设备模拟
在设备(如IOT)漏洞挖掘过程中,特别是挖掘二进制漏洞时少不了设备模拟,通过Dump/Download固件并模拟的方式,能避免损坏设备或无意义的设备购买开销,另外模拟环境可以为固件分析提供如快照/调试等便利,关于设备模拟可见之前网络设备漏洞挖掘的文章。
场景
CPU(ISA)模拟
即运行其他支持的平台上的程序,如在X86上运行ARM/MIPS程序。
外设模拟
在分析某些固件时,它需要特殊的外设,此时就可以通过QEMU去模拟这种设备。在研究设备模拟时,还发现了个有意思的ECOM,它通过二进制重写直接向设备里植入通用驱动...
指令加速
原始设备硬件限制导致的速度较慢,不能满足某些场景的需求(如Fuzz),而使用更高性能的机器运行相应固件能得到更好的性能,同架构甚至能获取接近本机的性能,[1]演示了如何在树莓派上使用QEMU+KVM启动IOS
FUZZ
现在的漏洞挖掘中,Fuzz占据了相当重要的地位,但在Fuzz时却不得不面临一些挑战:
1.不方便Fuzz:这有两方面,一个是不便进行交互(如驱动程序),一个是不便获取反馈,反馈有利于获取高质量(如高覆盖率)的样本
2.速度问题:速度直接决定了发现漏洞所需时间,Fuzzer改进工作的一个重点就是提高Fuzz速度。
3.有状态的I/O:如协议类的Fuzz大多都是有状态的,依照它的协议才能产生好的测试样本。
显然虚拟机可以方便的实现交互,自动化的恢复环境(包括出现致命错误),实现对底层应用进行Fuzz,于是再看看反馈,即在程序执行到关键位置(如代码块入口)时进行记录,传统的要获取与控制程序状态,有两种方式,调试与插桩:
1.调试依赖于操作系统提供的接口(OpenProcess/ptrace),通过该接口另一个进程拥有访问与控制另一个进程寄存器与内存的能力,一方面它可能会和程序本身的功能冲突或遭遇反调试,另一方面调试涉及多个上下文切换与进程间通信开销很大。
2.插桩是将我们的控制逻辑直接植入目标的上下文,其实现方法根据作用时机分为静态插桩与动态插桩,根据有无源码分为源码插桩与二进制插桩,由于遇到的大多是二进制无源程序,此时只能采用二进制重写与动态的插桩:
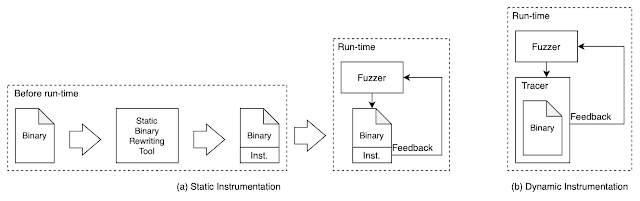
在引入虚拟化后,新增了基于仿真/虚拟的方式,前者如解释执行与二进制翻译都能在执行过程中精确的获取,而后者可使用虚拟机内省技术获取任意数据(详见下一节),而且传统的插桩/调试在复杂场景很可能会出现各种奇怪的问题但VMI不会遇到这类问题(那一类呢?)。
再看速度与状态问题,它们都能依据快照机制得到提升,快照可以把某个时间点的所有信息记录下来,包括内存与寄存器等信息,通过一些努力,之后能完全恢复之前的执行,另外利用脏页/写时复制机制可以实现快照快速恢复。它特别适合运用于初始化时间过长的重型应用,或者逻辑靠后的位置,使用快照可以直接从任何一个合适的位置执行程序并开始Fuzz(不依赖源代码),并在合适的位置停止执行再恢复环境,重复这个过程:

除了精确Fuzz带来的速度提升,快照还有利于Crash的复现,由于快照保存了每次的初始状态,它能排除更多的干扰使复现更容易。最后就是有状态Fuzz,对此通常的做法是为Fuzz添加状态功能,如使用状态机,但这种机制显著增加了实现难度,而利用快照能记录每个状态的特点,也可以从对应状态开始Fuzz,降低实现难度。
除此之外,基于虚拟机的Fuzz还能利用很多机制进行优化,如:
1.KSM(Kernel same-page Merging)通过避免内存重复,允许相同或相似的客户操作系统拥有更高的客户密度。使内核能够检查两个或多个已经运行的程序并比较它们的内存。如果任何内存区域或页面相同,KSM 会将多个相同的内存页面缩减为一个页面。然后将此页面标记为写入时复制。减少了 KVM 来宾的缓存未命中,从而可以提高某些应用程序和操作系统的性能。
2.THP(Transparent huge pages)通过将空闲的大页内存用作缓存提高性能
3.利用QCOW2的写时复制和快照(overlay files)功能节省磁盘空间
4.....
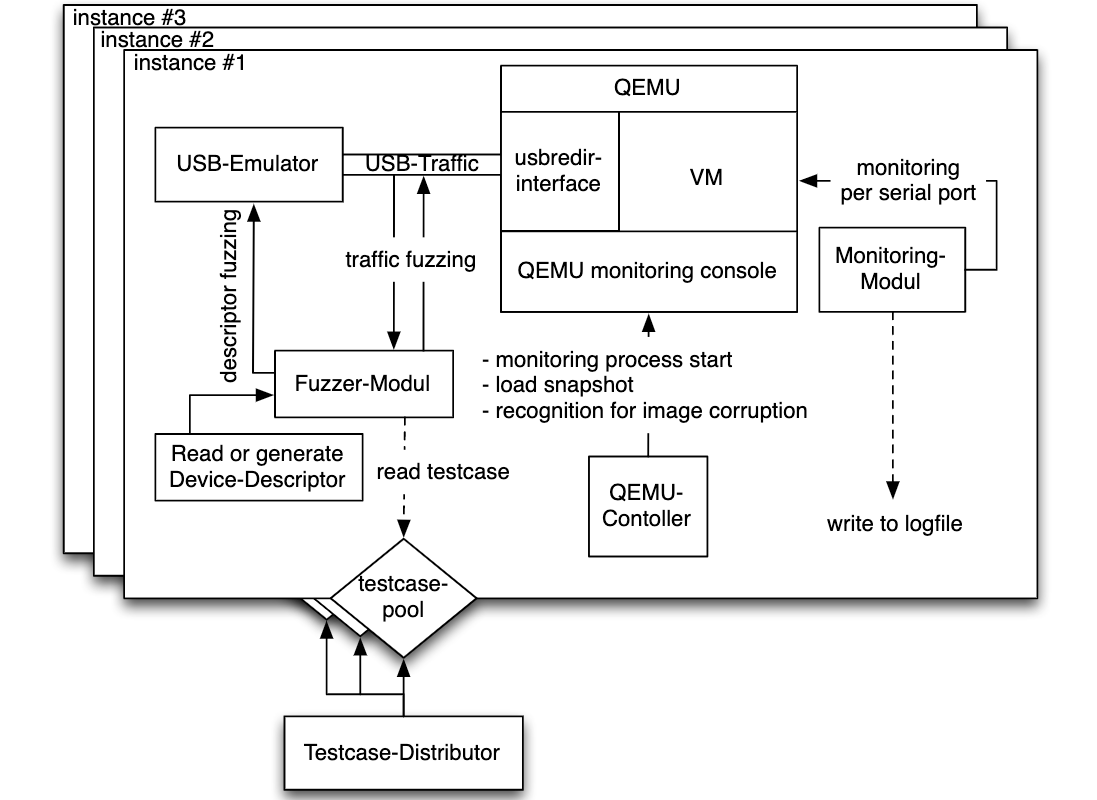
样例的话可看看Sergej等人基于QEMU+KVM构建的USB Fuzz框架^[6],通过它来查找USB设备的漏洞,其架构如下图:
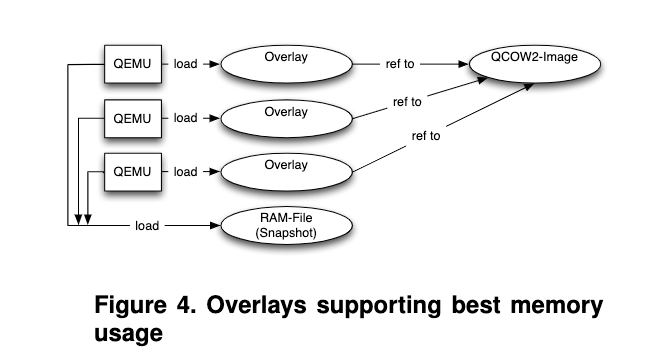
为了提高Fuzz的效率,作者选用了多进程与集群的方式,为了节省磁盘空间提升访问速度他们选用了QCOW2,如下:
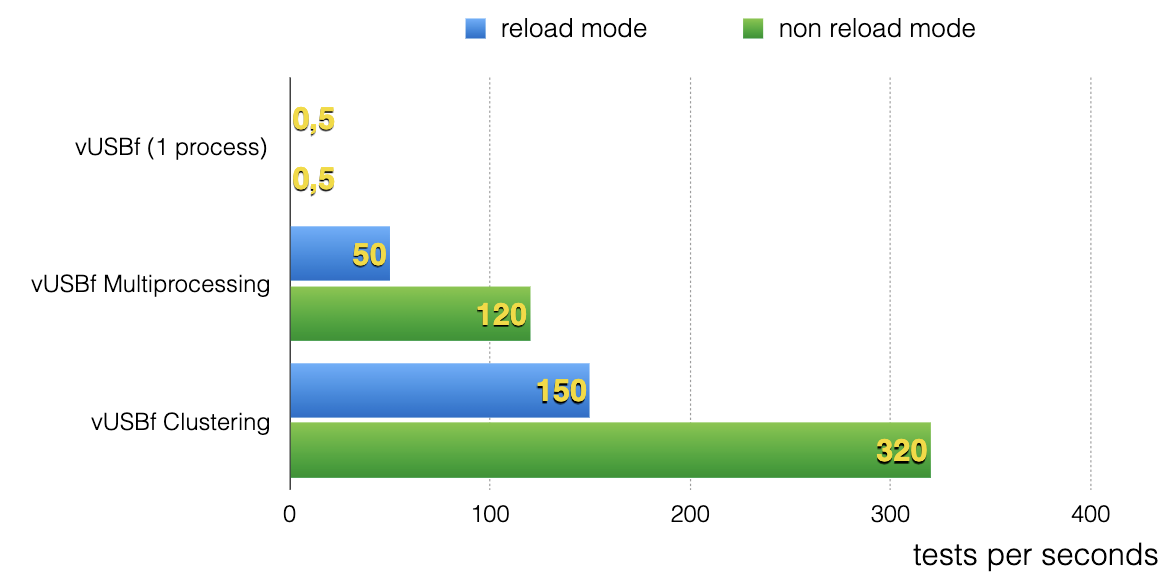
在Fuzz时,他们并没有对目标驱动进行插桩,因此出现的漏洞可能被延迟触发,作者提供了两种环境重置选项,它们都是基于快照的,reload模式会在每次测试后重新加载快照,而non reload模式会在最后系统出现错误时再加载快照,后者效率更高且更容易获取延迟触发的漏洞,但复现更加复杂,不过快照以及ID记录会为复现提供便利,可见效率还是阔以滴:
另一个样例见h0mbre的文章^[5],还有个工具ApplePie可以康康...
小节参考
[1] Accelerating iOS on QEMU with hardware virtualization (KVM) -- (2020)
[2] Wednesday, November 10, 2021 ARMored CoreSight: Towards Efficient Binary-only Fuzzing -- Akira Moroo ,Yuichi Sugiyama (2021)
[3] Fuzzing Modern UDP Game Protocols With Snapshot-based Fuzzers -- Markus Gaasedelen
[4] Building a new snapshot fuzzer & fuzzing IDA [src: wtf] -- Axel (2021)
[5] Fuzzing Like A Caveman 4: Snapshot/Code Coverage Fuzzer! -- h0mbre
[6] Don’t trust your USB! How to find bugs in USB device drivers [slide] [src] -- Sergej Schumilo, Ralf Spenneberg (2014)
[7] Hello Rewind, meet world -- Damien Aumaitre (2021)
虚拟机内省
VMI(Virtual Machine Introspection)是一种监控VM运行时状态的技术,可被用于调试,取证分析等情景,简单来说,它使VMM有能力掌控VM的所有行为,获取VM运行时的所有数据。VMI可不必依赖操作系统提供的调试机制,可不侵入Guest系统,也可以屏蔽掉底层硬件暴露的调试信息(单步标志/DR信息),对Guest来说它完全处于一个上帝模式,这具有完美的隐蔽性(时间差异可能暴露VMM存在)。
场景
下面的三个场景各有交叉,此处是根据是否允许侵入(隐蔽需求),是否允许交互(调试需求)与是否强依赖内核数据结构来分类的。
系统与软件加固
内核0Day和APT会使传统防御变得不可靠,如下,由于系统和安全软件(如AV)缺乏隔离,进入ring0后可控制整个系统使安全软件失效:
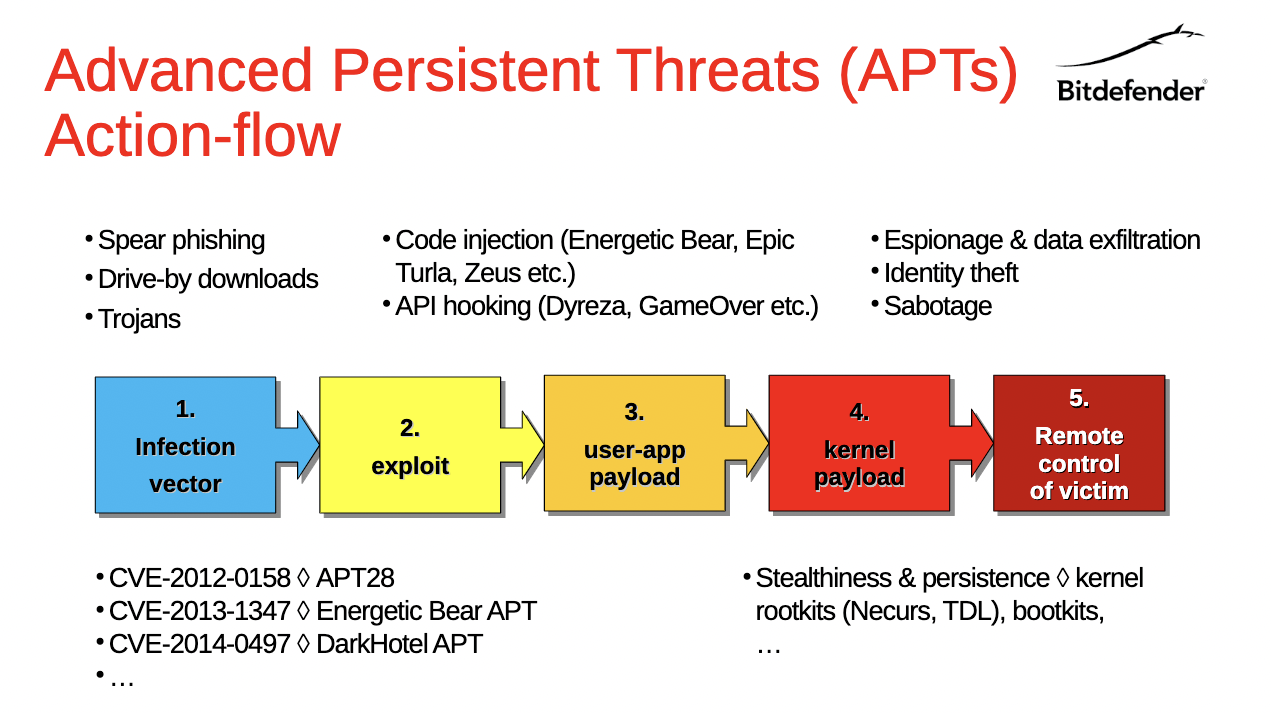
另外内核非常复杂,用户程序同样如此,漏洞会破坏整个系统,加固是个复杂的过程,而使用VMI能更好的隔离,它不依赖于Guest OS,在与Guest交互时只使用最少的接口(TCB足够小)^[18, 21, 22]:

因此能被用于系统加固,防御未知攻击,这里以完整性保护举例,恶意程序在获取ring0权限后为了隐藏自己可能会修改内核或安全程序,它可以直接修改页表为其赋予写权限并修改对应页内容,而使用EPT为关键数据施加写保护后,由于在非根模式,即使有ring0权限恶意程序无法修改受保护页的数据:
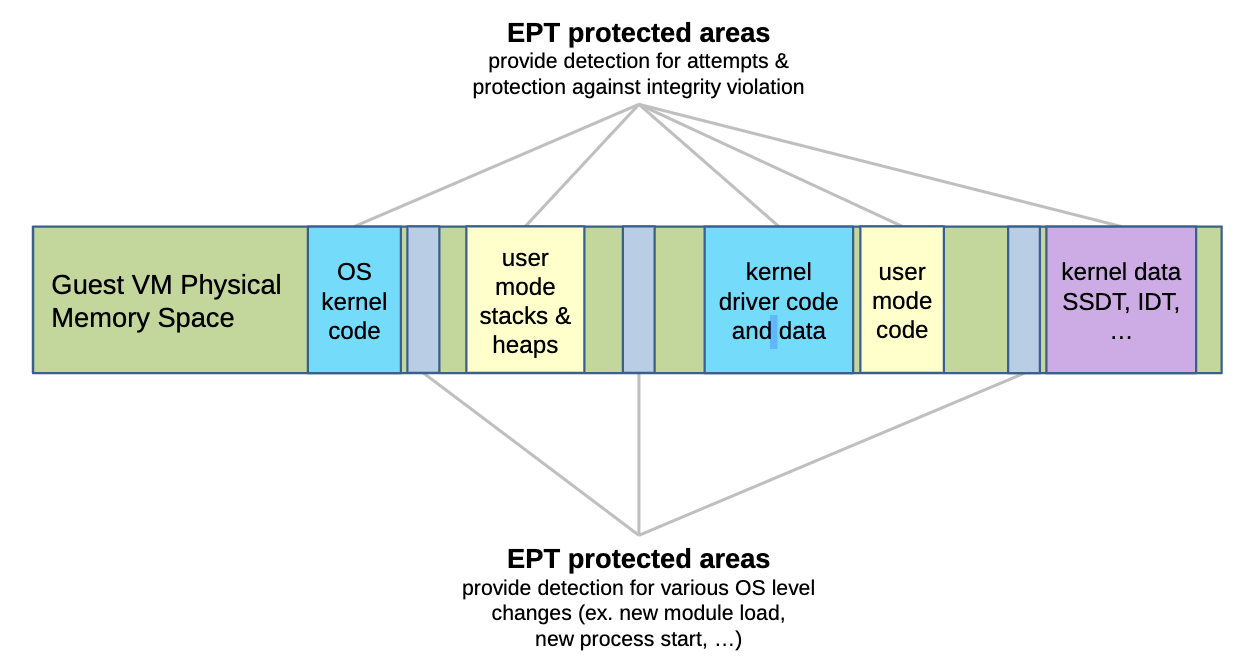
另外完整性保护能让其内部的客户端工具持续生效,再通过内部的Agent加速,Virtualization Exception(#VE)可以让EPT violation由Guest处理,此时就没有VMM退出,从而可提高性能。其实做这方面的安全都是在往更底层走,拿更高的权限,Windows已经开始直接把常规系统放在Guest里,而直接使用Hyper-V占据根0权限[24]。
动态程序分析
还(hài)记得读书时安恒的大师傅给我们分享用虚拟机分析恶意软件,他提到隔离与快照,印象很深的就是快照,它能在分析到某些点时创建内存快照,之后快速回到存档点继续分析。此处主要介绍它的另一种用法,由于它的隐蔽性,它可很好的对抗反调试,建立高隐蔽蜜罐,也可以用于恶意软件分析。在反调试时,一般有三种思路:
1.检测自身调试状态:硬件状态(RFLAGS.TF/DR),时间,调试接口(BeingDebugged),内存状态(int3/系统特性的调试标志,如堆初始化)
2.检测外部异常环境:进程名/进程内存/驱动符号/窗口名/硬件信息/网络连接与端口...
3.对抗调试器:调试隐藏,双子进程,异常捕获...
注:反调试的思路就两种,检测是否被调试与直接阻止自己被调试,但在具体实现上完全依赖系统特性,反调试技术本身保护能力有限(可去除且不影响分析),但需要不断研究总结各种小trick,这网上很多总结,如AntiDebuggers...
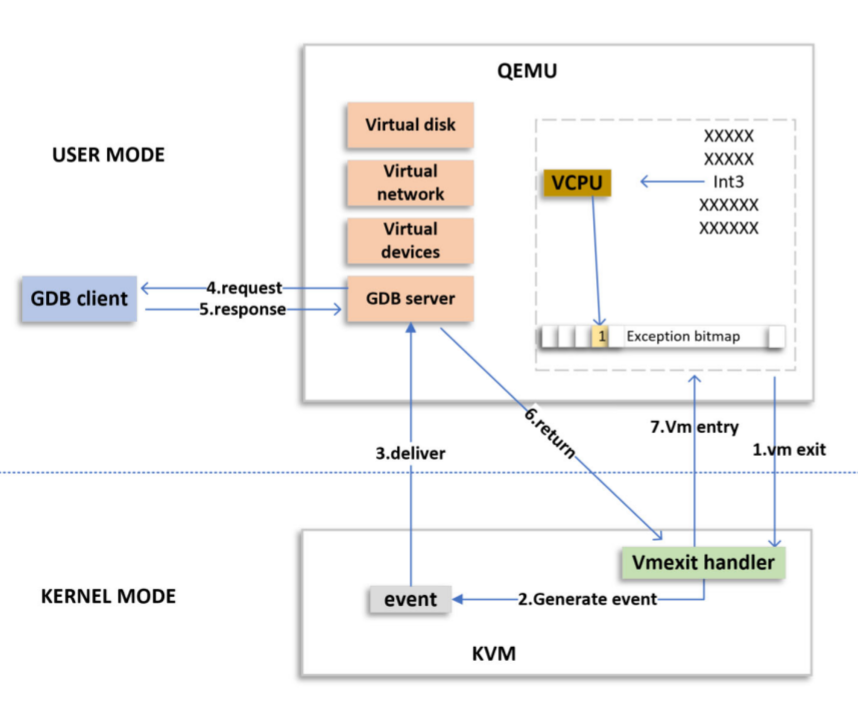
显然,虚拟化是天然的抗这些反调试,如下是QEMU的调试架构,它将GDBStub桥接到VM-exit处理上,从而使用户可使用GDB客户端进行调试:
如下是Pavel D等人基于QEMU实现的VMI^[14]的架构图:

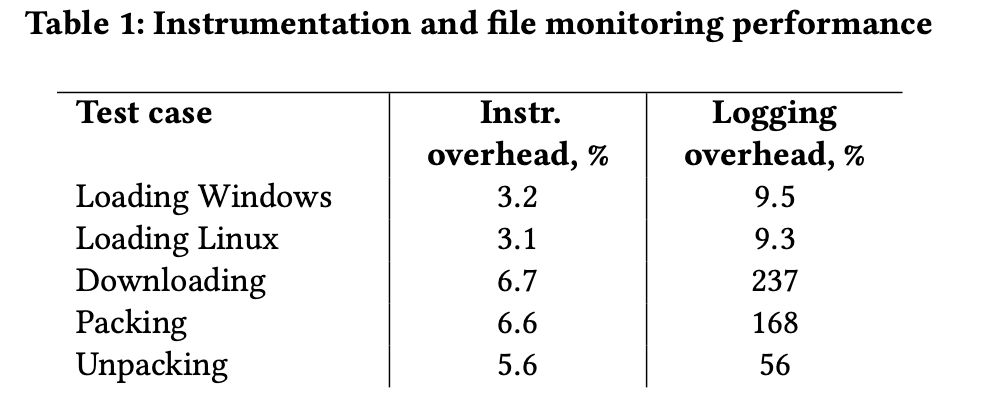
它在底层有三个模块,首先看System call detector,由于系统调用ABI比较稳定且数量不多(200多个),几乎所有的VMI都实现该功能,剩下的Context detector是根据CR3切换/中断事件等探测的,需要用它匹配事件所属进程,而File system parser依赖于磁盘镜像与QEMU,前者作为基础,后者也是根踪系统调用实现的。想想strace和ltrace,现在strace的syscall跟踪很容易实现了,ltrace的动态库调用,则需要解析对应的可执行文件格式,并在入口处打断点。就性能来看,损耗还是比较低,记录的损耗主要是在大量数据传输上:
使用VMI进行分析还有个好处,就是能轻松的获取程序的行为,详见下一节。这方面开源的推荐看看KVM-VMI,DRAKVUF:
商业化产品可见JoeSandboxHypervisor,它被设计专用于恶意软件分析:

入侵检测与威胁猎捕(蜜罐)
这类工具主要用于监控系统执行行为,发现已知或未知威胁行为,相较于调试工具,它们少了交互与修改的功能。HIDS或其他的检测工具依赖于系统提供的功能或与系统处于同级地位,当系统被破坏时(系统调用表HOOK或者直接修改内核数据结构的RootKit),这些工具将直接失效,基于虚拟机的安全检测工具则能防御这类恶意程序,Garfinkel T&Rosenblum M^[1]在提出VMI时也是用于这种场景,借助VMM的如下能力:
1.隔离(isolation):威胁只会被限制在某个Guest OS里,即使IDS未成功识别/拦截攻击,Guest OS已经受到破坏也不会影响Host及其他Guest。
2.监视(inspection):能监视Guest OS的所有状态与事件,恶意程序无法隐藏自己。
3.介入(interposition):在Guest触发某行为时VMM可介入,对其进行模拟,也可根据安全策略对其进行阻止/记录/报警等
他们提出了VMI-based IDS,其架构如下图:

它通过三种操作命令实现了
1.INSPECTION COMMANDS:直接检查VM状态,如获取内存/寄存器内容,I/O设备的信息等
2.MONITOR COMMANDS:监听特定的事件,如发生中断/特殊内存访问时/设备状态改变时发送相应的通知
3.ADMINISTRATIVE COMMANDS:直接控制VM的行为,如暂停/恢复/快照/重启等
也有一些商用产品,如比特梵德的Bitdefender Hypervisor Introspection,思杰的Direct Inspect APIs。
相较与HIDS,蜜罐本身就需要虚拟化部署,因为攻击者很可能获取系统最高权限,此时Guest OS内的探测程序将可能被攻击者破坏,而基于VMI的依旧可用。在部署蜜罐时,另一点尤为重要,就是隐蔽VMM,Tamas K^[16]对此进行了说明并提出了一些反反虚拟机的点,简单来说可能暴露的面有:
1.使用类虚拟化技术,此时会有一些虚拟机增强工具(如vmtoolsd.exe),一些虚拟外设(如VMware Accelerated Nic)等
2.虚拟化环境异常,如只有单处理器(为了实现方便,避免解决条件竞争问题会采用单处理器),内存或磁盘过小,用户名,文件元信息异常,屏幕分辨率异常等
3.虚拟化硬件信息异常,如虚拟化的CPU特性不符(如CPUID.EAX=0时,ECX的bit31总应该为0),硬件信息带虚拟化字段(如CPUID返回的处理器信息,PCIe的外设厂商字段)
4.虚拟化时间异常,这包含虚拟机换出后的时间同步机制,执行某些操作期待花费的时间,快照或暂停后的tick数,多渠道获取的计时不一致等
更多检测规则可查看antidebug_antivm,也可参考pafish所使用的虚拟机检测技术,针对性的去除这些信息就能达到隐身的目的。
对于蜜罐,可以参考Xuxian Jiang^[2]等人的文章,它们借助QEMU的二进制翻译回调实现了事件监听,主要监视系统调用事件,它本身实现及其简单并依赖于内核数据结构(struct thread_union )实现进程识别,易受攻击的影响但可参考下思路,这类工具也可用于快速识别程序行为。
反向审查
作为一个用户,在使用如云服务商提供的虚拟机时,可能会担心VMM利用它的特权滥用审查,此时可通过一些手段获知VMM做了哪些审查,当然对于恶意软件也可以通过这些方式检测虚拟机的存在。
尽管从效果上看,虚拟机能完全隐藏自己,但是它无法完美的隐藏时间上的差距,虽然理论上讲它能控制每一个时间源,但是时间源太多了,有些并不容易控制,如修改HPET容易导致多媒体播放异常,加密的网络时间协议需要先解密(解密可看Benjamin T的论文^[14])等...Tomasz T等人提出了一些列通过测信道推测是否处于虚拟机中以及VMI会监视哪些行为的方法^[17],他们首先找了两种时间基准,一种是HPET,另一种是并发执行,提一下后者,它是要检测的指令放一个线程里循环,NOP指令放另一个线程里循环,记录前者执行时后者循环的次数(循环多次是为了让结果更平滑),这样用NOP作为基准就能获取目标指令执行效率了(从性能上看拦截NOP指令不现实),他们用这两种方法对比了退出与否的时间消耗,如下:
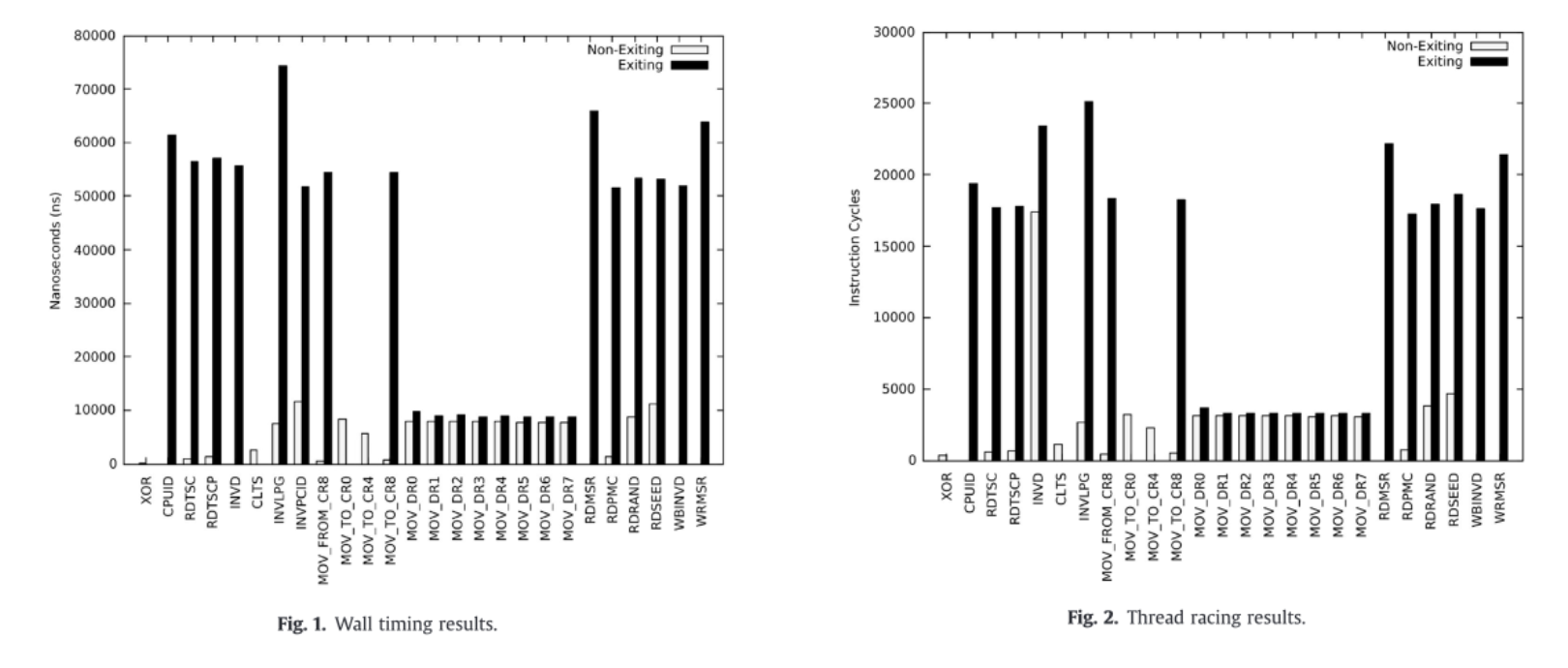
可见这种差异是比较明显的,因此能用这种方法推测VMM做了哪些监视,如拦截了哪些指令,对哪些指令做了特别多的操作,操作了哪些内存(这还利用了缓存间的速度差异),详见论文。
关于VMI,也有一些实现开源实现了,可参考DECAF,PyReBox,LibVMI,XEN VMI...
审查原语
所谓审查方式就是如何监控到VM的特定行为,当VM触发特定行为时使其退出,从而在VMM中对其执行一些审查操作。在基于软件完全虚拟化时,VM的整个运行过程都是由VMM定义的,因此只需要在对应位置插入相关逻辑即可,但它容易出错且效率低难以用于生产环境,此处主要讨论基于硬件辅助的虚拟化,毕竟硬件快嘛,很多时候我们要快!可此时就只能使用硬件提供的功能了,其中很多行为硬件以提供选项我们可以直接设置,其他特别的功能可能就需要迂回实现,这里依然只关注Intel VT。
上篇已经提到,导致虚拟机退出的原因只有执行指令或发生中断,它们都会导致某种状态的改变,这里记录下这些可监视的点与监视方式。
注:VM退出是一个开销很大的行为,要避免不必要的以及频繁的退出
特殊寄存器访问
访问通用寄存器的行为忒普通了无法进行针对性拦截,也没拦截的意义,这里只关注特殊寄存器
| 寄存器 | 说明 |
|---|---|
| CR3/CR8 | CR3(8)-load(store) exiting为1时,读(写)操作退出,对于CR3的写操作还与CR3-target value设置有关,这时写指定值不退出。 |
| CR0/CR4 | 读不退出,根据mask位与shadow决定是否退出,Mask为0则不退出,否则写的值和shadow不一致时退出 。另外LMSW在写CR0低4位时,若bit0原来mask为1,shadow为0且写1则退出,bit3:1的mask为1,且shadow和要写的值不一致时则退出 |
| MSR | 在未使用MSR bitmap时或索引不在0~0x1FFF与0xC0000000~0xC0001FFF间的所有读写操作直接退出,使用时MSR bitmap时,对应的读写位控制是否退出 |
| DR | MOV-DR exiting为1时用MOV指令读写DR会退出 |
| PMC | RDPMC exiting为1时执行RDPMC退出 |
| TSC | RDTSC exiting为1时执行RDTSC退出,,若同时在enable RDTSCP时执行RDTSCP退出,若同时设置了enable user wait and pause则在执行TPAUSE/UMWAIT时退出 |
| GDT/IDT/LDT/TR | 设置了descriptor-table exiting时退出 |
| XCR0 | 在XSETBV时写操作时退出 |
特殊操作
| 审查点 | 说明 |
|---|---|
| 任务切换 | 本身不支持基于硬件的任务切换,对这种情况会直接退出;对于软件实现的情况,需要根据CR3来检测 |
| 虚拟化操作 | INVEPT/INVVPID/VMCLEAR/VMLAUNCH/VMPTRLD/VMPTRST/VMRESUME/VMXOFF/VMXON是无条件退出的,在不使用shadow VMCS时VMREAD/WMWRITE会直接退出,VMFUNC在未启用VM-function时退出 |
| 获取CPU特性 | CPUID无条件退出 |
| I/O操作 | unconditional I/O exiting为1且use I/O bitmap为0时直接退出,否则根据I/O bitmap设置决定是否退出,IN/INS/INSB/INSW/INSD/OUT/OUTS/OUTSB/OUTSW/OUTSD受控 |
| CPU挂起 | HLT exiting为1时退出 |
| SMX操作 | 在CR4.SMXE[Bit14]置位时,GETSEC将直接退出,否则抛出#UD异常 |
| SGX操作 | 设置了ENCLS exiting时,执行ENCLS时若ENCLS-exiting对应位置位则退出,若无对应位(大于63)则63置位则退出,执行ENCLS同理。 |
| CLTS | CR0.TS在CR0 guest/host mask与CR0 read shadow都被置位时 |
| KeyLocker操作 | 若设置了LOADIWKEY exiting,则执行LOADIWKEY获取AES密钥会退出 |
| 监视器操作 | 设置了Monitor exiting时执行MONITOR则退出,设置了MWAIT exiting时执行MWAIT会退出(唔,这个不适合用于通常的内存访问监控) |
| 自旋等待循环 | 和CPL有关,在CPL>0时,设置了PAUSE exiting则执行PAUSE时退出。在CPL=0时,设置了PAUSE exiting则执行会退出,否则还会根据PAUSE-loop exiting来判断 |
| 缓存操作 | INVD无条件退出,INVLPG/INVPCID设置了对应项则退出,设置了WBINVD exiting时执行WBINVD/WBNOINVD退出 |
| 处理器扩展状态 | XRSTORS/XSAVE |
| VMCS操作 | 使用VMREAD/VMWRITE指令时,未使用VMCS shadowing或源操作数违规(63:15或31:15非0)或对应的bitmap为1则退出,否则操作VMCS-link pointer |
| 随机数操作 | 设置了RDRAND exiting时执行RDRAND退出,设置了RDSEED exiting时执行RDSEED时退出 |
| 特权扩展状态操作 | 设置了enable XSAVES/XRSTORS时,在执行XRSTORS/XSAVES时若EDX:EAX&IA32_XSS&XSS-exiting bitmap为1则退出 |
特殊事件
| 审查点 | 方式 |
|---|---|
| Exception(异常号在0~32) | 由exception bitmap决定,对应位为1则退出 |
| External Interrupts | 若处于wait-for-SIPI或shutdown时会阻塞,否则设置了external-interrupt exiting时退出(emmm,还看APIC虚拟化设置,见上一篇),未设置则有Guest-IDT分发 |
| Triple Fault | 退出 |
| NMIs | 若处于wait-for-SIPI时会阻塞,否则设置了NMI exiting则退出,未设置则根据Guest-IDT分发 |
| INIT signals | 若处于wait-for-SIPI时会阻塞,否则会退出,这种退出不会执行任何操作(不修改寄存器状态或清除pending的事件) |
| SIPIs | 在wait-for-SIPI时,收到SIPIs会退出,否则不退出并丢弃该信号 |
| SMIs | 在双重监视模式/SMM时收到SMIs会退出 |
| Task Switchs | VMX不支持硬件任务切换机制,所以相关操作会直接退出 |
| VMX-preemption timer | 设置的抢占计时到达时,它根据TSC与IA32_VMX_MISC递减 |
| 中断(中断号在32~255) | 可将IDTR的limit限制到32,此时在正常分发中断时就会导致虚拟机退出,VMM在模拟异常分发即可 |
推导调试操作
调试需要实现两点,在指定的位置中断,这在虚拟机上表现为VM退出,另一个是读写debuggee的资源,包括寄存器与内存数据,VM退出时能直接获取所有Guest寄存器的值,而对于内存,它需要做一些转换操作,此时它要展示两种视图,一种是当前上下文的虚拟视图,即解析当前上下文的GVA空间,方法就是根据CR3与EPTP开始解析页表,即它会依赖Guest页表结构并与EPT,通过它们建立最终的GVA->HPA映射,并提供统一的读写接口;另一种是整个客户机的物理视图,它只需要根据EPT解析即可。
可见后者比较简单,现在主要关注特定条件时中断(VM退出),参考裸机调试,可使用如下方式中断:
| 方式 | 说明 | 看不见我 |
|---|---|---|
| 模拟执行 | 把内存改为不可执行,执行时EPT violation退出,此时模拟即可为所欲为啦 | 修改EPT,VM看不见 |
| INT3 | 就是通用的备份并修改位0xCC,执行时抛出#BP,exception bitmap置位会退出 | 详见内存操作部分 |
| MTF | 专用的单步事件,进入时注入即能让VM单步并退出,但AMD不支持,且在特殊指令时不单步 | 本来就看不见 |
| DR | 地址写DR0~DR4,监视的类型与大小写DR7,触发时会抛#DB,exception bitmap置位会退出 | 设置MOV-DR exiting隐藏它 |
| RFLAGS.TF | 设置了单步标志,单步并出#DB,exception bitmap置位会退出 | FLAGS寄存器无法触发退出,PUSHF&POPF可以读写它 |
有时,我们需要强制暂停正在运行的程序,在GDB里可通过ctrl+c发送SIGINT信号实现,在VM上,则需要其他方式强制Guest退出,此时可使用INIT等信号。
对于内存访问,访问到的内容可能是内存,也可能是MMIO映射区域,但都是只需要修改页表,在激活EPT时就是修改它,一般是修改权限位,如对某区域的访问进行监控,如执行操作,此时将EPT对应页表项权限限制为不可执行,则程序在执行到该页的某地址处时将会退出,此时可采用模拟执行的方式,这种模拟效率很低且极易出错,此时通常的方式是利用MTF单步执行,如下图:
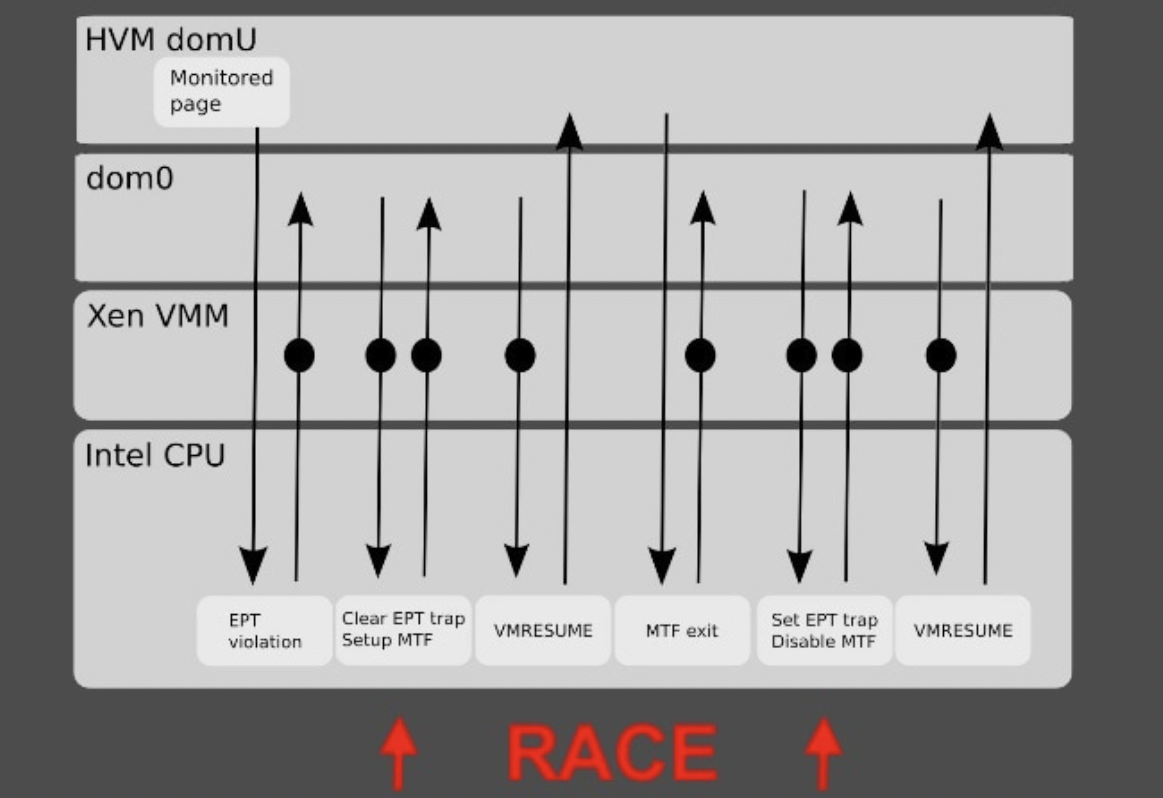
先暂时修改EPT相关项并恢复单步执行,之后再恢复权限,但这在通常的多虚拟处理器vCPU环境下可能出现条件竞争而漏过审查(可先暂停其他vCPU但开销过大),Tamas K Lengyel ^[15]提出了ALT2PM方式,它通过创建多个不同权限的EPT(下图2),由于每个vCPU有VMCS对应,因此可在其退出时先切换EPT再利用MTF机制:
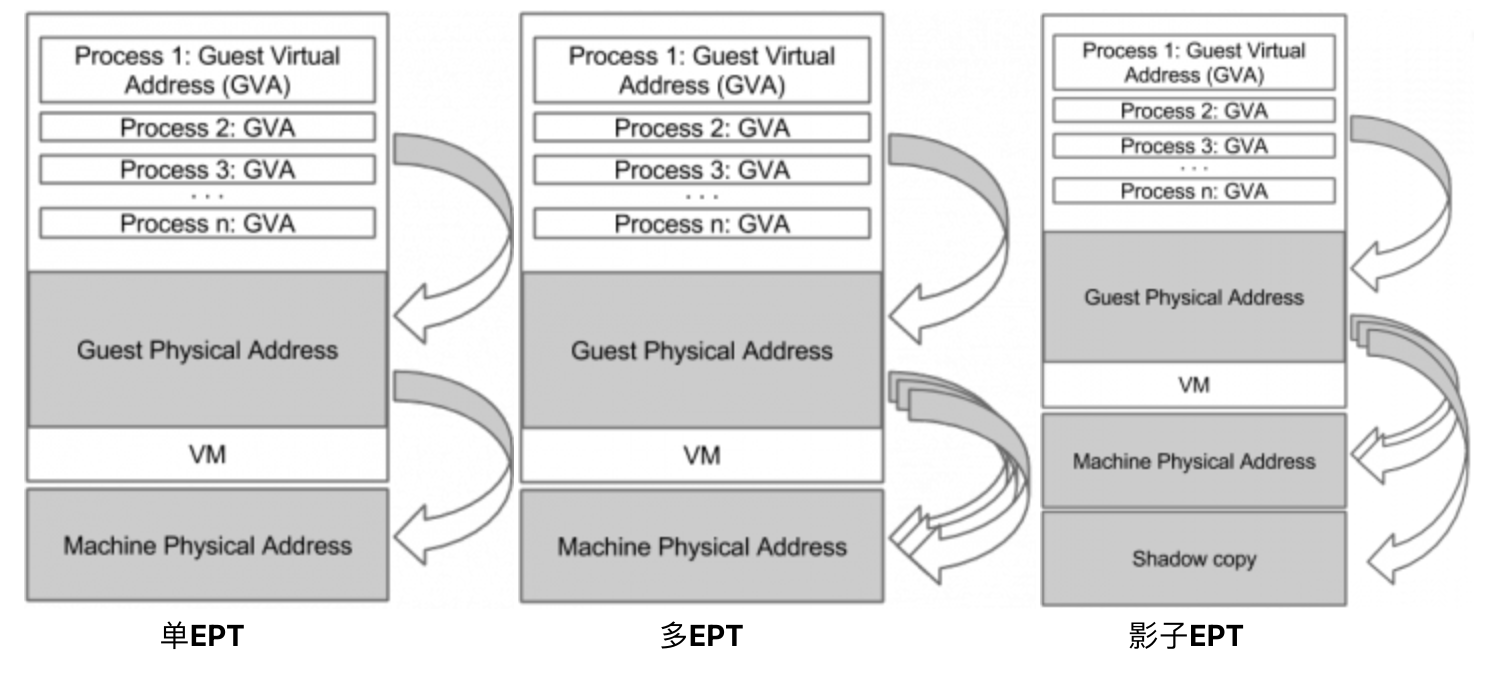
但这种监视的最小粒度是4K,有时只想在函数入口处监视,或对某区域的代码进行修改,这时可以修改并备份原始数据到影子区域,此时EPT不仅权限位不一致,指向的地址映射也会存在差异了(上图3),这时把两种页面的权限改为x与r,修改x权限的原始页,那么它在执行时将会执行修改后的代码,而在读取该区域时由于权限错误的EPT violation导致退出,此时再修改EPT指向r权限的影子页从而获取到原始代码,而在执行时又会由于权限问题退出,再切回修改后的原始页。利用这种方法,就可以实现pre-read/pre-write/pre-exec三种操作,另外一般还需要提供create slot事件监听功能,它表示分配了虚拟内存条。
注:1.在允许侵入Agent时,还可以使用#VE(Virtualization Exceptions)机制,当支持并设置了EPT-violation #VE且发生了EPT violation事件,这时可抛出#VE异常,若设置了该异常不退出则由Guest-IDT处理,此时它可通过VMFunc机制切换EPT,这个过程不会退出VM因此效率更高。
2.EPT还通过Sub-page Write Permission机制支持更小粒度(128k)的写访问限制,不过这个我还没想到咋用...
除此之外,可能还需要监听特殊的事件,如I/O操作,指定的中断请求等,这可根据上面提到的原语实现,不再赘述...
语义重构
尽管VMM可以捕获所有的动作,获取所有的数据,但这是最低级的硬件状态信息(内存/寄存器信息,中断/内存/IO访问事件),VMM并不能很好的理解Guest到底正在做什么,即它们间还存在语义鸿沟:
Consider a situation where we want to detect tampering with our sshd process by periodically performing integrity checks on its code segment. A VMM can provide us access to any page of physical memory or disk block in a virtual machine, but discovering the contents of sshd’s code segment requires answering queries about machine state in the context of the OS running in the VM: “where in virtual memory does sshd’s code segment reside?”, “what part of the code segment is in memory?”, and “what part is out on disk?” ^[1]
VMM必须通过某些方式消除这种鸿沟获取对用户有意义的信息:
1.在上一篇介绍了可以用类虚拟化的方式消除,这是侵入式的,它的缺点就是Guest可感知,在分析某些有反调试/反虚拟机的程序时需要额外操作
2.直接在外部通过已知的一些信息对Guest语义进行重构,如内核关键数据结构(如linux下的task_struct,可参考volatility),如硬件规范(如CR3指向地址,TR指向当前任务段),经典约定(如使用INT80进行系统调用)等...
注:事实上,也可以为目标系统植入隐蔽的Agent,它能不被探测并能执行,想想咋做...
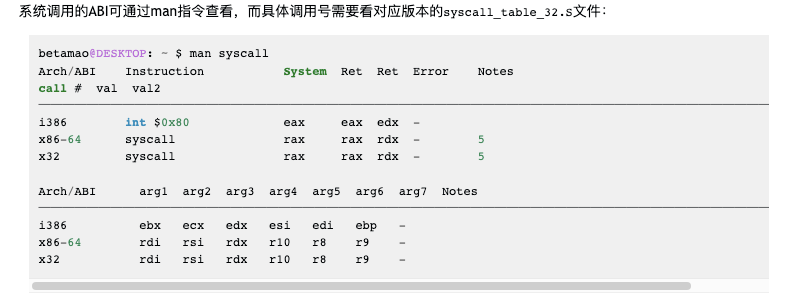
系统调用
系统调用追踪是必备技能,而且语义很简单,如Linux下,系统调用三种方式,如下是它们对应的触发退出的方式:
| 方式 | 审查方式 |
|---|---|
| INT80 | 使用IDTR.limit限制长度 |
| SYSCALL | 备份并将IA32_LSTAR置NULL,或者另IA32_EFER.SCE为0,并将它们的MSR bitmap读写位置位(exiting) |
| SYSENTER | 备份并将IA32_SYSENTER_EIP置NULL,并将它们的MSR bitmap读写位置位 |
当然它们都能在syscall的入口处打断点...方法很多,不过推荐用上表的方式。当退出时,就可以根据ABI获取系统调用号及其参数:
进程识别
Stephen T. J等人提出了地址空间标识符ASID(Address Space IDentifier)的概念^[11],在IA下就是页全局目录PGD的地址,进程在活动时由CR3指向,通过它就能反应当前vCPU的活动进程,对于依据ISA规范推荐的实现,进程创建会有地址空间的创建,表现在ASID就是出现了新的ASID,通过记录CR3即可判断是否是新增的,而进程切换也就伴随着地址空间的的切换,即CR3修改为不同值就是进程的切换(CR3写入原值用于刷新所有TLB),复杂的是进程终止,它伴随着地址空间的销毁,需要有种方式识别它,作者发现系统通常会把页目录区域的用户空间清除,并执行写CR3操作刷新TLB,因此根据这两点来判断执行了进程终止,此时就可以释放掉保存的CR3啦。根据这几点,他们在Linux和windows下做了测试,结果如下:

可见Windows的CreateProcess与Linux的fork类型生命周期都准确识别了,而fork+exec存在伪阳,这是由于Linux 2.4的exec是清除并重用(无CR3切换),而Linux 2.6的exec是销毁原有地址空间并创建新的(有CR3切换)。不过这种错误是可以消除的,因为正常的行为fork与exec间的时间间隙特别短,但不消除影响也不大。
这种技术不依赖操作系统,只要它们别用什么奇葩的方式进行进程操作就没问题。另外还有种方式,它能被用于识别用户态的进程生命周期,dei,系统调用,它直接根据fork/exit等识别进程创建与结束,不多说...
实际上线程才是调度的单位,一般我们都需要获取到线程粒度的信息(CPU上下文),由于它们共用地址空间因此上面这种方式无法区分它,此时需要根据操作系统的实现来看了,如Linux通过TR->TSS来获取内核栈,从而获取线程信息thread_info与任务信息task_struct。
资源操作
CPU对资源的访问有三种方式:MMIO/PIO/专用指令,它们都会导致VM退出(此时不要使用I/O透传),对于外设,由于是直接和虚拟设备交互,因此能轻松获取底层语义,再根据CR3关联任务即可。
特殊行为
这个行为需要根据Guest OS与需求而定了,一般特殊行为都会涉及到MSRs,因此使用MSR bitmap监视特定寄存器操作即可获取,如MSRs一般不需要变化,因此它可能是初始化操作,也可能是恶意行为,如系统调用的入口在初始化后就不变了,若IA32_LSTAR被修改那么很可能是攻击行为。
内核对象识别
这就需要有Guest OS的知识了,如Linux下定位到task_struct结构,它通过链表与其他任务连接,因此能遍历所有任务,除此之外还有各种可内核模块,驱动对象(设备树)等,当然Rootkit也会通过修改内核数据结构(DKOM)达到隐藏自身的目的,因此需要使用多种方式进行识别,这方面多翻翻内存取证的文章就有很多想法啦...
提到内存分析,还有种和虚拟化相关的情形是获取了物理内存Dump后,分析其运行的虚拟机,Graziano描述了根据VMCS结构的特征在内存Dump中定位到它并解析其结构,恢复其代表的VM(处理器与内存),并能分析出嵌套虚拟化的层级结构^[12]。
挑战
缓存一致性:这里的缓存包括CPU<->Mem的缓存与Mem<->File的缓存,还有由于空间不足内存被换出到磁盘,这种情况尤为需要处理
无法使用系统功能:如无法使用锁原语,无法使用写时复制,系统提供的很多接口也不能直接用
当然咯,方法总比困难多,显然这些问题都还是能解决的,只是要花点时间,再说...
本节参考
[1] A Virtual Machine Introspection Based Architecture for Intrusion Detection -- Garfinkel T, Rosenblum M (2003)
[2] “Out-of-the-box” Monitoring of VM-based High-Interaction Honeypots -- Xuxian Jiang, Xinyuan Wang (2007)
[3] Ether: Malware Analysis via Hardware Virtualization Extensions -- Artem, Paul, Msharif, Wenke (2008)
[4] Secure and Flexible Monitoring of Virtual Machines [sci-hub] -- Payne BD, Carbone M, Lee W (2007)
[5] Lares: An Architecture for Secure Active Monitoring Using Virtualization [sci-hub] -- Payne BD, Carbone M, Sharif M, Lee W (2008)
[6] Robust signatures for kernel data structures -- Dolan-Gavitt B, Srivastava A, Traynor P, Giffin J (2009)
[7] Digging For Data Structures -- Cozzie A, Stratton F, Xue H, King ST (2008)
[8] Automated detection of persistent kernel control-flow attacks -- Petroni NL, Hicks M (2007)
[9] Backtracking intrusions -- King ST, Chen PM (2005)
[10] Hypervisor Support for Identifying Covertly Executing Binaries -- Litty L, Lagar-Cavilla HA, Lie D (2008)
[11] Antfarm: Tracking Processes in a Virtual Machine Environment -- Jones ST, Arpaci-Dusseau AC, Arpaci-Dusseau RH (2006)
[12] How Actaeon Unveils Your Hypervisor -- Mariano Graziano and Andrea Lanzi
[14] QEMU-based framework for non-intrusive virtual machine instrumentation and introspection -- Pavel D, Natalia F, Ivan V, Vladimir M (2017)
[13] 基于Qemukvm硬件加速的下一代安全对抗平台 -- 蒋浩天
[14] TLSkex: Harnessing virtual machine introspection for decrypting TLS communication -- Benjamin T, Christoph F, Dominik D, Hans P (2016)
[15] STEALTHY MONITORING WITH XEN ALTP2M -- Tamas K Lengyel (2016)
[16] Stealthy, Hypervisor-based Malware Analysis -- Tamas K Lengyel (2016)
[17] Who Watches The Watcher? Detecting Hypervisor Introspection from Unprivileged Guests -- Tomasz T, Mark B, Joshua Z, Tamas K. Lengyel, K.J. Temkin
[18] Zero-Footprint Guest Memory Introspection With XenIntrospection With Xen -- Mihai Donțu (2019)
[19] Game Changing Hypervisor and Visualization Analysis -- Danny Quist & Lorie Liebrock (2009)
[20] Leveraging KVM as a Debugging Platform -- mtarral (2019)
[21] ADVANCED VMI ON KVM: A PROGRESS REPORT -- Mihai Donțu (2019)
[22] Bringing Commercial Grade Virtual Machine Introspection to KVM -- Mihai Donțu (2019)
[23] Virtualization Based Security - Part 1: The boot process, part2 -- Adrien Chevalier (2017)
[24] A virtual journey: From hardware virtualization to Hyper-V's Virtual Trust Levels -- Salma El Mohib (2021)
削弱安全
VMM在实现时,可能并没有实现所有硬件特性,包括一些硬件安全机制,这削弱其中运行的Guest的安全性。
如对于SMEP特性:
Xen, VMWare - SMEP support
VirtualBox, Hyper-V - no SMEP support
VMWare - virtualHW.version “8” or below - no SMEP support
其他的,如未虚拟化IOMMU,则无法对Guest使用DMA时提供安全保护。