背景
一目标把所有的功能编译到一个单一文件,类似busybox:
现在想挖掘它vpn功能的漏洞,因此只想关注改功能的代码,但是此时分析的是整个文件,一方面它太大了用工具处理就很耗时间,另外它的不相关功能代码将影响分析,例如想通过危险函数回溯的方法查找漏洞,或通过补丁对比分析历史漏洞:
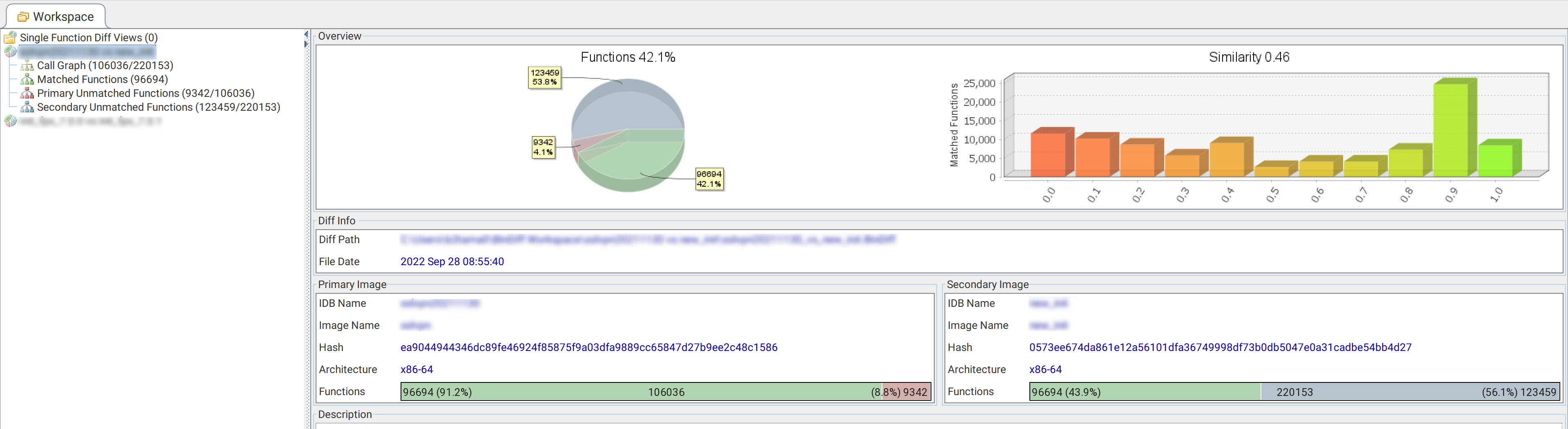
如图可见相邻版本间出现了数万不匹配函数严重干扰分析,因此若能根据独立的功能把它再分割为单个可执行文件还是有点用滴!
思路
影响分析的只有代码段,因此只关注代码,识别出不可达的函数,若完全避免分析可将其nop掉(只nop可避免修复重定位信息),或将其以特殊方式标记,现在的难点是识别不可达的函数,思路如下:
- 手动分析,确定上下界,一个可执行文件是由很多目标文件链接形成的,它们链接时以单个目标文件为整体进行合并,如果它的链接顺序是:将单个服务的目标对象链接在一起,再将所有的单个服务链接在一起,那么单个服务的代码一定是连续的,手动确定上下界即可识别出可达函数,其他就是不可达的。
- 静态分析,从入口点开始,通过函数引用来获取,这里的引用包括函数调用或函数指针赋值,通过分析每个函数又引用了哪些函数来确定可达函数
- 动态追踪,由于它每个服务功能使用单独的进程,因此追踪某一进程获取到的一定是该服务的,记录下该进程执行过的所有函数,这不会有误报😯
实现时,可能需要多种方式结合:
经分析,它的链接过程可能并不是单个功能先链接为一个目标文件,因此一个服务的代码可能分散在最终文件的多个位置,用上下界不能精确的获取,而且上下边界也难以确定,所以这种方式不能作为主要方案,但可用于辅助...
通常各功能代码里的函数调用不会调用到上层入口或其他功能,但也要小心有时识别错误会导致遍历到其他功能,如存在一个xxx_main的功能入口函数,若在另一个功能里恰巧出现了xxx_main(这种字符串并将其识别为了函数,则会导致错误的遍历
若某段代码被多个功能遍历到,则将其标注为共享代码,此时每个可执行文件中都需要保留它。
选择用调用关系来获取,思路为:
- 动态追踪:它要做两点,记录执行流,可使用ptrace判断执行的每条指令,记录call指令的目标,或用插桩工具,如frida的stalker记录;触发尽可能多的分支,可使用爬虫之类的工具去,但是很多分支难以触及...
- 静态分析:想到静态二进制分析后生成CFG,比较复杂不适合我这种弱鸡,还可使用IDA的反编译信息自己生成调用信息,自己写个脚本,使用BFS去遍历所有可能的函数
实现
这里选择静态分析,用IDA的反编译功能来做,简单,肯定会漏滴,如函数存在于某数据结构中则分析不到,如下这种就无法静态分析到:
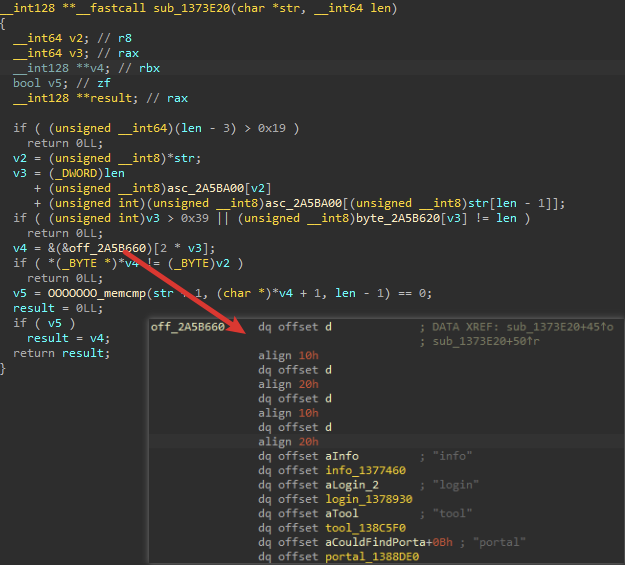
但是可以给代码留个坑,漏滴以后分析后补上就好了,而且漏掉20%,剩下的80%还不够分析?!...
获取函数范围
首先要知道一共有哪些函数,哪些是导入函数,这样就能为以后确定是否是函数提供依据,并避开一些不必分析的函数(如库函数):
class CallFat(object):
def __init__(self, cache_path, include_segment=('.text')):
...
# 缓存指定段的范围
self.__init_include_range(include_segment)
# 获取函数信息
self.__init_function_info()
...
def __init_function_info(self):
for func_addr in Functions():
func_name = get_func_name(func_addr)
# 缓存所有的函数 与 函数地址映射关系
self.func_name_set.add(func_name)
self.func_name_addr_map[func_name] = func_addr
# 缓存所关注的函数,如位于.text段的函数
if self.is_include_func(func_addr):
self.include_name_set.add(func_name)
def __init_include_range(self, include_segment):
valid_range = []
for seg_name in include_segment:
seg = get_segm_by_name(seg_name)
seg and valid_range.append((seg.start_ea, seg.end_ea))
self.include_range = valid_range
def is_include_func(self, func_addr):
for seg_range in self.include_range:
if seg_range[0] <= func_addr <= seg_range[1]:
return True
return False
获取函数引用的函数
class CallFat(object):
FUNC_NAME_PAT = compile(r'[a-zA-Z_]\w+')
def __init_cache(self):
"""由于这种操作效率很低,因此实现缓存以后会有用 """
try:
with open(self.cache_path, 'r', encoding='utf8') as f:
self.data = load(f, object_hook=lambda x: {k: set(v) for k, v in x.items()})
except Exception as e:
self.data = {}
print(f'load cache failed: {e}')
def flush_cache(self):
try:
with open(self.cache_path, 'w', encoding='utf8') as f:
dump(self.data, f, indent=4, default=lambda x: list(x) if isinstance(x, set) else x)
except Exception as e:
print(f'flush cache failed: {e}')
def find_ref_to_funcs(self, func_name: str):
"""获取函数所引用的函数 """
if func_name in self.data:
# 尝试从缓存里取
return self.data[func_name]
try:
# 先反编译函数获取伪代码
func_c_code = str(decompile(self.func_name_addr_map[func_name]))
# 获取所有的函数
found_funcs = set(self.FUNC_NAME_PAT.findall(func_c_code)) & self.func_name_set
self.data[func_name] = found_funcs
except Exception as err:
print(f'error? -> {func_name} : {err}')
self.data[func_name] = set()
return self.data[func_name]
遍历
通过类似广度优先搜索遍历所有函数:
def walk(self, start_name_set: set, ignore_name_set: set = None):
"""从起始点集合开始遍历所有可达的函数
start_name_set: 起始点集合
ignore_name_set: 忽略点集合
ret: 起始点可达的函数集合
"""
ignore_name_set = ignore_name_set or set()
walked_name_set = set()
# 开始遍历
need_walk_name_set = set(start_points)
i = 0
while len(need_walk_name_set) > 0:
i += 1
next_func_name = need_walk_name_set.pop()
walked_name_set.add(next_func_name) # 标记为已遍历
if next_func_name in ignore_name_set:
continue
found_func_set = self.find_ref_to_funcs(next_func_name)
not_walked_set = found_func_set - walked_name_set
need_walk_name_set.update(not_walked_set)
if i % 100 == 0:
print(f'i={i}, need_walk_len={len(need_walk_name_set)} arrived_len={len(walked_name_set)}')
if len(self.data) % 1000 == 0:
self.flush_cache()
self.flush_cache()
return walked_name_set
标记
想到三种标记方法:
def nop_for_func(self, func_name, func, _):
"""把函数nop掉,直接就没交叉引用了 """
func_len = func.end_ea - func.start_ea
patch_bytes(func.start_ea, b'\x90' * func_len)
def add_weiber_for_func(self, func_name: str, func, _):
"""给函数名添加尾巴或脑壳 """
if func_name.startswith(self.WEI_BER):
return
new_name = self.WEI_BER + func_name
set_name(func.start_ea, new_name)
def coloring_for_func(self, func_name, func, args):
"""着色,把这玩意儿染成绿的 """
func.color = args.get('COLOR') or self.COLOR_GREEN
return update_func(func)
经尝试还是修改函数名比较好...
分析入口
现在遍历的函数有啦,要找从哪些点开始分析,正常程序从main函数开始,这里也可以从要分析的服务的入口点开始分析,即sslvpnd函数:
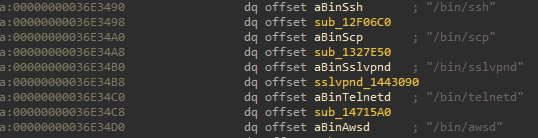
经分析这是一个魔改版的apache httpd的入口,显然它的初始化等很多过程无法控制,分析也没用,因此决定从连接建立后开始最终,由于apache模块是运行后注册的,上面的代码无法遍历到,因此手动分析添加所有模块的入口,以及一些其他的点,最后获取到入口集合:
start_points = [
'sub_13C4110', 'sub_13C4170', 'sub_13CB080', 'sub_13CB0E0', 'sub_13C8200', 'sub_13C8260',...
]
rmt_webcgi_handlers = [
'info_1377460', 'login_1378930', 'tool_138C5F0', ...
]
modules_cb = [
'rmt_webcgi_handler_138D1E0', 'default_handler_133C240', ...
]
start_points.extend(rmt_webcgi_handlers)
start_points.extend(modules_cb)
另外有些函数需要排除掉,如导入函数,还有些,像main这种...,之后就是遍历并标记...
ignore_name_set = cf.func_name_set - cf.include_name_set
ignore_name_set.add('main') # 这种短函数名太容易误报了!!
walked_set = cf.walk(start_points, ignore_name_set)
need_patch_set = cf.func_name_set - walked_set
cf.add_weiber(need_patch_set)
到此,可能会觉得偏题了,其实调用关系已经在缓存里被记下了。。。
限制
由于不能很好识别间接调用,因此像C++这种大量虚函数调用的效果会很差