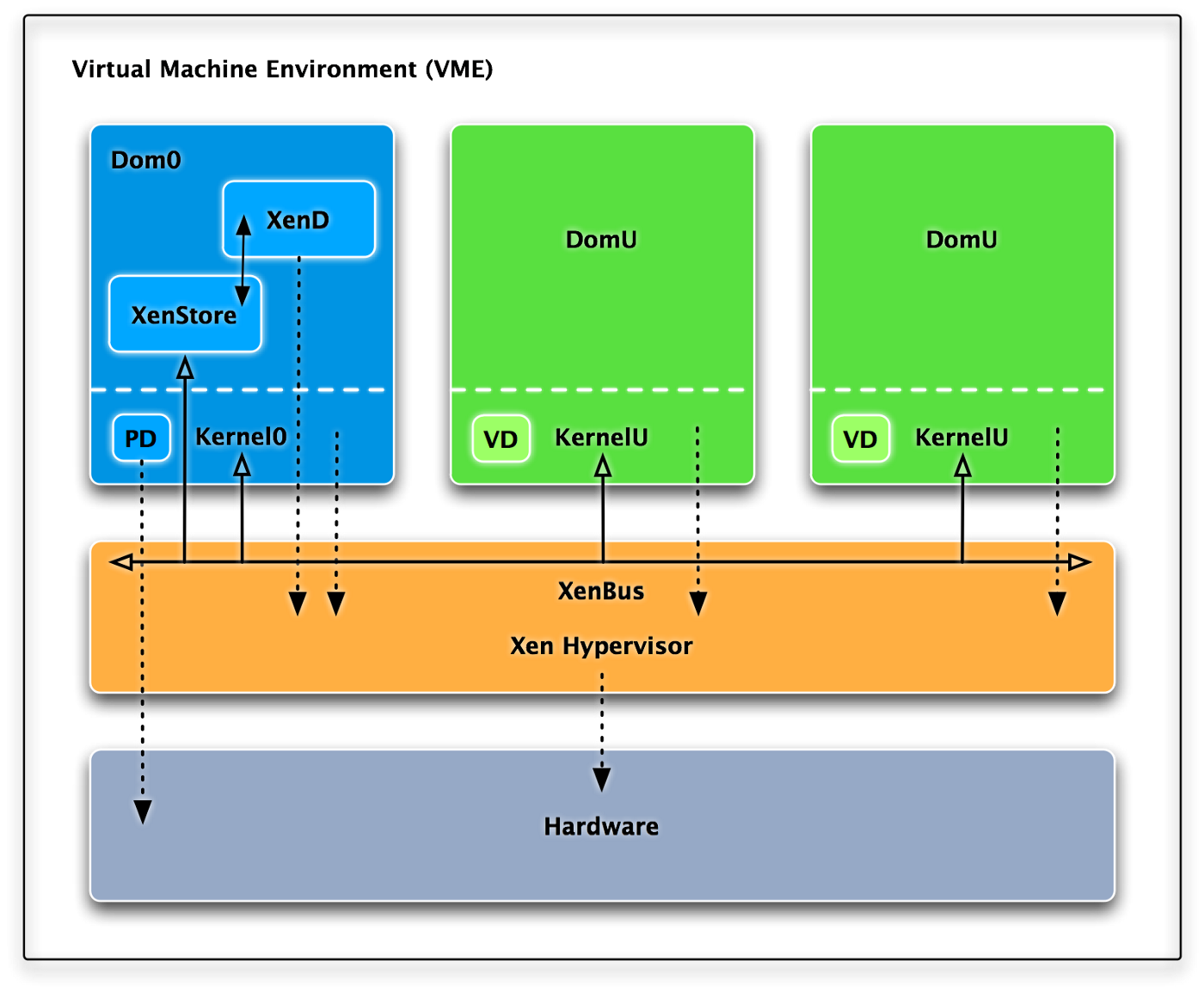
XEN
XEN是类虚拟化起家的,其架构如下,它分为多个域,其中Dom0是特权域可直接访问硬件或管理其他域:
源码在git上:
git clone https://github.com/xen-project/xen.git
亚马逊(AWS Lambda和AWS Fargate用Firecracker了),阿里云,linode等都用的它
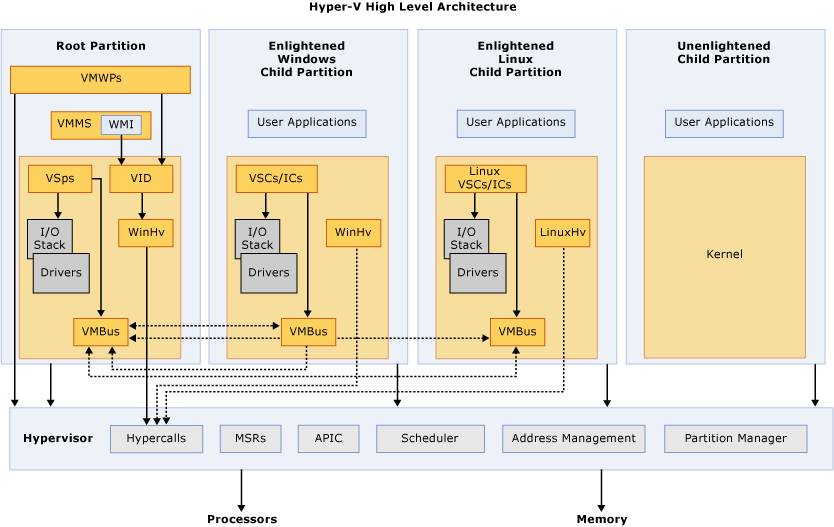
hyper-v
架构如下图,它分为多个分区,它们都只使用vCPU/vMEM,其中Root Partition(也叫Parent Partition)作为特权分区直接使用物理外设并能管理其他分区,分区间使用VMBus这个虚拟的总线通信,嗯,类虚拟化方式,通过RingBuffer实现滴,图里的术语见文档,由于是微软家的,尽管闭源但还是提供符号信息方便分析,可见"First Steps in Hyper-V Research":
VirtualBox
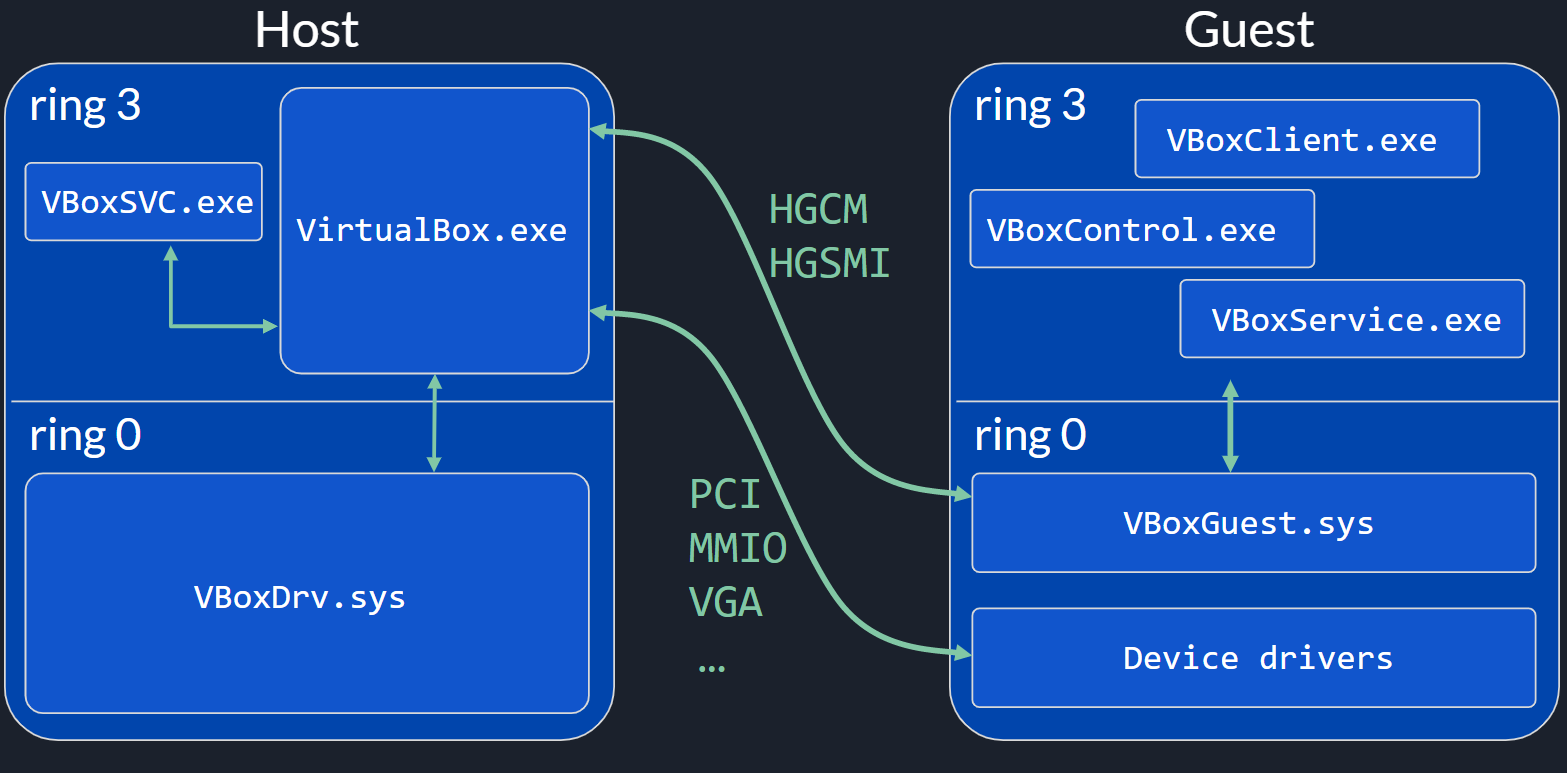
架构如下[34],它存在两种类虚拟化机制HGCM(Host-Guest Communication Manager)和HGSMI(Host-Guest Shared Memory Interface),作为2型虚拟机,它需要重点关注Host上的提权,为此它在VBoxDrv上添加很多加固措施,如设备文件仅root可访问,开启后立即降权,防止进程注入与代码签名等,详细可见[see]:
可恶的是,它竟然用svn管理源码,且svn只有最新的开发版(也可能我没找到),所以只能去归档里单独下载了...
Oracle家的,之前作为vagrant的默认提供者,不知道哪些厂商在用...
场景
分析环境
不会有人会在物理机里分析未知文件吧?!您收到一个新的附件"黑丝美少女.AVI.exe",呵小样,VMWare启动,进去吧您嘞 -- 你以为攻击者在第一层,你在第五层
逃逸,感染物理机 -- 其实攻击者在大气层
蜜罐环境
同上
云环境
这才是最普遍关注的场景,但首先需要先区分下虚拟化与云,根据红帽定义:
虚拟化是一种技术,可让用户以单个物理硬件系统为基础,创建多个模拟环境或专用资源。而云是一种能够抽象、汇集和共享整个网络中的可扩展资源的 IT 环境。简而言之,虚拟化是一项技术,而云是一种环境。

故虚拟化是云中会使用的一种基础技术,例如除了系统虚拟化,还可以使用容器虚拟化,除了虚拟化还有网络技术,还有编排管理技术等,
攻击向量与攻击面
由于认识不足,实现错误等,VM也存在许多漏洞,这依然是未正确处理不受信任的数据,不过相对来说应该比操作系统更加安全[16],这里最常见的就是虚拟机逃逸了,当然还有其他类型的安全问题,大致可归为如下几类:
1.VM从用户态到内核态提权:攻击者在Guest运行的系统上只有普通权限时,可利用虚拟化导致的漏洞提权到Guest的内核态。
2.VM干涉其他VM:干涉其他VM的正常运行,或攻击其他VM。
3.VM干涉VMM:VM利用漏洞另VMM崩溃(拒绝服务),或者访问Host上它无权访问的资源,甚至执行任意代码。
4.Host从用户态往内核态提权:主要针对Host型虚拟机,Host上用于普通权限的用户可利用虚拟机的缺陷提权到最高权限。
而从攻击面角度看,主要有两个面[5]和[11],简单来说依然是能接收数据的位置,[10]详尽的列出了QEMU实现/使用的技术与攻击面:
1.Guest内部:也是主要攻击面,含核心部分(CPU/内存等,主要是KVM做)与外设虚拟化(磁盘/网卡/显卡等,主要是QEMU),主要是设备模拟,因为它种类特别多,功能特别复杂,多变,且暴露的多(PIO/MMIO/共享内存...),再分也是类虚拟化(如Virtio/Qemu Guest Agent等),全虚拟化,设备透传(访问PCI配置空间等),三方驱动(如Virglrenderer)
2.Host外部的:VNC远程访问/SPICE远程访问VM/QMP(Qemu Machine Protocol)/Image 恶意镜像
漏洞实例
硬件漏洞
即Intel VT-x等本身存在错误/不一致导致的问题,过于深奥,当前确实发现了很多不一致,但还没有可利用点...
内存
DisturbanceError
这种漏洞很有意思,DRAM的基本单元在短时间被频繁充放电时容易干扰临近的单元导致其bit反转,DRAM是以行为单位读取且需要周期性刷新,若在一个刷新间隔内对某一行重复充放电,部分电荷会跑临近行,若在刷新前到达一定量就会bit翻转,若DRAM未纠正则个错误就大有可为了,即用RowHammer修改数据[22],在虚拟机下的攻击方式如虚拟机优化时的重复页消除导致攻击者的VM与受害者的VM某关键区域内存映射到同一物理页,正常来讲攻击者修改那一页的数据将会触发CoW而不会影响到受害者的数据,但是利用RowHammer可绕过CoW:

在攻击时,攻击者需要先找到一个特别容易翻转的行Victim Row,再将隔壁的内容映射进来等待VMM执行重复页消除,之后再锤击...
VMM CORE
VMM核心出现的问题,如CPU虚拟化,内存虚拟化等位置出现问题,这部分代码较少相对不容易出错...
CPU
XEN:XSA-105
XSA-105(CVE-2014-7155)发生在X86指令模拟上,它没有正确检测执行某些指令(LMSW/HLT/LIDT/LGDT)所需权限导致Guest可进行本地提权等攻击:
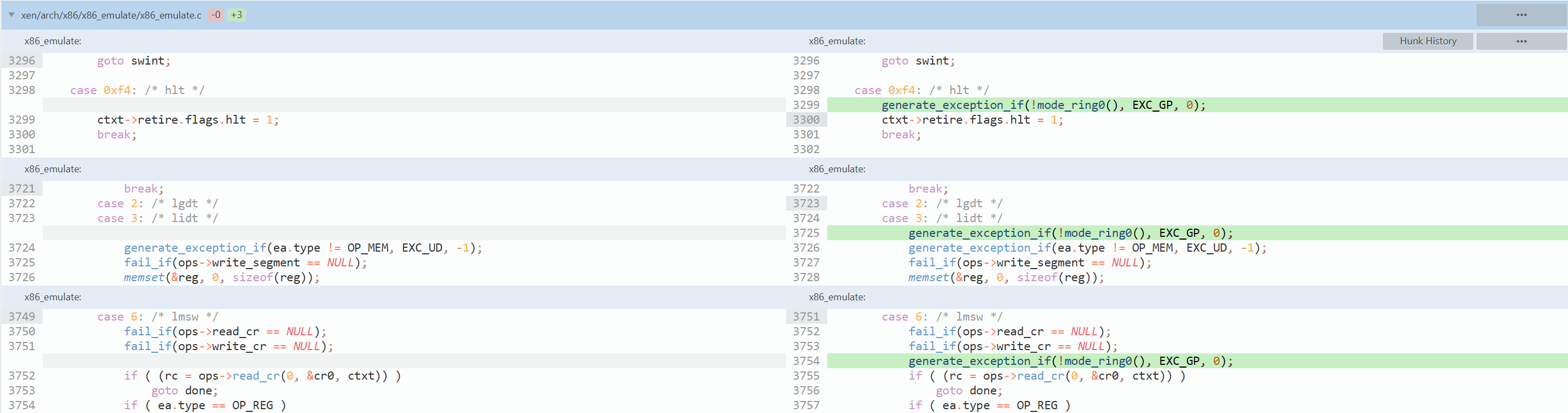
不过一般指令只会在少数情况下被模拟执行(如MMIO访问),其他情况都是直接由本地执行,这就触发不到漏洞,[19]发现#UD(未定义异常)会触发到模拟执行:
void vmx_vmexit_handler(struct cpu_user_regs *regs){
switch ( exit_reason ){
case EXIT_REASON_EXCEPTION_NMI: { // 退出理由是异常/NMI中断,向量号是#UD时
switch ( vector ) {
case TRAP_invalid_op:
HVMTRACE_1D(TRAP, vector);
vmx_vmexit_ud_intercept(regs);
...
static void vmx_vmexit_ud_intercept(struct cpu_user_regs *regs){
hvm_emulate_prepare(&ctxt, regs); // 准备模拟环境
rc = hvm_emulate_one(&ctxt); // 尝试模拟执行一条指令
...
static int _hvm_emulate_one(struct hvm_emulate_ctxt *hvmemul_ctxt,
const struct x86_emulate_ops *ops)
{
hvmemul_ctxt->insn_buf_eip = regs->eip;
if ( !vio->mmio_insn_bytes ) // 这里开始从内存中取指令信息
{
hvmemul_ctxt->insn_buf_bytes =
hvm_get_insn_bytes(curr, hvmemul_ctxt->insn_buf) ?:
(hvm_virtual_to_linear_addr(x86_seg_cs,
&hvmemul_ctxt->seg_reg[x86_seg_cs],
regs->eip,
sizeof(hvmemul_ctxt->insn_buf),
hvm_access_insn_fetch,
hvmemul_ctxt->ctxt.addr_size,
&addr) &&
hvm_fetch_from_guest_virt_nofault(hvmemul_ctxt->insn_buf, addr,
sizeof(hvmemul_ctxt->insn_buf),
pfec) == HVMCOPY_okay) ?
sizeof(hvmemul_ctxt->insn_buf) : 0;
}...
rc = x86_emulate(&hvmemul_ctxt->ctxt, ops);
而CPU提供了用于生成#UD的指令UD2(操作码为0x0F0B)且该指令非特权指令,因此可使用该指令强制触发模拟执行,而这里的代码片段可见它在模拟执行前才会从内存中取指令,有点DoubeFetch的感觉了,因此在有多vCPU情况下通过条件竞争的方式在先用UD2指令产生异常再用其他指令替换内存中的UD2指令,那么在取指令时将会取到期望的指令并执行,这里作者选择替换LIDT指令(0x0F01),它能修改IDTR使其指向用户可控空间(无SMAP),并在该空间伪造IDT,IDT里的权限(DPL)可由用户控制因此可由INT指令触发,也可以直接等外部中断触发,触发后就劫持控制流了:

如图两个线程,左侧_target本来是LIDT指令,它先将其修改为UD2指令,之后获取barrier变量(初值为0)的地址,并使用LOCK INC另它加一,LOCK锁总线强制写内存,之后轮询判断barrier的值是否为2,是才继续执行LIDT,其实此时已经是UD2了,因此会退出到模拟执行。而右侧线程也是同样的加一并轮询,因此只有它们都执行到这里时才会满足2并继续向下执行,即这样实现了同步,而左侧执行UD2时右侧执行的是将UD2改回LIDT,因为左侧会退出虚拟机并执行很多指令再到模拟的位置因此在两个vCPU在两个lCPU上同时运行时其实很容易触发的,否则多试几次也可以触发(至于之后LIDT [RAX]只是POC,实际需要设置有效的值)。这里并不用担心SMEP保护,因为可以先找关SMEP的Gadget,再运用RET2USR,他们没在内核中找到直接关SMEP的Gadget但是找到了改CR4的,如下:

能控RCX就能控CR4了,而它的返回指令时RET不是IRET因此会继续执行栈顶指向的区域,而中断时硬件操作如下:
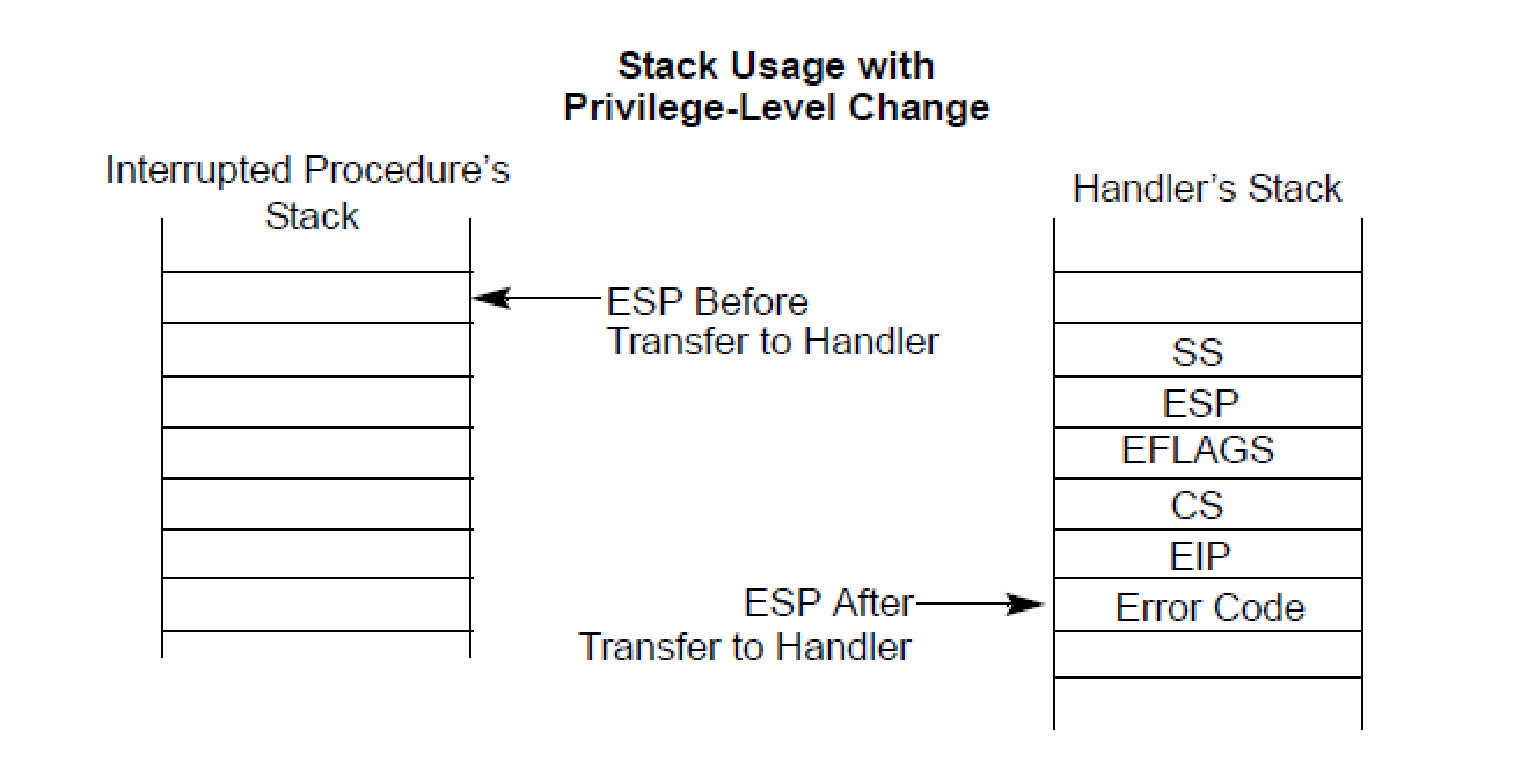
这里它只是把必要的寄存器压栈了,通用寄存器未处理而期待软件按需备份,EIP是发生中断时的位置,而错误码只有部分硬件中断有,此处可认为无错误码,因此栈顶即EIP指向可控的代码区域,CR4里内容虽多但是同操作系统基本固定因此可以正确修改,于是就能实现绕SMEP啦!XEN上的指令错误还有挨着的XSA-106(CVE-2014-7156),它发生在INT上指令上,简单的说就是把INT产生的软中断按硬件异常方式注入了,它们间的区别是INT需要判断特权级,而硬件中断不需要检查特权级,因此可导致调用任意IDT,这一般会导致系统崩溃...
Vmware在处理CR0也存在过问题,这使Guest可以为CR0设置无效值从而在VM Entry时硬件检查不通过从而使VMM崩溃...
内存
XEN:XSA-148
出名的是XEN上的XSA-148(CVE-2015-7835),XEN在内存类虚拟化时使用了直接分页,页表只能由VMM修改,Guest使用Hypercall等方式请求修改它,VMM会使用页面类型来管理内存,每页内存只能属于一种类型且在引用过程中不可改变,有如下四种类型:
None : No special uses.
LN Page table page : Pages used as a page table at level N. There are separate types for each of the 4 levels on 64-bit and 3 levels on 32-bit PAE guests.
Segment descriptor page : Pages used as part of the Global or Local Descriptor tables (GDT/LDT).
Writeable : Page is writable.
漏洞点是在处理大页(SuperPage)时,违反了以上原则,使L1同时处于Writable类型了[40],具体来讲就是修改L2时,快速路径未正确检查新值导致可用它里修改L2的PSE:
// 不允许设置的标志位,可见_PAGE_PSE可设置
base_disallow_mask = ~(_PAGE_PRESENT|_PAGE_RW|_PAGE_USER|_PAGE_ACCESSED|_PAGE_DIRTY|_PAGE_AVAIL);
#define L2_DISALLOW_MASK (base_disallow_mask & ~_PAGE_PSE)
// xen-4.4.0 xen/arch/x86/mm.c
static int mod_l2_entry(l2_pgentry_t *pl2e, l2_pgentry_t nl2e, unsigned long pfn, int preserve_ad, struct vcpu *vcpu)
{
// 检查1: 属于Guest
if ( unlikely(!is_guest_l2_slot(d, type, pgentry_ptr_to_slot(pl2e))) )
{
MEM_LOG("Illegal L2 update attempt in Xen-private area %p", pl2e);
return -EPERM;
}
// 检查2:PDE.P ?= 1
if ( l2e_get_flags(nl2e) & _PAGE_PRESENT )
{
// 检查3:检查nl2e的标志位里保留位 ?= 0,这里可设置PSE
if ( unlikely(l2e_get_flags(nl2e) & L2_DISALLOW_MASK) )
{
MEM_LOG("Bad L2 flags %x", l2e_get_flags(nl2e) & L2_DISALLOW_MASK);
return -EINVAL;
}
// 检查4: ol2e.addr|.P ?= nl2e.addr|.P,需要这两项相等
if ( !l2e_has_changed(ol2e, nl2e, _PAGE_PRESENT) )
{
adjust_guest_l2e(nl2e, d);
// 更新
if ( UPDATE_ENTRY(l2, pl2e, ol2e, nl2e, pfn, vcpu, preserve_ad) )
return 0;
return -EBUSY;
}
检查3放过了PSE导致可以直接在此处更新PS,利用方法可以是如下图,申请pageA的PTE在2M对齐的位置,申请pageB的PTE在pageA之上的2M内,修改pageA的PDE.PS=1,则之前的pageA的PTE位置开始的512个页变成了writable类型的页,但这里面又有属于pageB的PTE的页,因此拥有了修改PTE的权限了,即可访问任意内存:
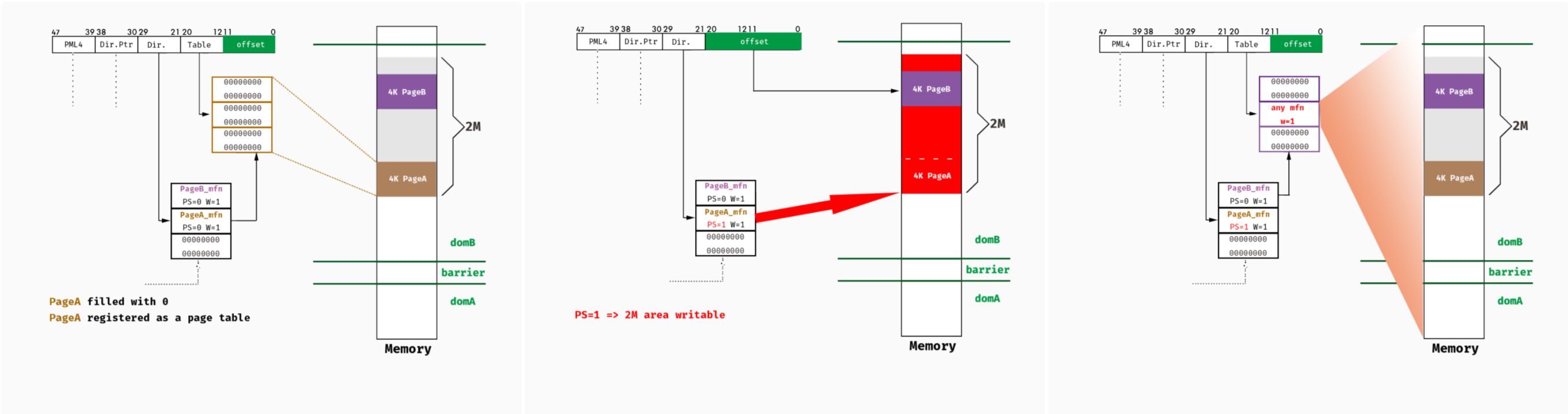
那怎么实施捏?它的超调用可以实现这种分配,也可以用Linux的实现,即用__get_free_pages(__GFP_ZERO, 9)连续分配2M的内存,能访问所有内存后接下来就是逃逸了,如可修改Dom0的内存来实现,详细利用代码可见[41]。
类似的还有XSA-182(CVE-2016-6258)...
Device
设备是问题的重灾区,因为设备多种多样且逻辑复杂,它会通过MMIO/PIO暴露大量的攻击面
BUS
总线:PCI/USB/ISA/SCSI
QEMU:CVE-2011-1751
这个漏洞发生在PIIX4 PM芯片集模拟上,它在接受PCI弹出指令时(写0xAE08端口)未检查其下设备是否支持,像ISA总线就不支持热插拔功能因此相关设备也没有正确实现移除操作,如弹出PCI-ISA桥会释放其下挂的RTC设备,但由于RTC未实现热插拔,在此操作时未正确处理相关数据,从而导致UAF漏洞,补丁如下:
diff --git a/hw/acpi_piix4.c b/hw/acpi_piix4.c
index 96f522233a..6c908ff00b 100644
@@ -471,11 +471,13 @@ static void pciej_write(void *opaque, uint32_t addr, uint32_t val)
QLIST_FOREACH_SAFE(qdev, &bus->children, sibling, next) {
dev = DO_UPCAST(PCIDevice, qdev, qdev);
- if (PCI_SLOT(dev->devfn) == slot) {
+ info = container_of(qdev->info, PCIDeviceInfo, qdev);
+ if (PCI_SLOT(dev->devfn) == slot && !info->no_hotplug) {
qdev_free(qdev);
}
}
具体的说,这里的RTC用RTCState结构表示,其内部有多个计时器QEMUTimer,在初始化时会将计数器注册到QEMU维护的rtc时钟下形成计时器链表,计时器按到期时间排序:
typedef struct RTCState {
ISADevice dev;
...
QEMUTimer *periodic_timer; // periodic timer
int64_t next_second_time; // second update
QEMUTimer *second_timer;
QEMUTimer *second_timer2;
} RTCState;
struct QEMUTimer {
QEMUClock *clock; // 所属时钟
int64_t expire_time; // 纳秒级的到期时间,时钟到达指定时间会调用该计时器的回调函数
int scale;
QEMUTimerCB *cb; // 到期时调用的回调函数
void *opaque; // 回调函数的参数
struct QEMUTimer *next;
};
static int rtc_initfn(ISADevice *dev)
{
RTCState *s = DO_UPCAST(RTCState, dev, dev);
...
// 创建计数器,注意这里的第三个参数,opaque指向RTCState
s->second_timer = qemu_new_timer_ns(rtc_clock, rtc_update_second, s);
s->second_timer2 = qemu_new_timer_ns(rtc_clock, rtc_update_second2, s);
s->next_second_time = qemu_get_clock_ns(rtc_clock) + (get_ticks_per_sec() * 99) / 100;
// 将计数器插入时钟链表里
qemu_mod_timer(s->second_timer2, s->next_second_time);
...
}
从上可见,当释放RTCState时,若没有取下时钟里相应的计数器,则计数器的opaque域将是空悬指针,指向已释放的区域。而插入时钟链表后,主循环会周期性的检查是否到期并调用到期的计时器的回调函数:
main()
=>main_loop()
=>main_loop_wait(nonblocking)
=>qemu_run_all_timers()
=>qemu_run_timers(host_clock) // rtc
static void qemu_run_timers(QEMUClock *clock)
{
current_time = qemu_get_clock_ns(clock);
ptimer_head = &active_timers[clock->type];
for(;;) {
ts = *ptimer_head;
if (!qemu_timer_expired_ns(ts, current_time)) { // 由于是按过期时间排序,未过期则退出循环
break;
}
*ptimer_head = ts->next;
ts->next = NULL;
ts->cb(ts->opaque); // 调用
}
}
上面可见,这里的插入的计时器的回调函数如下,参数指向已被释放的区域:
static void rtc_update_second2(void *opaque)
{
RTCState *s = opaque;
...
s->next_second_time += get_ticks_per_sec();
qemu_mod_timer(s->second_timer, s->next_second_time); // 将second_timer插入时钟的计时器链表中
}
因此若释放RTCState后重新控制它,则能像时钟插入伪造的计时器,即令其指向的second_timer计时器为可控的区域,这样在伪造的计时器到期时则能实现任意的但参数函数调用,具体利用时:
1.伪造一个QEMUTimer,它的cb指向想要劫持的RIP地址,opaque指向参数,next若有需要可指向下一个伪造的计时器实现链式调用,而expire_time为0从而使在下个周期触发
2.弹出PCI-ISA桥,即向0xAE08写2,此时RTCState会被释放
3.分配sizeof(RTCState)大小的区域,重新控制RTCState区域,[29]使用的方法是利用ICMP,向Host发送指定大小内容可控的数据包,Host在处理一个包时为了避免递归会使用malloc分配区域缓存后接收的包,因此控到了RTCState
通过上面的方法可以链式调用一个参数的函数,由于参数1完全可控,可再去找某单参数函数,且该参数是一个结构体指针,通过该方法控制更多参数最终实现任意代码执行。另一个重要的问题是如何获取Host的一些地址,如Guest的映射基址等,这点应该是要信息泄露吧,还不清楚[TODO]....
Disk
QEMU:CVE-2015-3456
这也是逃逸漏洞,又名VENOM(毒液),它是在软盘控制器模拟时判断不当造成的,关于软驱操作可见osdev,下面是具体分析:
static void fdctrl_write (void *opaque, uint32_t reg, uint32_t value)
{
FDCtrl *fdctrl = opaque;
reg &= 7; // 0X3FX&7
switch (reg) {
case FD_REG_FIFO: // FD_REG_FIFO = 0x05
fdctrl_write_data(fdctrl, value);
break;
...
static void fdctrl_write_data(FDCtrl *fdctrl, uint32_t value)
{
/* 检查主状态寄存器,需要处于如下状态:
FD_MSR_RQM: FIFO能交换数据
FD_MSR_DIO: FIFO能读取数据
*/
if (!(fdctrl->msr & FD_MSR_RQM) || (fdctrl->msr & FD_MSR_DIO)) {
return;
}
...
if (fdctrl->data_pos == 0) { // 数据位置为0时,说明开始处理新的命令,value为命令号
pos = command_to_handler[value & 0xff]; // 获取命令handler
fdctrl->data_len = handlers[pos].parameters + 1; // 数据长度为参数个数加一,记下来可看到数据位0为
fdctrl->msr |= FD_MSR_CMDBUSY; // 设置当前主状态寄存器为CMDBUSY状态
}
fdctrl->fifo[fdctrl->data_pos++] = value; // 由于第一次时value为命令号,之后才是参数,因此
if (fdctrl->data_pos == fdctrl->data_len) { // 参数接收完成,开始处理
pos = command_to_handler[fdctrl->fifo[0] & 0xff];
(*handlers[pos].handler)(fdctrl, handlers[pos].direction);
}
}
其中的command_to_handler数组与漏洞点如下:
enum{
FD_CMD_DRIVE_SPECIFICATION_COMMAND = 0x8e
...
};
static const struct {
uint8_t value;
uint8_t mask;
const char* name;
int parameters; // 参数个数
void (*handler)(FDCtrl *fdctrl, int direction); //处理函数
int direction;
} handlers[] = {
...
{ FD_CMD_DRIVE_SPECIFICATION_COMMAND, 0xff, "DRIVE SPECIFICATION COMMAND", 5, fdctrl_handle_drive_specification_command },
...
};
static void fdctrl_handle_drive_specification_command(FDCtrl *fdctrl, int direction)
{
FDrive *cur_drv = get_cur_drv(fdctrl);
if (fdctrl->fifo[fdctrl->data_pos - 1] & 0x80) { // 这里是最后一个参数,Guest可控因此可不满足条件
/* Command parameters done */
if (fdctrl->fifo[fdctrl->data_pos - 1] & 0x40) {
fdctrl->fifo[0] = fdctrl->fifo[1];
fdctrl->fifo[2] = 0;
fdctrl->fifo[3] = 0;
fdctrl_set_fifo(fdctrl, 4); // data_pos = 0;
} else {
fdctrl_reset_fifo(fdctrl); // data_pos = 0; msr &= ~(FD_MSR_CMDBUSY | FD_MSR_DIO);
}
} else if (fdctrl->data_len > 7) { // 这里的判断错误,由上可知参数5个加1应该是不大于6,因此这个地方也进不去
fdctrl_set_fifo(fdctrl, 1);
}
// 于是到这里,fdctrl->data_pos不会被清除,MSR的状态也不会改变
}
已知fifo长度有限,而利用该命令可重复写数据,data_pos会单调递增导致越界,该fdctrl在堆上,[17]在利用时发现堆后面有QEMUBH实例,它里面有函数指针与函数参数(QEMU中有很多这类结构,可以多找找容易被触发的),因此在关闭ASLR时可命令执行逃逸,否则也是要信息泄露吧...
struct QEMUBH {
AioContext *ctx;
QEMUBHFunc *cb;
void *opaque;
QEMUBH *next;
bool scheduled;
bool idle;
bool deleted;
};
QEMU:Scavenger
这是个逃逸漏洞,它位于NVMe上,NVMe是SSD所采用的协议(它底层依然使用PCIe),它使用SQ和CQ分别进行Host向Device传指令/数据与Device向Host传结果,而在传输时它可使用两种方式PRP与SQList,它们都是分散聚集IO,前者是一个地址列表且不指定大小(大小固定,按页,页大小可指定),而后者使用数组加链表的形式它更加灵活,详见蛋蛋读NVMe系列。这个漏洞发生于nvme_map_prp函数,因为它的错误处理处释放的资源可能并未被分配,即free的参数是未初始化的值,于是造成了未初始化释放[2]。
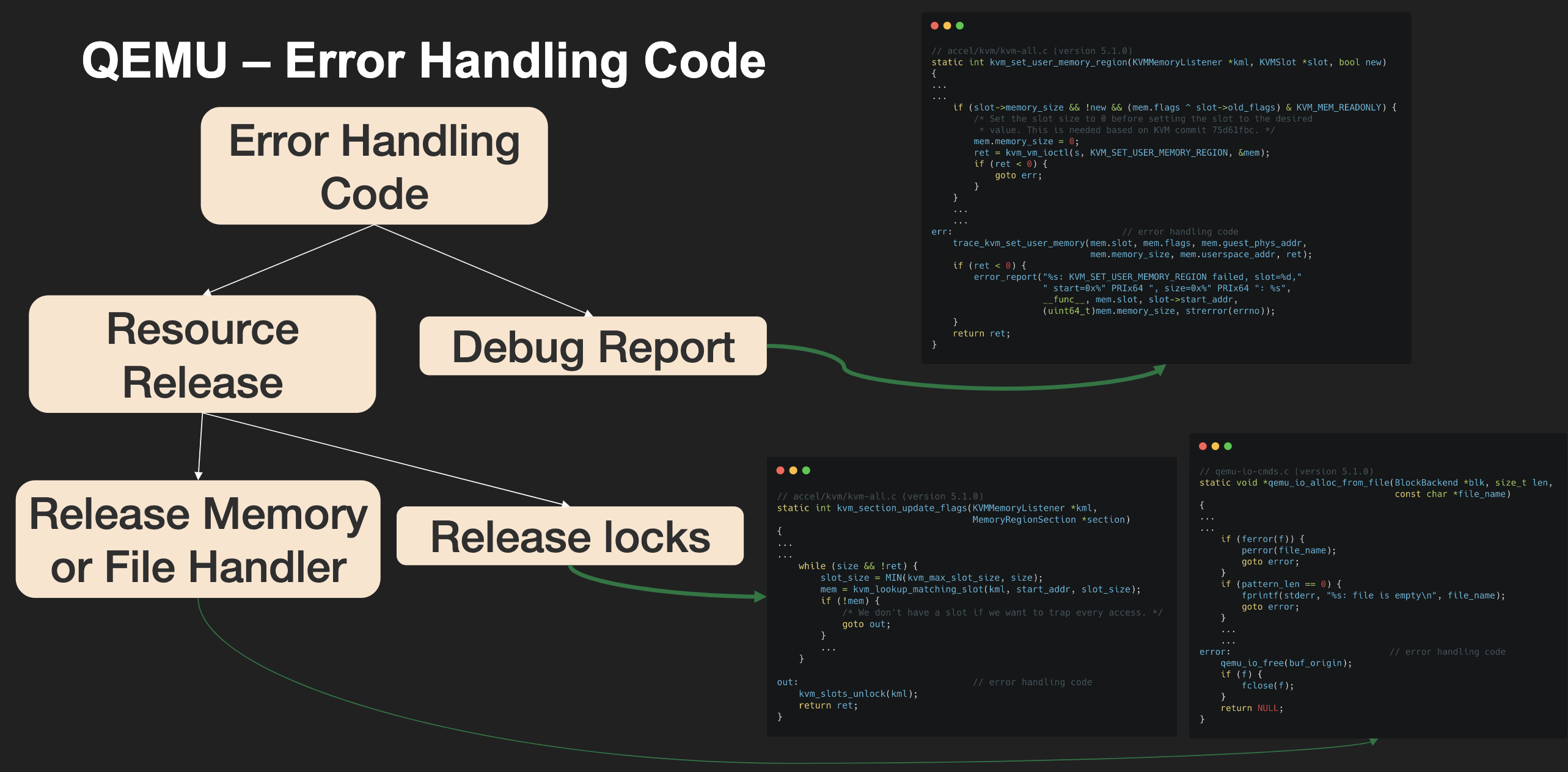
未初始化在要控值时需要根据值的位置找点,如栈上则找同深度其他调用路径看是否能控,而堆上就利用堆风水去控值,作者经分析发现栈上难以控值,于是瞄准了堆,具体的,此时执行流如下:
static void nvme_init_sq(NvmeSQueue *sq, NvmeCtrl *n, uint64_t dma_addr, uint16_t sqid, uint16_t cqid, uint16_t size){
sq->io_req = g_new(NvmeRequest, sq->size); // 此处分配了一些req,具体个数Guest可控,此处没有初始化它
QTAILQ_INIT(&sq->req_list);
for (i = 0; i < sq->size; i++) {
sq->io_req[i].sq = sq;
QTAILQ_INSERT_TAIL(&(sq->req_list), &sq->io_req[i], entry); // 插入列表
}
sq->timer = timer_new_ns(QEMU_CLOCK_VIRTUAL, nvme_process_sq, sq); // 加入定时任务,注意这里还在堆上创建了个QEMUTimer对象
...
}
static void nvme_process_sq(void *opaque){ // 定时处理SQ里的请求
while (!(nvme_sq_empty(sq) || QTAILQ_EMPTY(&sq->req_list))) {
...
status = sq->sqid ? nvme_io_cmd(n, &cmd, req) : nvme_admin_cmd(n, &cmd, req); // 循环从SQ队列里获取命令,并根据类型进行处理
}}
static uint16_t nvme_io_cmd(NvmeCtrl *n, NvmeCmd *cmd, NvmeRequest *req){
switch (cmd->opcode) {
case NVME_CMD_WRITE:
case NVME_CMD_READ:
return nvme_rw(n, ns, cmd, req); // 对读写命令,跟入
}}
static uint16_t nvme_rw(NvmeCtrl *n, NvmeNamespace *ns, NvmeCmd *cmd, NvmeRequest *req){
nvme_map_prp(&req->qsg, &req->iov, prp1, prp2, data_size, n); //继续
}
static uint16_t nvme_map_prp(QEMUSGList *qsg, QEMUIOVector *iov, uint64_t prp1, uint64_t prp2, uint32_t len, NvmeCtrl *n){
if (unlikely(!prp1)) {...} else if (n->bar.cmbsz && prp1 >= n->ctrl_mem.addr && prp1 < n->ctrl_mem.addr + int128_get64(n->ctrl_mem.size)) {
// 若prp1指向控制内存,则使用iov
qsg->nsg = 0;
qemu_iovec_init(iov, num_prps);
qemu_iovec_add(iov, (void *)&n->cmbuf[prp1 - n->ctrl_mem.addr], trans_len);
} else { // 否则使用sgl
pci_dma_sglist_init(qsg, &n->parent_obj, num_prps);
qemu_sglist_add(qsg, prp1, trans_len);
}
len -= trans_len;
if (len) {
if (unlikely(!prp2)) { // prp2为0即可
goto unmap;
unmap:
qemu_sglist_destroy(qsg); // 这里只处理qsg,但若走前一个分支则并没有初始化qsg(至少在该函数内部未初始化)
}
void qemu_sglist_destroy(QEMUSGList *qsg)
{
object_unref(OBJECT(qsg->dev));
g_free(qsg->sg); // 释放了qsg->sg的内存
memset(qsg, 0, sizeof(*qsg));
}
倒着看最后两个函数可见,在走iovec初始化时不会初始化qsg,它的sg指针将是未定义的值,之前提到未初始化一般两种利用方式,信息泄漏或其它位置控值,作者这里就使用后一种方式,当sg可控时就是UAF,跟着流回溯找的是初始SQ处,它可在初始化或重置控制等处触发,在入口处sq->req_list里会插入Guest可控个数的未初始化req,它是从Host堆上分配的,而这里的req里的gsq最终会被传入到漏洞处,堆上可用堆风水控值,这要求能控目标堆分配器的分配(大小可控)与释放以及分配后内容可写,至少要一定程度上满足这种要求,作者最后发现了virtio-gpu提供Guest到Host间的内存映射功能:
static void virtio_gpu_handle_ctrl(VirtIODevice *vdev, VirtQueue *vq){
while (cmd) {
...
QTAILQ_INSERT_TAIL(&g->cmdq, cmd, next);
cmd = virtqueue_pop(vq, sizeof(struct virtio_gpu_ctrl_command));
}
virtio_gpu_process_cmdq(g);
}
void virtio_gpu_process_cmdq(VirtIOGPU *g){
while (!QTAILQ_EMPTY(&g->cmdq)) {
cmd = QTAILQ_FIRST(&g->cmdq);
VIRGL(g, virtio_gpu_virgl_process_cmd, virtio_gpu_simple_process_cmd,
g, cmd); // 展开为 virtio_gpu_simple_process_cmd(g, cmd);
...
}
}
static void virtio_gpu_simple_process_cmd(VirtIOGPU *g, struct virtio_gpu_ctrl_command *cmd){
VIRTIO_GPU_FILL_CMD(cmd->cmd_hdr);
switch (cmd->cmd_hdr.type) {
case VIRTIO_GPU_CMD_RESOURCE_UNREF:
virtio_gpu_resource_unref(g, cmd);
break;
case VIRTIO_GPU_CMD_RESOURCE_ATTACH_BACKING: // 分配
virtio_gpu_resource_attach_backing(g, cmd);
break;
case VIRTIO_GPU_CMD_RESOURCE_DETACH_BACKING: // 释放
virtio_gpu_resource_detach_backing(g, cmd);
break;}
}
static void virtio_gpu_resource_attach_backing(VirtIOGPU *g, struct virtio_gpu_ctrl_command *cmd){
VIRTIO_GPU_FILL_CMD(ab); // 展开为iov_to_buf(cmd->elem.out_sg, cmd->elem.out_num, 0, &ab, sizeof(ab));
res = virtio_gpu_find_resource(g, ab.resource_id);
ret = virtio_gpu_create_mapping_iov(&ab, cmd, &res->iov); // 映射GPA到HVA
}
int virtio_gpu_create_mapping_iov(struct virtio_gpu_resource_attach_backing *ab, struct virtio_gpu_ctrl_command *cmd, struct iovec **iov){
struct virtio_gpu_mem_entry *ents; // 16字节(指针8+长度4+填充4)
esize = sizeof(*ents) * ab->nr_entries; // nr_entries大小可控
ents = g_malloc(esize);
s = iov_to_buf(cmd->elem.out_sg, cmd->elem.out_num, sizeof(*ab), ents, esize);
*iov = g_malloc0(sizeof(struct iovec) * ab->nr_entries); // iov16字节(指针8+大小8)
for (i = 0; i < ab->nr_entries; i++) {
hwaddr len = ents[i].length;
(*iov)[i].iov_len = ents[i].length;
(*iov)[i].iov_base = cpu_physical_memory_map(ents[i].addr, &len, 1); // GPA->HVA
}
g_free(ents); // 申请了两个释放了一个
}
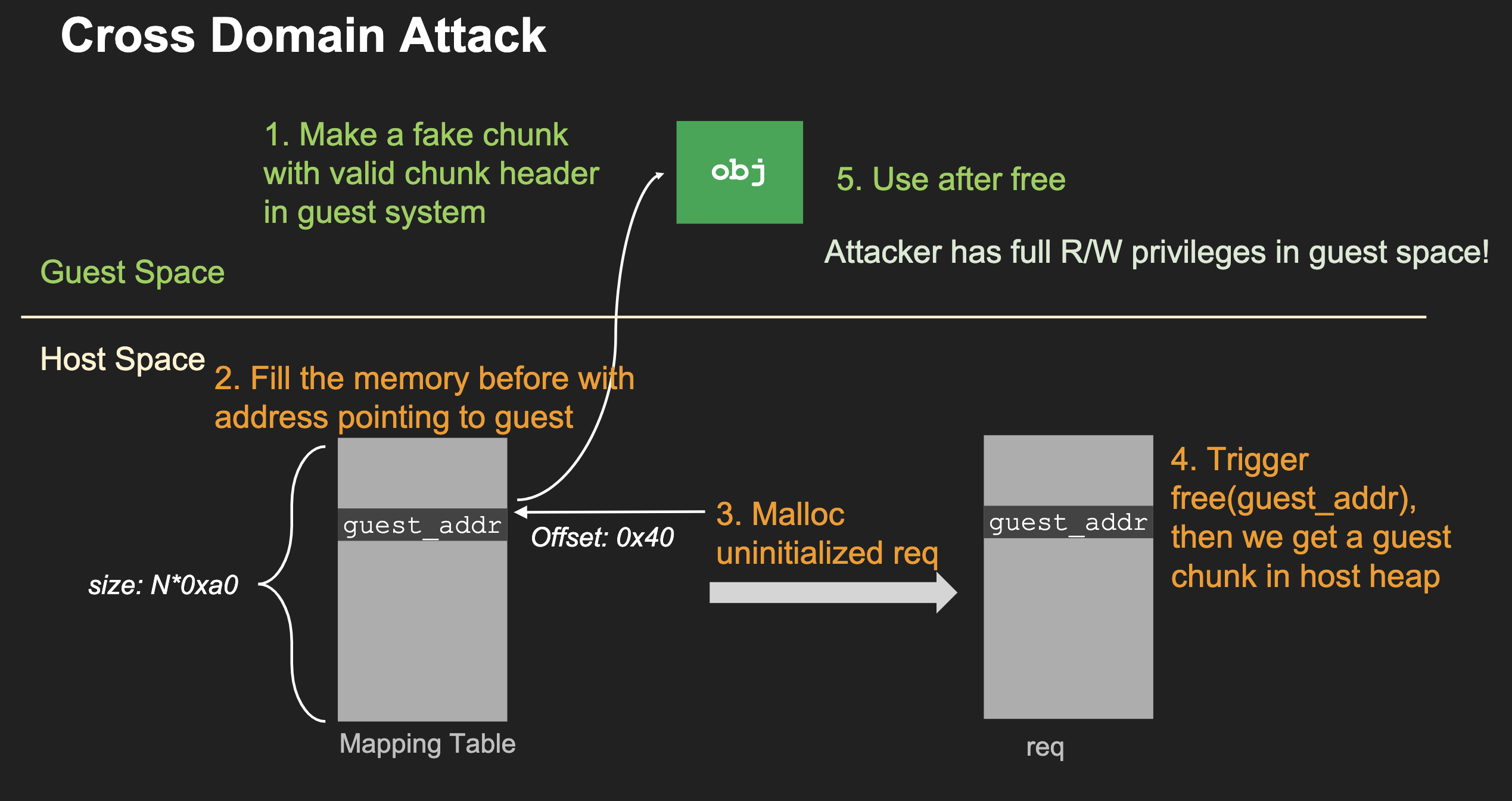
它使用iov去映射多组区域,<1>组数Guest可控于是大小一定程度可控,<2>该映射区域可被Guest请求释放于是可控释放,<3>尽管分配的内存用户不可控但分配的内存满足利用的要求,它的sg偏移处是指针,而且这里完美的,sg指向的区域是Guest可控的区域但指针值是HVA,于是Guest不必知道Host的任何地址信息就能控制释放的内容,这其实是UAF的下一步,现在已经能控制free的区域,但这块区域必须要Guest可读写以满足free校验及后续读写原语,但Guest和Host使用的地址空间并不相同本来是需要信息泄漏的,但这里作者找的点刚好实现了Host与Guest间地址转换,且区域Guest可控,因此UAF完美了,可进行后续利用,首先UAF后Guest读可通过FD指针获取Host堆地址,而此时释放的大小在满足sizeof(struct iovec) * ab->nr_entries大小时可在下次调VIRTIO_GPU_CMD_RESOURCE_ATTACH_BACKING时被用作映射表,此时再读可获取HVA与GPA间的映射关系,而UAF释放的大小满足sizeof(QEMUTimer)大小时,下次调nvme_start_ctrl等可使其成为计时器,它里面cb可泄漏binary的地址,通过写它即可控PC,而PC的一个参数也是可控的,如此时可执行system(calc)...
除了利用思路,这篇文章还提供了挖掘思路,他们分析了QEMU异常处理逻辑并自定义Fuzz去插桩这两种块,思路也很值得学习...
Graphic
QEMU:CVE-2016-3710
这也是个逃逸漏洞,又名DarK Portal(黑暗之门?羞耻),它发生在VGA模拟上,VGA的RAM使用MMIO方式映射到0xA0000开始的最大128K地址空间,但是后来的RAM更大了于是采用Bank-Switching的方式切换映射,可通过图形寄存器来设置,Guest可通过VBE实现该切换,另外VGA默认一次只能传输1字节数据,为了增加带宽添加了锁存器实现一次能传4字节,然而在处理这种读写时没有正确处理索引,造成了经典的索引越界,于是可实现一定范围内的任意读写,具体的请参考VGA标准,这里的读写原理一样,所以看读就好了:
uint32_t vga_mem_readb(VGACommonState *s, hwaddr addr) // 期待读一字节
{
int memory_map_mode, plane;
uint32_t ret;
memory_map_mode = (s->gr[VGA_GFX_MISC] >> 2) & 3; /// 显存映射类型
addr &= 0x1ffff; // 这里限制了偏移最大为 0x1ffff,即128K
switch(memory_map_mode) {
case 0: // 为128K
break;
case 1: // 为64K
if (addr >= 0x10000)
return 0xff;
addr += s->bank_offset; // 最大值为0xffffff=0xffff+0xff0000
break;
...
}
...
} else {
// 注意这里计算时,转换了指针类型,因此可访问到(0xffffff+1)*4=64M的内存,即越界48M
s->latch = ((uint32_t *)s->vram_ptr)[addr];
if (!(s->gr[VGA_GFX_MODE] & 0x08)) { // 读模式为0时,直接返回该平面
/* read mode 0 */
plane = s->gr[VGA_GFX_PLANE_READ]; // 获取要读的平面 0~3
ret = GET_PLANE(s->latch, plane); // 获取这一字节的数据
...
}
return ret;
}
这里的注释涉及到bank_offset,它能由Guest修改,但可修改范围由VRAM控制:
//默认的vga-pci下配置,显存为16M
DEFINE_PROP_UINT32("vgamem_mb", PCIVGAState, vga.vram_size_mb, 16),
s->vram_size_mb = uint_clamp(s->vram_size_mb, 1, 512);
s->vram_size_mb = pow2ceil(s->vram_size_mb);
s->vram_size = s->vram_size_mb << 20;
s->vbe_bank_mask = (s->vram_size >> 16) - 1;
void vbe_ioport_write_data(void *opaque, uint32_t addr, uint32_t val)
{
VGACommonState *s = opaque;
switch(s->vbe_index) {
case VBE_DISPI_INDEX_BANK: // 切换BANK映射
if (s->vbe_regs[VBE_DISPI_INDEX_BPP] == 4) {
val &= (s->vbe_bank_mask >> 2);
} else {
val &= s->vbe_bank_mask; // 这里的掩码为0xff=((16<<20)>>16)-1
}
s->vbe_regs[s->vbe_index] = val;
s->bank_offset = (val << 16); // 最大为0xff0000=(0xff<<16)
vga_update_memory_access(s); // 重新映射
break;
由于是索引导致的越界,该漏洞不必连续溢出因此可越过不可访问区域,[15]提到VRAM之后的48M含如下图内容,包括libc等各种指针与可写区域,因此可通过读绕ASLR并部署shellcode:

类虚拟化协议
VirtualBox:CVE-2018-2698
这是个逃逸漏洞,该漏洞位于VBVA(VirtualBox Video Acceleration)子系统,它利用HGSMI (Host-Guest Shared Memory Interface)实现VGA加速,即Guest分配一片区域作为共享内存(VRAM)实现Guest与Host间快速大批量数据交换,它的VDMA命令有两个子命令未检查Guest指定的数据边界,因此存在任意内存读写:
typedef enum
{
VBOXVDMACMD_TYPE_UNDEFINED = 0,
VBOXVDMACMD_TYPE_DMA_PRESENT_BLT = 1, // 漏洞点1
VBOXVDMACMD_TYPE_DMA_BPB_TRANSFER, // 漏洞点2
...
} VBOXVDMACMD_TYPE;
Gust发送命令后,由Host处理它,由于它们原理一致,这里只选一个分析,如下:
vbvaChannelHandler(void *pvHandler, uint16_t u16ChannelInfo, void *pvBuffer, HGSMISIZE cbBuffer)
=> vboxVDMACommand(pVGAState->pVdma, pCmd, cbBuffer - VBoxSHGSMIBufferHeaderSize());
=> vboxVDMACommandProcess(pVdma, pCmd, cbCmd);
=> vboxVDMACmdExec(pVdma, pvBuf, pCmd->cbBuf);
static int vboxVDMACmdExec(PVBOXVDMAHOST pVdma, const uint8_t *pvBuffer, uint32_t cbBuffer)
{
PVBOXVDMACMD pCmd = (PVBOXVDMACMD)pvBuffer; // 循环处理命令
switch (pCmd->enmType)
{
case VBOXVDMACMD_TYPE_DMA_BPB_TRANSFER:
{
// 获取命令体,它由Guest指定
const PVBOXVDMACMD_DMA_BPB_TRANSFER pTransfer = VBOXVDMACMD_BODY(pCmd, VBOXVDMACMD_DMA_BPB_TRANSFER);
int cbTransfer = vboxVDMACmdExecBpbTransfer(pVdma, pTransfer, cbBuffer);
...
}
static int vboxVDMACmdExecBpbTransfer(PVBOXVDMAHOST pVdma, const PVBOXVDMACMD_DMA_BPB_TRANSFER pTransfer, uint32_t cbBuffer)
{
PVGASTATE pVGAState = pVdma->pVGAState;
uint8_t * pvRam = pVGAState->vram_ptrR3;
uint32_t cbTransfer = pTransfer->cbTransferSize; // 要传输的大小
uint32_t cbTransfered = 0;
do
{
uint32_t cbSubTransfer = cbTransfer;
if (pTransfer->fFlags & VBOXVDMACMD_DMA_BPB_TRANSFER_F_SRC_VRAMOFFSET)
{
pvSrc = pvRam + pTransfer->Src.offVramBuf + cbTransfered; // VRAM基地址固定,偏移Guest指定,因此可指定任意地址
}
...
if (pTransfer->fFlags & VBOXVDMACMD_DMA_BPB_TRANSFER_F_DST_VRAMOFFSET)
{
pvDst = pvRam + pTransfer->Dst.offVramBuf + cbTransfered; // 同上,注意偏移为uint64类型,可溢出到低位
}
...
if (RT_SUCCESS(rc))
{
memcpy(pvDst, pvSrc, cbSubTransfer); // 复制
cbTransfer -= cbSubTransfer;
cbTransfered += cbSubTransfer;
}
} while (cbTransfer);
...
}
由于是共享内存,因此指定不同的源地址偏移与目的地址偏移就可以实现任意内存读写,超好用!现在就是要写哪个内存了,若要绝对地址读写那么首先需要定位到VRAM在Host的地址,VRAM是由Guest分配的其大小已知,[34]的方法是VRAM之后区域是MMIO映射的区域,里面有很多指针,因此透过它能泄露出很多地址:
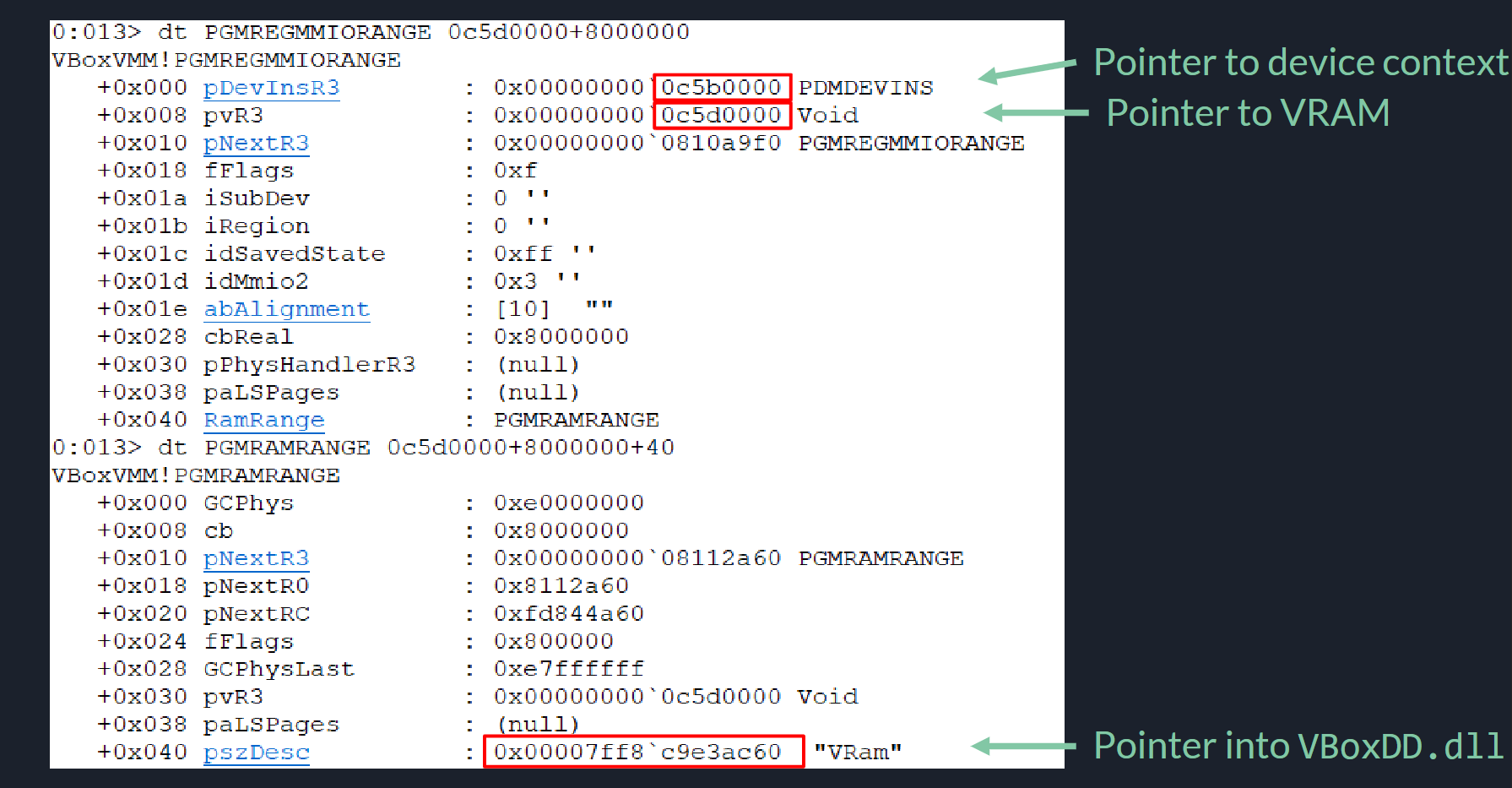
我不熟悉VirtualBox不知道是否一定会有这个,暂时这样理解,有了这些就可以知道 各种地址信息了,再去找个函数指针劫持就行啦。
这个点在Linux下还存在double fetch漏洞,详见CVE-2018-2844...
VMM Service
VirtualBox:S0434934等
这涉及VirtualBox的三个漏洞[9],它们都和文件共享服务相关,Host存在vboxsdl提供该服务,VM通过HGCM与其通信读取文件,S0434934是由于它对路径没有终结符\x00检查,支持Guest指定路径分割符,那么Guest发送无终结符的路径时它将越界,如下:
if (pClient->PathDelimiter != RTPATH_DELIMITER)
{
while (*src) // 会一直遍历下去直到遇到\x00
{
if (*src == pClient->PathDelimiter)
*src = RTPATH_DELIMITER; // 若后面的数据和用户指定的字符一致则修改为"\"符号
src++;
}
这个能操作的东西有限,可能最多造成DoS吧。S0434968就有用了,它可导致目录遍历,它的路径净化算法如下:

看着没啥毛病,但它没有考虑linux与windows对\处理方式的不一致,因此若Host是Linux使,像a\b\c只会是一个目录名但会在计算深度时加3,于是可以用来穿目录。S0434952是未初始化漏洞,使用SHFL_FN_READ读文件时,可指定请求大小,若文件没那么大它并没有清空Buf导致可泄露数据。
注:在共享文件夹下可能还会有软链接的问题,如VirtualBox在启用SharedFoldersEnableSymlinksCreate时,可通过软连接访问其他文件
VirtualBox:S0434947
这个漏洞是Host上的服务导致用户态提权,它的用户态vboxsdl.exe服务和内核态的VMMR0.sys驱动共享struct VM对象,且用户态有RW权限,因此可通过它进行提权,不过由于Linux调试非子进程需要root(CAP_SYS_PTRACE)权限,这个在windows下才好用(TODO:vboxsdl没加固吗,能直接调试?)。
VirtualBox:CVE-2018-2694
这个漏洞是COM组件的漏洞,其他进程可通过该接口控制受保护的进程,该进程拥有访问VBoxDrv的能力,因此可通过它提权,具体漏洞点如下:
#define VMMDEV_CREDENTIALS_SZ_SIZE 128
typedef struct
{
VMMDevRequestHeader header;
uint32_t u32Flags; /** IN/OUT: Request flags. */
char szUserName[VMMDEV_CREDENTIALS_SZ_SIZE]; /** OUT: User name (UTF-8). */
char szPassword[VMMDEV_CREDENTIALS_SZ_SIZE]; /** OUT: Password (UTF-8). */
char szDomain[VMMDEV_CREDENTIALS_SZ_SIZE]; /** OUT: Domain name (UTF-8). */
} VMMDevCredentials;
static DECLCALLBACK(int) vmmdevIPort_SetCredentials(PPDMIVMMDEVPORT pInterface, const char *pszUsername,
const char *pszPassword, const char *pszDomain, uint32_t fFlags)
{
PVMMDEV pThis = RT_FROM_MEMBER(pInterface, VMMDEV, IPort);
if (fFlags & VMMDEV_SETCREDENTIALS_GUESTLOGON)
{
strcpy(pThis->pCredentials->Logon.szUserName, pszUsername); // 缓冲区溢出
strcpy(pThis->pCredentials->Logon.szPassword, pszPassword);
strcpy(pThis->pCredentials->Logon.szDomain, pszDomain);
pThis->pCredentials->Logon.fAllowInteractiveLogon = !(fFlags & VMMDEV_SETCREDENTIALS_NOLOCALLOGON);
}
...
}
攻击者可通过SDK或VBoxManage触发该接口,它在堆上且\x00是坏字符,不过看[34]它后面还刚好有个结构体有函数指针,因此可控RIP...
参考
[1] Escape From The Docker-KVM-QEMU Machine -- Shengping Wang, Xu Liu
[2] Scavenger: Misuse Error Handling Leading To QEMU/KVM Escape [paper] [exp] -- Gaoning Pan, Xingwei Lin (2021)
[3] Attacking a co-hosted VM: A hacker, a hammer and two memory modules -- Medhi Talbi (2017)
[4] qemu-kvm和ESXi虚拟机逃逸实例分享 -- 肖伟 (2020)
[5] Dig into qemu security -- Qiang Li, Zhibin Hu, Mei Wang (2017)
[6] Xenpwn: Breaking Paravirtualized Devices -- Felix Wilhelm (2016)
[7] An EPYC escape: Case-study of a KVM breakout -- Felix Wilhelm (2021)
[8] 3d Red Pill: A Guest-to-Host Escape on QEMU/KVM Virtio Devices -- Zhijian Shao, Jian Weng, Yue Zhang (2020)
[9] Poacher turned gamekeeper: Lessons learned from eight years of breaking hypervisors -- Rafal Wojtczuk (2014)
[10] QEMU/KVM Security Matters -- rafaeldtinoco
[11] QEMU Attack Surface and Security Internals -- Qiang Li, Zhibin Hu (2017)
[12] Stalling Live Migrations on the Cloud -- hmed A, Azeem A, Karim K, Zhiyun Q, Srikanth V, Thomas F (2017)
[13] CAIN: Silently Breaking ASLR in the Cloud [slides] -- Antonio B,Kaveh R,Mathias P,Thomas R (2015)
[14] An awesome toolkit for testing the virtualization system -- Qinghao Tang
[15] QEMU+KVM & XEN Pwn: virtual machine escape from “Dark Portal” -- Wei Xiao & Qinghao Tang
[16] Hypervisor Vulnerability Research - State of the Art -- Alisa Esage (2020)
[17] VENOM漏洞分析与利用 -- 李强
[18] Performant Security Hardening -- Steve Rutherford
[19] FROM RING3 TO RING0: EXPLOITING THE XEN X86 INSTRUCTION EMULATOR -- Andrei Vlad Luțaș (2016)
[20] Ventures into Hyper-V - Fuzzing hypercalls -- Alisa Esage
[21] When virtualization encounters AFL [slide] -- Jack Tang, Moony Li
[22] 基于虚拟化内存隔离的Rowhammer 攻击防护机制 -- 石培涛, 刘宇涛, 陈海波
[23] A Dive into Hyper-V Architecture and Vulnerabilities -- Nicolas Joly, Joe Bialek (2018)
[24] Attacking hypervisors through hardware emulation -- Oleksandr Bazhaniuk, Mikhail Gorobets, Andrew Furtak, Yuriy Bulygin
[25] Attacking Hypervisors via Firmware and Hardware -- Mikhail Gorobets, Oleksandr Bazhaniuk, Alex Matrosov, Andrew Furtak, Yuriy Bulygin (2015)
[26] Ouroboros: Tearing Xen Hypervisor With the Snake -- Shangcong Luan (2016)
[27] Hardening Hyper-V through offensive security research -- Jordan Rabet (2018)
[28] Growing Hypervisor 0day with Hyperseed -- Daniel King, Shawn Denbow (2019)
[29] Virtunoid: Breaking out of KVM -- Nelson Elhage (2011)
[30] Virtualisation security and the Intel privilege model -- Tavis Ormandy, Julien Tinnes (2010)
[31] CLOUDBURSTA:VMware Guest to Host Escape Story -- Kostya Kortchinsky (2009)
[32] THE GREAT ESCAPES OF VMWARE: A RETROSPECTIVE CASE STUDY OF VMWARE GUEST-TO-HOST ESCAPE VULNERABILITIES -- Debasish Mandal & Yakun Zhang (2017)
[33] Out of the Truman Show: VM Escape in VMware Gracefully -- Lei Shi & Mei Wang (2017)
[34] Unboxing your VirtualBoxes: A close look at a desktop hypervisor -- Niklas Baumstark
[35] CORE SECURITY: Breaking Out of VirtualBox through 3D Acceleration -- Francisco Falcon (2014)
[36] Subverting the Xen hypervisor -- Rafał Wojtczuk (2008)
[38] Preventing and Detecting Xen Hypervisor Subversions -- Joanna Rutkowska & Rafał Wojtczuk (2008)
[39] Bluepilling the Xen Hypervisor -- Joanna Rutkowska & Alexander Tereshkin (2008)
[40] Advanced Exploitation:Xen Hypervisor VM Escape [paper] -- Shangcong Luan (2016)
[41] Xen exploitation part 2: XSA-148, from guest to host -- Jérémie Boutoille (2016)