背景
分析某产品,其进程对应的是二进制文件,使用IDA打开可见是使用Frozen打包:
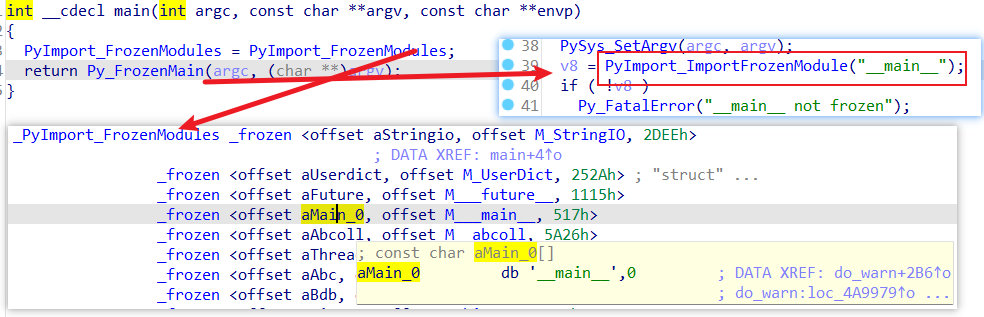
搜索字符串可知其Python版本是2.6.4,于是可写脚本把它冻结的字节码数据拿出来,再修复头部反编译得到入口,经分析它的入口只是一个Loader,其注册了一个Importer Hook用于加载位于其他位置的名叫XXX.ipoe的库:
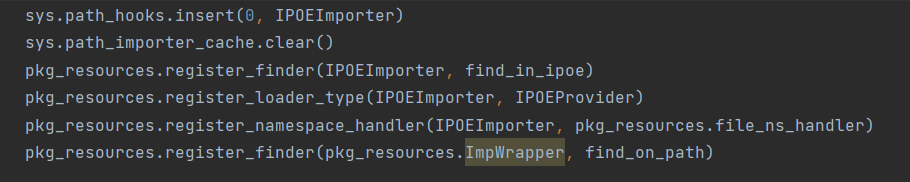
这些库其实就是EGG文件,它里面每个文件被加密了,因此分析Importer即可知道如何解密,解密后发现可执行的有.SO与.PYO,从量看基本是后者,那么直接反编译可得到源码...
注:PYO是优化后的字节码序列化文件,它其实没做什么,比如只去掉了assert和doc注释,但它反编译的代码和源文件会存在较大的差别(行号不对应)。
由于它使用Python2.6开发(动态语言没注解),又是古老的框架,静态看了一些点感觉累,以及有些位置看着有问题黑盒验证失败,就想着动态分析,最好能像普通开发一样在IDE里做调试,但是IDE只支持源码级调试,而此处只有PYO与反编译的伪码,这没办法直接调试...
前置知识
调试原理
Python虚拟机
静态数据结构
CPython现在依然只使用解释执行,一般输入的.py文件会被编译为字节码文件再交由解释逻辑去执行它,这里的字节码文件在外部看它是.pyc/.pyo为后缀的文件,这个文件的内容其实是头部+序列化后的字节码对象,头部依据版本现在已经有三种不同的形式,如Python2的为4字节魔数加4字节时间戳,其后的内容为使用marshal方法序列化后的CodeObject对象:
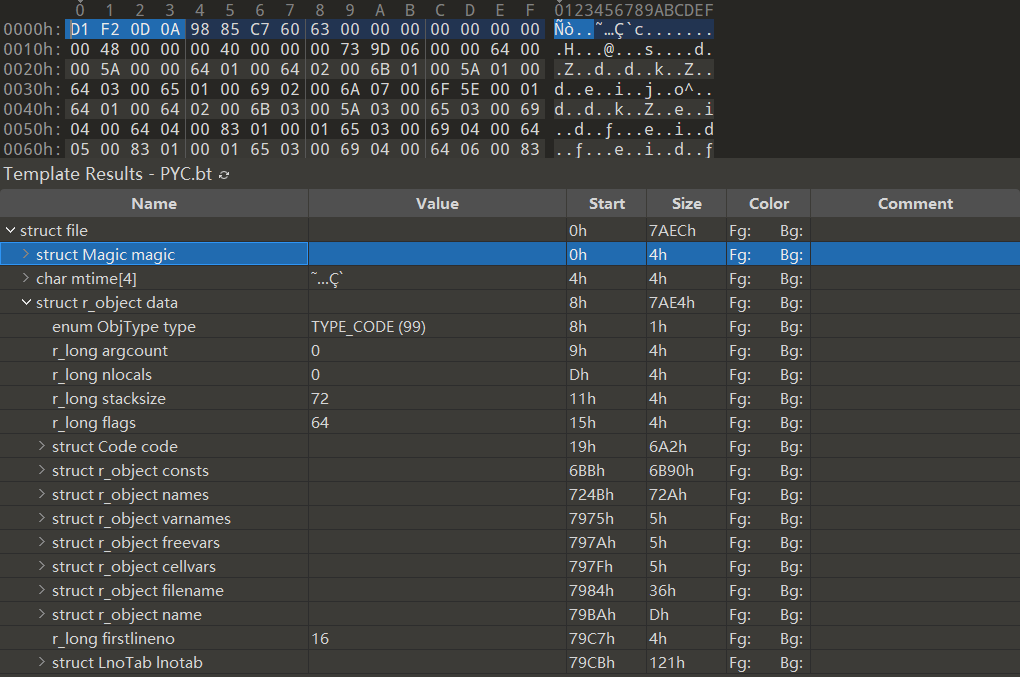
如这里的图,其核心是偏移为8开始的data字段,它其实是一个CodeObject,它里面的consts域里除了普通常量外还有其他的CodeObject,在编译时Python会将不同的Code Block(不同作用域为一个块)编译为一个单独的CodeObject,其按树状组织(可以类比为一棵语法树),CodeObject里面存储的是编译时的静态数据(编译时只分析语法不执行,因此会出现很多编译通过但执行错误的情况),这里面当然没有多余的数据,如code域里是指令,Python2使用的是变长指令,每条指令可以为1或3字节,其他域都很重要这里说几个和调试相关的:
- filename:该对象原始的文件名,下断点时指定文件名通常会与它做匹配。
- name:当前CodeObject的名称,模块最外层的通常为
,内部一般是函数名等,下断点时也会匹配它 - firstlineno:当前块在源码中的起始位置。
- lnotab:这里记录的是当前块里字节码与源码间的对应关系,为
int PyCode_Addr2Line(PyCodeObject *co, int addrq)
{
int size = PyString_Size(co->co_lnotab) / 2;
unsigned char *p = (unsigned char*)PyString_AsString(co->co_lnotab); // CPython将行号表当作字符串来处理
int line = co->co_firstlineno; // 当前块在源码中的其实行号
int addr = 0;
while (--size >= 0) {
addr += *p++; // 这里是字节码偏移的累加,下面还有行号偏移的累加
if (addr > addrq) // 若字节码的地址大于请求的地址,则上一次计算的行号就是请求地址对应的行号
break;
line += *p++;
}
return line;
}
上面这几个域决定了如何在源码上下断点并使解释器中断到正确的字节码位置,如下是使用Pycharm打断点时,它发送的数据包,它表明是在Python的行上下断点,源码的位置是什么,断点的行号,函数名(还有挂起的策略,中断的条件,中断执行的表达式,这是其他高级功能请略过):
 需要说明的是,除了name,其他三个域仅用于追踪(调试/回溯),相当于调试信息,它并不会影响程序的正常执行,因此可以把它们删掉或改掉扰乱分析(虽然意义不大)。
需要说明的是,除了name,其他三个域仅用于追踪(调试/回溯),相当于调试信息,它并不会影响程序的正常执行,因此可以把它们删掉或改掉扰乱分析(虽然意义不大)。
动态数据结构
上面说到CodeObject只存储编译时的静态数据,而真正执行时需要另一个结构来存储动态的运行时数据,即FrameObject,每个块会对应一个该结构,它可存储当前执行的上下文(当前执行的字节码位置,栈,名字空间等),FrameObject通过f_back域链接在一起,CodeObject作为它的一部分被传入解释核心去执行,而Python里还有两个重要的状态ThreadState和InterpreterState,前者存储Python线程的状态,后者存储当前解释器的状态,一般一个进程之后有一个InterpreterState,而它下面可以有很多线程,每一个Python线程(可以有其他线程,这种不会有ThreadState对应)会对应前者,ThreadState里含FrameObject,也是由线程来执行它,不过需注意它在执行Python部分时必须先获取全局解释器锁GIL(非Python部分视情况而定可以不要)...
调试机制
除了Native代码依赖于硬件机制(也可埋调试代码),其他的都是通过埋桩实现的,CPython对外提供settrace方法注册调试回调,在每执行新行/函数进入退出/异常等时会调用该回调,所有种类如下:
 将断点处的上下文传给回调函数,于是回调函数就可以实现需要的逻辑,该回调如:
将断点处的上下文传给回调函数,于是回调函数就可以实现需要的逻辑,该回调如:
import sys
def tracer(frame, event, arg = None):
"""
:param frame 当前中断发生的上下文(FrameObject的封装),通过它可以获取所有运行时信息
:param event 中断的原因,如函数进入/退出,发生异常,执行了一条字节码/一行源码等,可通过对它做判断选出感兴趣的事件
:param arg 根据event而定,如异常信息等
"""
code = frame.f_code
func_name = code.co_name
line_no = frame.f_lineno
print(f"A {event} encountered in {func_name}() at line number {line_no} ")
return tracer # 注意这里返回了函数自身,这能实现持续追踪,否则该回调执行一次后就不再执行
sys.settrace(my_tracer) # 注册最终函数,默认不追踪字节码,这太耗性能了
这是Python层面,实际原理需要继续分析,它的实现如下:
static PyObject *sys_settrace(PyObject *self, PyObject *args) // 这里的args就是回调函数
{
if (args == Py_None)
PyEval_SetTrace(NULL, NULL);
else
PyEval_SetTrace(trace_trampoline, args); // trace_trampoline是C函数,它作为蹦床去执行python回调
Py_RETURN_NONE;
}
void PyEval_SetTrace(Py_tracefunc func, PyObject *arg)
{
PyThreadState *tstate = PyThreadState_GET(); // 注意这里是获取当前线程,即settrace只会在本线程生效,若跟踪每个线程需要各自注册
PyObject *temp = tstate->c_traceobj;
_Py_TracingPossible += (func != NULL) - (tstate->c_tracefunc != NULL);
Py_XINCREF(arg);
tstate->c_tracefunc = NULL;
tstate->c_traceobj = NULL;
tstate->use_tracing = tstate->c_profilefunc != NULL;
Py_XDECREF(temp);
tstate->c_tracefunc = func; // 蹦床
tstate->c_traceobj = arg; // python实现的trace callback被存储到这里
/* Flag that tracing or profiling is turned on */
tstate->use_tracing = ((func != NULL) || (tstate->c_profilefunc != NULL)); // 是否使用trace的标志
}
在看看蹦床函数,它其实就是调用之前注册的trace_callback,注意在一个帧里只有CALL事件使用ThreadState里保存的,也就是之前注册的trace函数,该函数被调用一次后其返回值会被FrameObject保存,之后会使用它作为trace_callback,可以想想原因为咩:
static int trace_trampoline(PyObject *self, PyFrameObject *frame, int what, PyObject *arg)
{
...
if (what == PyTrace_CALL)
callback = self; // CALL是一个新帧,此时调的函数是从外部(ThreadState的c_tracefunc)传来的
else
callback = frame->f_trace; // 在其他事件时使用的是frame里的f_trace
if (callback == NULL)
return 0;
result = call_trampoline(callback, frame, what, arg); // 调用trace callback
if (result == NULL) { // 如果tracer的返回为空那么就取消trace
PyEval_SetTrace(NULL, NULL);
Py_CLEAR(frame->f_trace);
return -1;
}
if (result != Py_None) {
Py_XSETREF(frame->f_trace, result); // 否则把返回值作为新的trace callback
}
...
}
现在注册的部分差不多了,再看看这些回调在何时被调用,它位于解释核心代码:
PyObject* _Py_HOT_FUNCTION _PyEval_EvalFrameDefault(PyFrameObject *f, int throwflag)
{
// 这个函数就是解释字节码的位置,可见它传入的参数是FrameObject
...
tstate->frame = f; // 把新帧给ThreadState
// 这里是函数刚开始,若之前注册了追踪就在此调用回调
if (tstate->use_tracing) {
if (tstate->c_tracefunc != NULL) {
if (call_trace_protected(tstate->c_tracefunc, // 可见这里传入的类型为PyTrace_CALL,而使用的回调函数
tstate->c_traceobj, // 是tstate->c_tracefunc,它是蹦床,它会调用tstate->c_traceobj,这
tstate, f, PyTrace_CALL, Py_None)) { // 才是真正注册的trace_callback
/* Trace function raised an error */
goto exit_eval_frame;
}
}
}
...
// 正式开始解释执行字节码,这就是一个大循环,里面用switch根据指令操作数解释
for (;;) {
// 在每次循环时判断,做字节码/行号追踪
if (_Py_TracingPossible && tstate->c_tracefunc != NULL && !tstate->tracing) {
f->f_stacktop = stack_pointer;
err = maybe_call_line_trace(tstate->c_tracefunc,
tstate->c_traceobj,
tstate, f,
&instr_lb, &instr_ub, &instr_prev);
...
}
// 解释字节码,这里面一些关键点也会进行追踪,如出现异常...
switch (opcode) {
TARGET(NOP) ...
TARGET(LOAD_FAST) ...
...
}
}
// 跳出解释循环后,还会继续根据退出原因做跟踪
error: // 这是个异常的退出点
...
if (tstate->c_tracefunc != NULL)
call_exc_trace(tstate->c_tracefunc, tstate->c_traceobj, // 触发trace_callback(f, PyTrace_EXCEPTION, exception)
tstate, f);
fast_yield: // 这是个退出点
if (tstate->use_tracing) {
if (tstate->c_tracefunc) {
if (why == WHY_RETURN || why == WHY_YIELD) { // 退出原因是正常返回
if (call_trace(tstate->c_tracefunc, tstate->c_traceobj,
tstate, f,
PyTrace_RETURN, retval)) { // 触发trace_callback(f, PyTrace_RETURN, retval)
Py_CLEAR(retval);
why = WHY_EXCEPTION;
}
}
}
}
...
}
这里就不继续列代码了,就这样...
现有调试器
搜索了一下现有的调试器:
- pdb:Python自带的调试器,功能特别简单。
- gdb-plugin:这是Python附带的一个小工具,它是gdb扩展,用于调试CPython。
- debugpy:这是实现了微软DAP(Debug Adapter Protocol)的Python调试工具,是和VSCode配套的。
- PyDevD:其中Pydevd是很多IDE的选择,如Pycharm使用它。
- trepan2(trepanxpy):它自身就支持无源码调试,其界面类似于gdb,另外它还支持调试不同版本,但是需要x-python配合,后者是CPython的Python实现。
trepan2似乎是最直接可用的,但是测试它需要安装很多依赖库,这里分析的环境自带的python不好装这些东西,后续踩了很多坑,另外也感觉它实际并没有PyDevD配合IDE调试方便,于是果断转向后者...
注:在分析设备时,搭建调试/开发环境可能会有很多障碍,首先一个设备里多种服务相互依赖将某功能单独提出可能需要踩很多坑,其次某些设备使用的操作系统难以安装/编译各种所需软件,它们可能使用裸系统或不再维护的发行版,存在包仓库已经无归档,ABI兼容性问题等,另外软件间依赖关系很强,如某些关键库被静态链入关键程序,而该关键程序缺失某些分析工具所需要的功能...
具体操作
首先获取gui的环境变量,保证之后我们自己启动时环境变量一致,之后查看它是被谁启动的:
ps jaux |grep gui # 获取父进程得知它是由heimdall启动的,后者是由init启动的
ps wwweaux |grep gui # 获取执行的环境变量
之后,直接杀掉它发现会被自动重启,看来heimdall会监控它,于是修改heimdall的配置(/data/release/phoebe-14-0-0-698.1624600837/etc/heimdall),不让它管理gui,修改完应该有其他方式让它重启或重新加载配置我是直接重启系统,之后gui不会自动启动了,而是需要由我们自己启动...
失败的尝试
- 首先尝试直接反编译所有ipoe文件,使用它自带的解释器运行,失败了,有改不完的运行时错误(在代码很多时,反编译后的文件不能正确运行必然发生)...
- 接着尝试直接在它的早期插入调试服务代码,这里选择
__main__模块第一行导入的runpy,在其(/usr/local/lib/python2.6_10_amd64_thr/runpy.py)首部加载调试片段:
sys.path.append('/tmp/pydevd-pycharm-191.4212.43') # 直接下载解压,它没有依赖第三方库
sys.path.append('/data/links/lib/python2.6_10_amd64_thr/') # 需要包含其他标准库
import pydevd_pycharm
print('import runpy, the argv is ', str(sys.argv))
if 'gui' in str(sys.argv):
print('starting trace...')
pydevd_pycharm.settrace('192.168.199.189', port=8080, stdoutToServer=True, stderrToServer=True)
print('trace continue...')
else:
print('dont care...')
运行发现没有thread模块,pydevd需要多个工作线程处理与调试客户端的交互/调试任务等,尝试用dummy_thread会卡死,于是这条路失败...
最终的方法
开始第三条,思路是上两种结合,用另一个支持thread的python去启动整个项目,并且运行的依然是官方提供的pyo文件,具体如下。
先让它跑起来
ironport自带的另一个python 2.6是支持thread的,那可以用它启动提取出的__main__模块,布局如下:
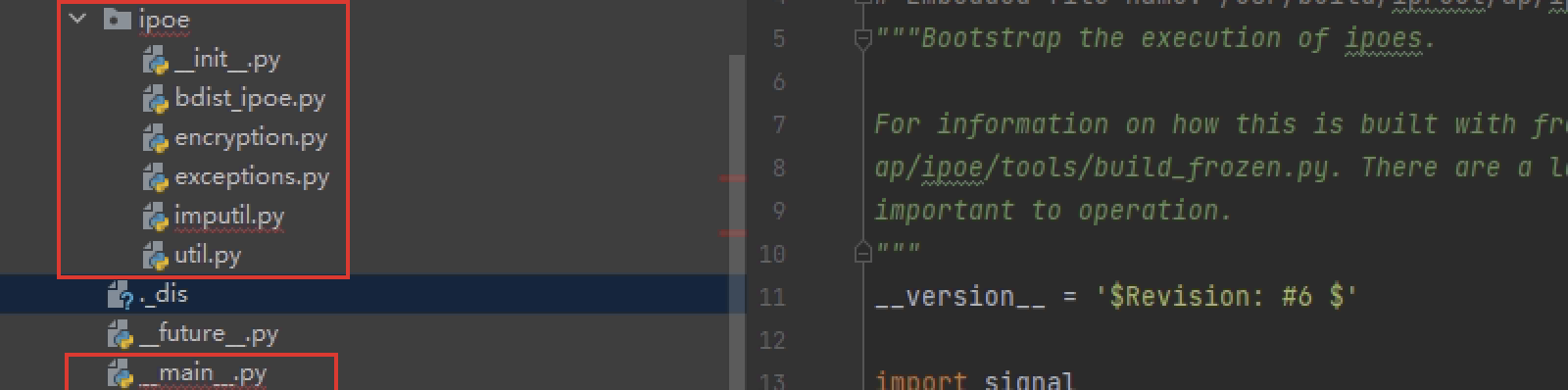
注:经分析它的frozen版和单独的解释器使用的编译选项不同,如前者是不支持多线程(_nothr)的而后者支持(_thr),前者把sslip和sslip2这两个pyx库静态编译进去了,后者需要从外部加载。
它们是比较关键的,frozen里提取的其他文件也可以先扔该目录(之后运行re模块会出现致命错误,把它删掉用python自带的就好),之后配置好包路径运行:
PYTHONPATH=/data/lib/python2.6_10_amd64_nothr/site-packages/ # 这里指定site目录,它里面的easy_install.pth导入了ipoe
COMPRESS_CONFIG=1 HEIMDALL_SOCK=/tmp/heimdall.sock
...
python -O __main__.py gui --debug # -O 支持导入pyo,默认支持pyc
首先是缺sslip2,它是imputil解密用的,而sslip2本身又是位于加密的ipoe里,~~死锁了~~才怪,它的frozen版本里是把它静态编译进去的:
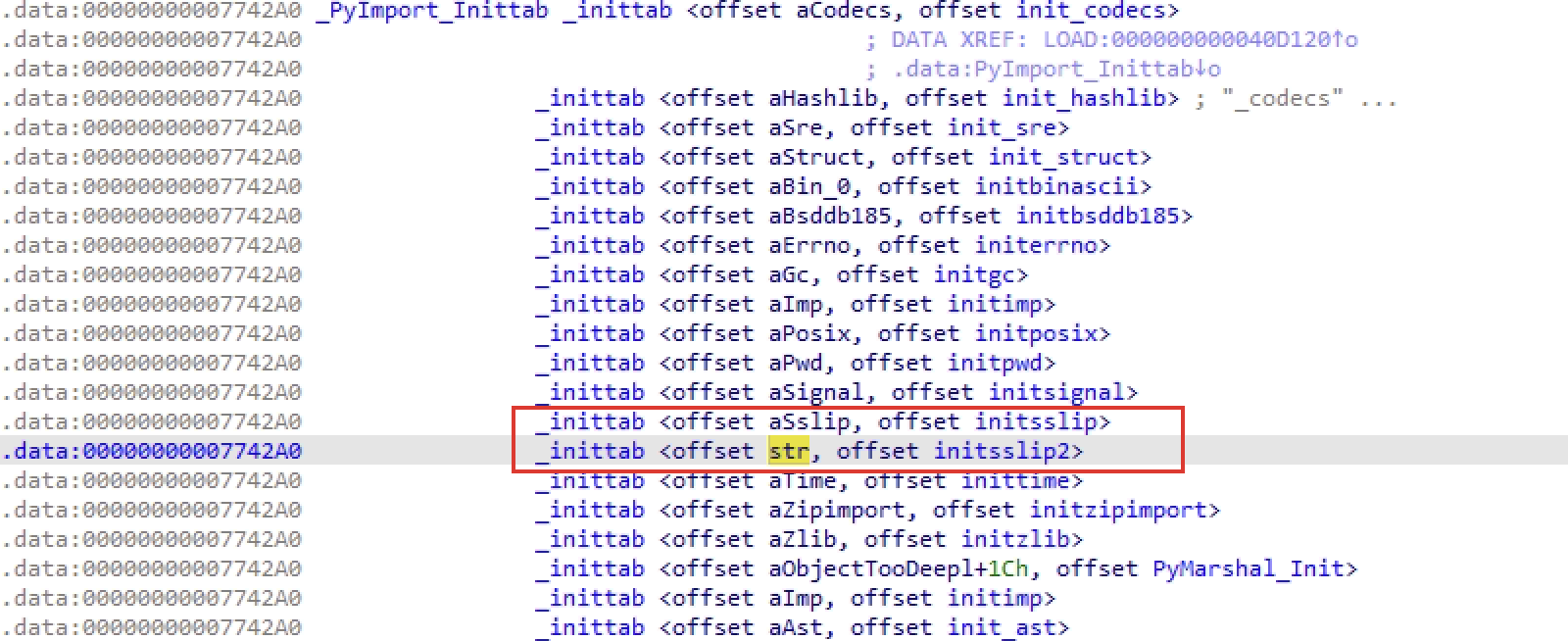
这里直接提取解密后的so让python加载即可,但是在添加import hook后它会使用ZipImporter去加载于是会出现找不到的情况,这里把它打包成egg文件即可正常加载,另外还需要注意存在sslip包,它没什么实际作用但是很多模块都导入了它,可以先创建个dummy版,之后真的需要时再实现它的功能:
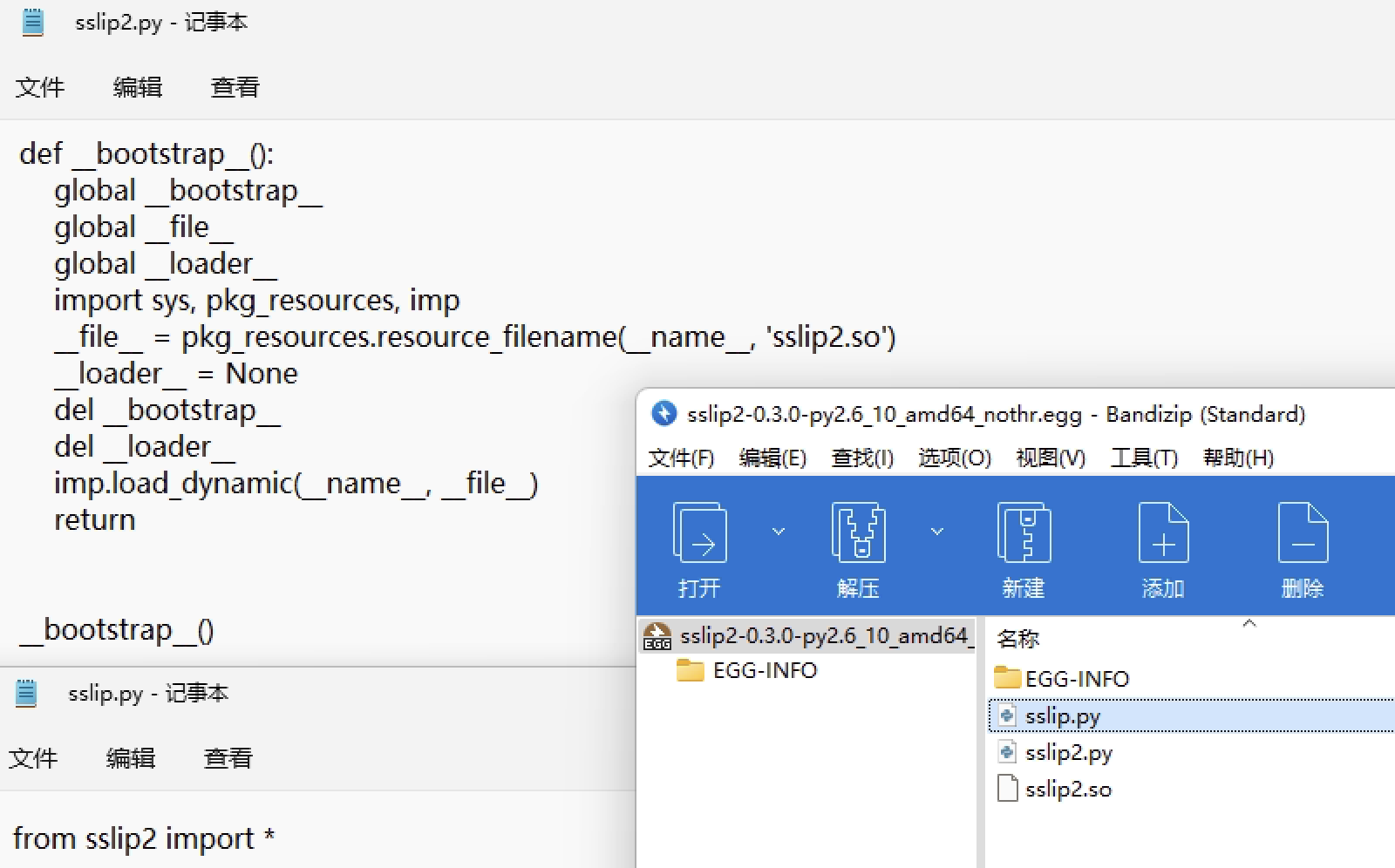
再次运行,如果它缺什么就在site目录添加一个pth文件,将缺少的包加进去,这里运行会发现需要再添加如下包:
./app_site_packages-1.0.0_000-py2.6_10_amd64_nothr.ipoe
./aquarium-2.2.1-py2.6_10_amd64_nothr.ipoe
./common_packages-1.0.0_000-py2.6_10_amd64_nothr.ipoe
./report_packages-1.0.0_000-py2.6_10_amd64_nothr.ipoe
./reporting_ui_esa-1.0.0_000-py2.6_10_amd64_nothr.ipoe
./tracking_ui_esa-1.0.0_000-py2.6_10_amd64_nothr.ipoe
让它可以调试源码
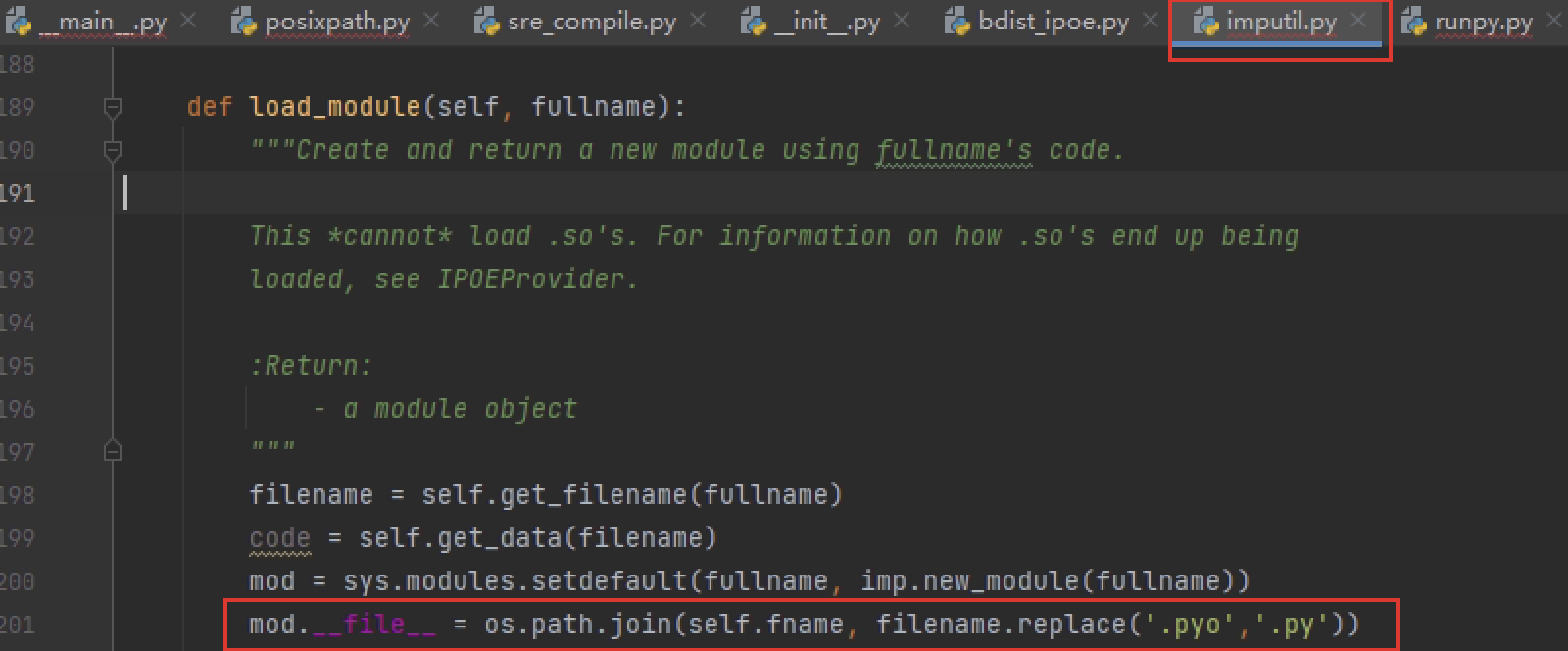
之后可以成功运行,为了调试方便将所有目标环境的包反编译到当前pycharm的项目里,这样之后可以实现自动映射,但是在调试时发现它内存中的文件名是pyo无法映射,于是在导入时将其改为py:
这样就可以自动映射开始源码调试了:
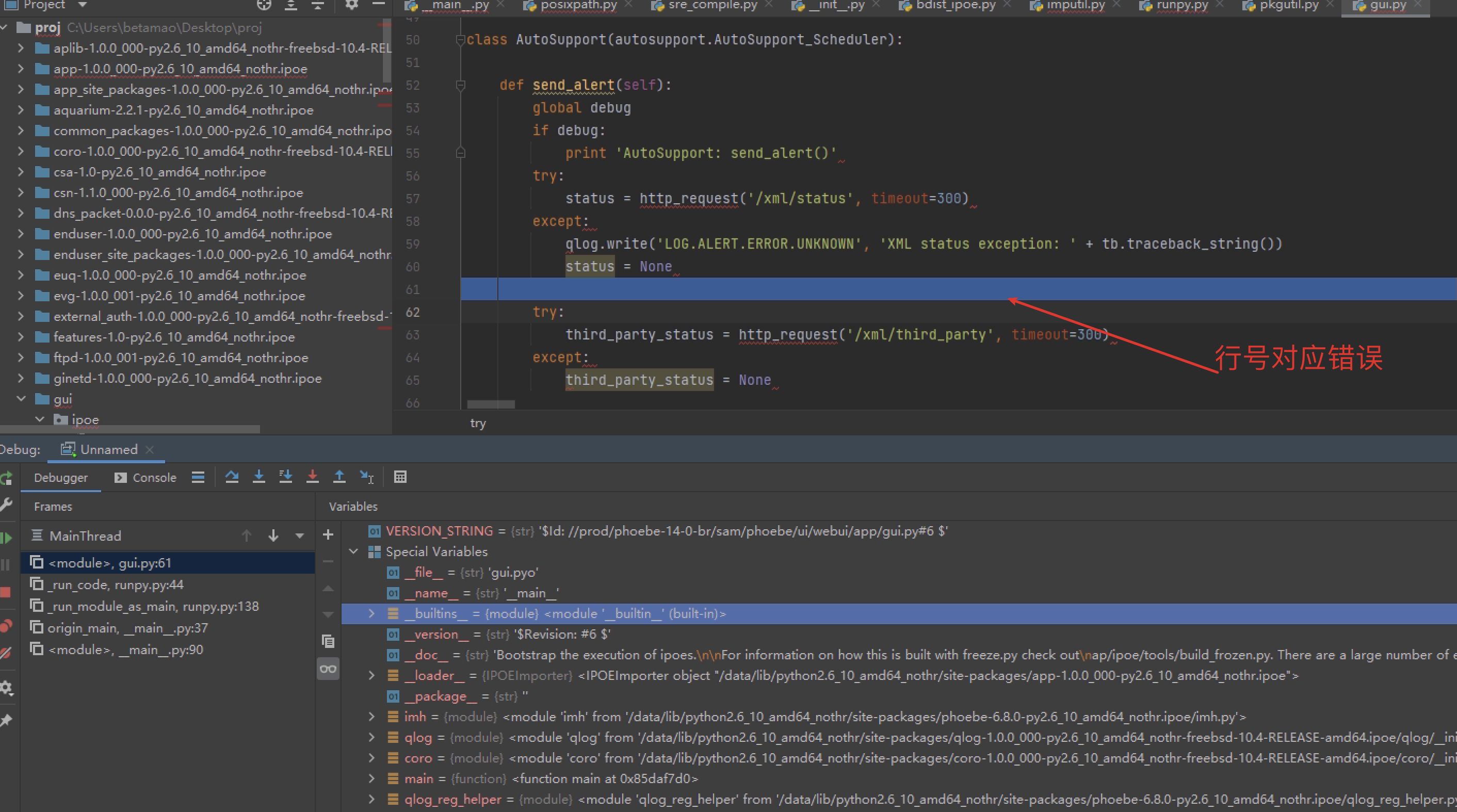
但是会发现反编译的行号和pyo里的不一致导致很难看,一般反编译工具在内部都会使用或生成行号表信息,查了下uncompyle发现它支持输出行号表,由于行号表不影响程序运行,因此可以将新生成的行号表映射回去,不过研究了一下午没搞懂它的行号咋生成的,反正是错的不能用,于是换种思维,基于那种假设,反编译后的文件与字节码文件有很强的对应关系(看了下uncompyle也是在用模板输出了前序遍历的抽象语法树),那么就直接再把反编译后的文件再次编译,用新生成的行号表替换原来的行号表,如下:
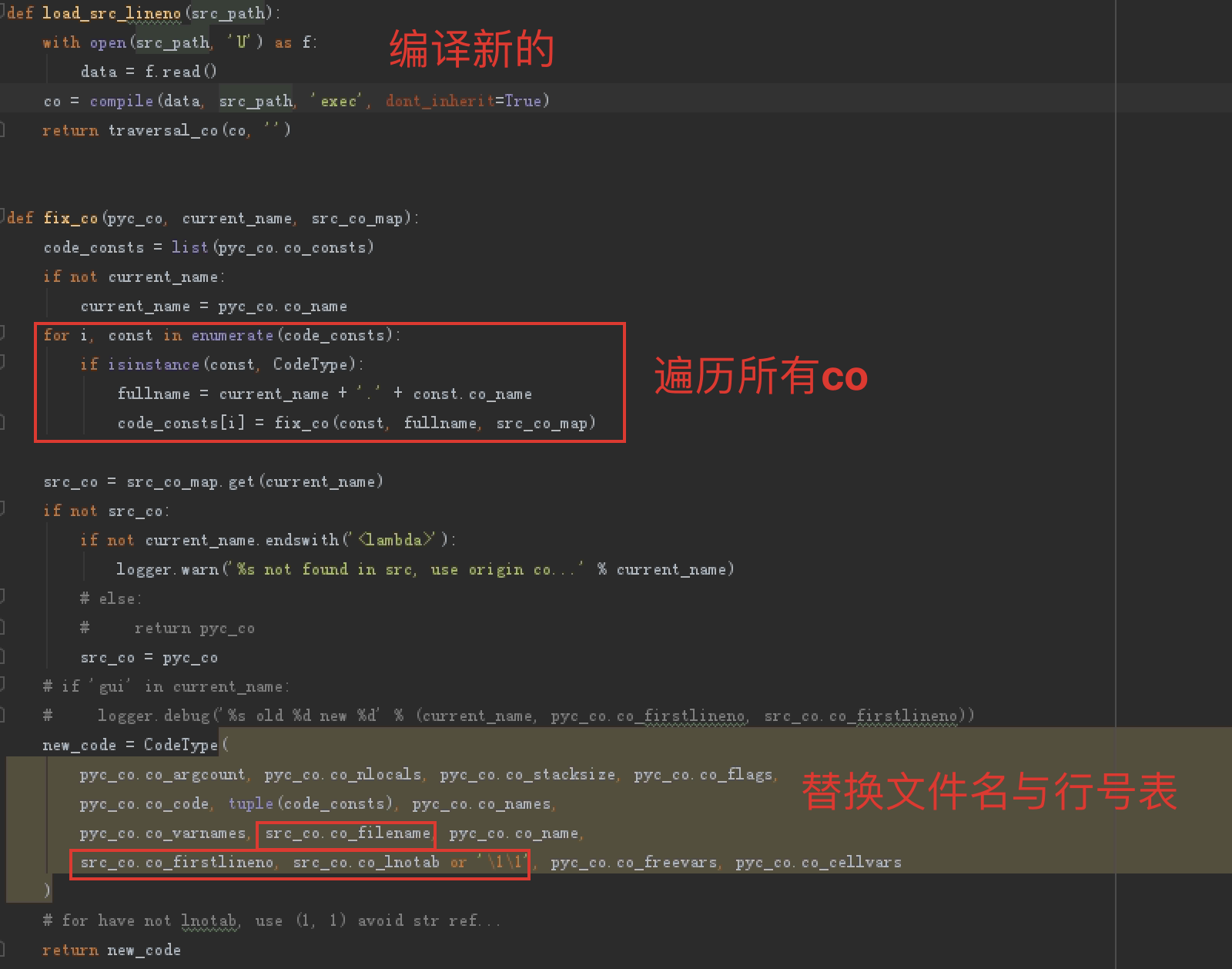
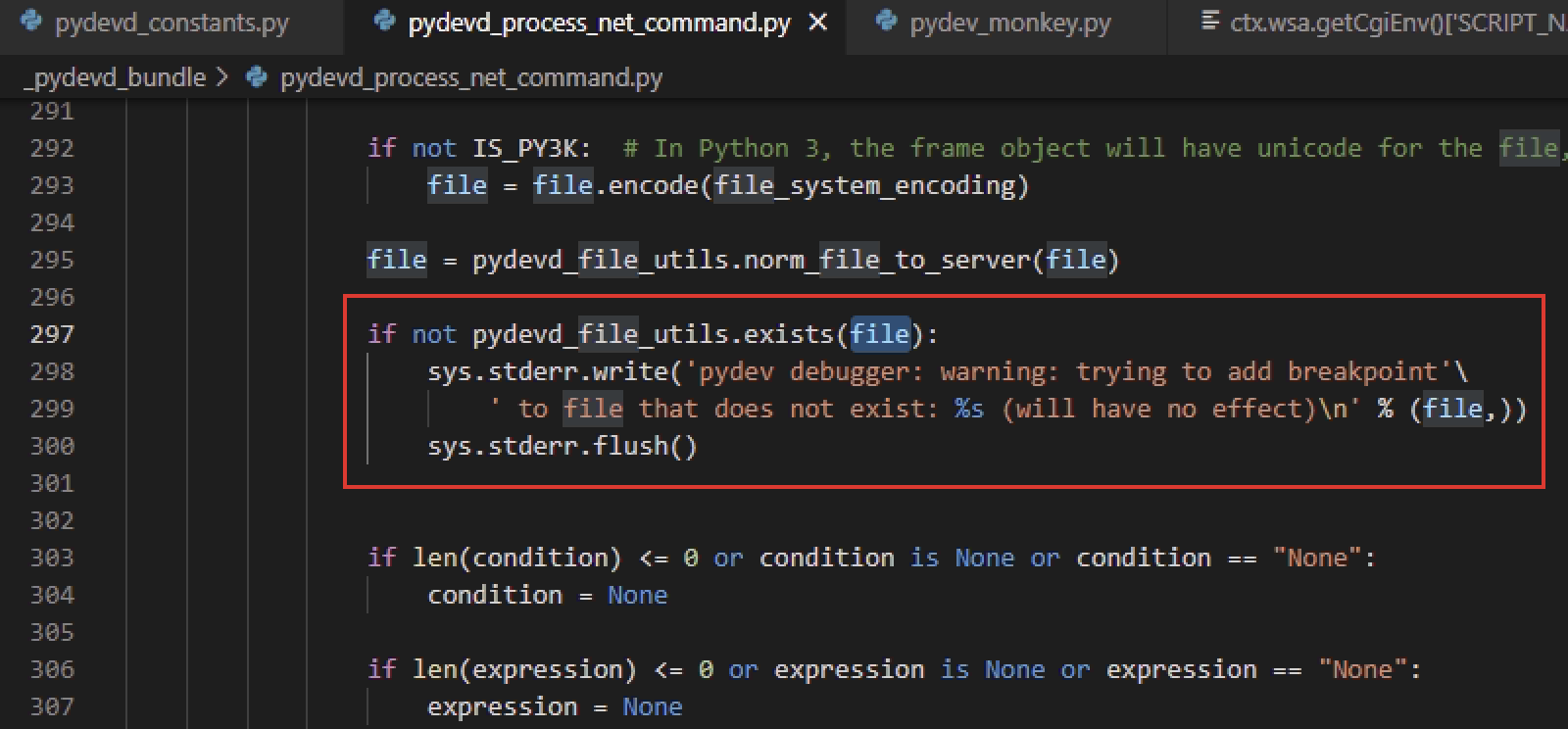
再把这样的文件重新打包回去,可以正常调试,但是下的断点无效,根据输出信息定位到pydevd的如下位置,pycharm会把本地文件经过目录映射后作为断点文件名传递给调试线程,此处会判断文件是否存在,于是把文件上传到对应位置即可(感觉注释掉这行判断也可以,未验证):
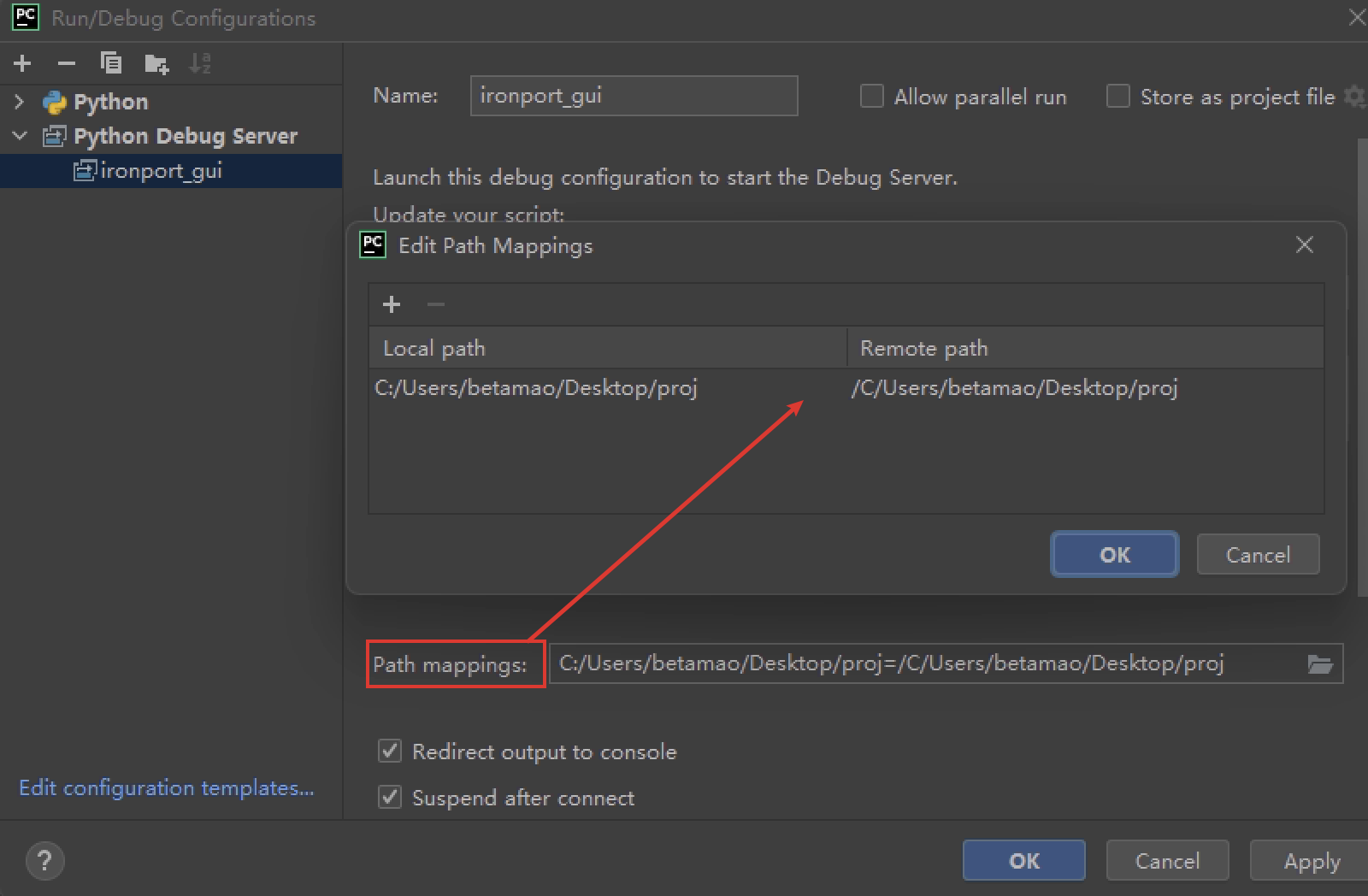
至于要上传的文件位置,上一步修复行号表时已经顺带设置了,在pycharm里设置对应的映射如下图,之后再把文件上传到ironport的这个位置即可。
但是之后发现后续产生的并发不追踪,已经提到python的trace机制需要为每个线程执行追踪,pydevd用猴子补丁实现了标准库的追踪,而此时调试的目标coro不是标准库没有被打补丁,最初想着它实现协程只需要在工作线程里启用追踪,但是无效,又猜测是用多线程伪装的假协程就在所有线程里追踪还是失败了,最后读了下源码发现coro的实现方式是为每个协程生成新的帧/栈/指令指针,这个新的帧没有继承注册的trace方法(上一步注册又写错代码所以失败了),于是直接在想要调试的那个协程里再次注册,这里选择在GUIHTTPHandler里去追踪,即添加如下代码:
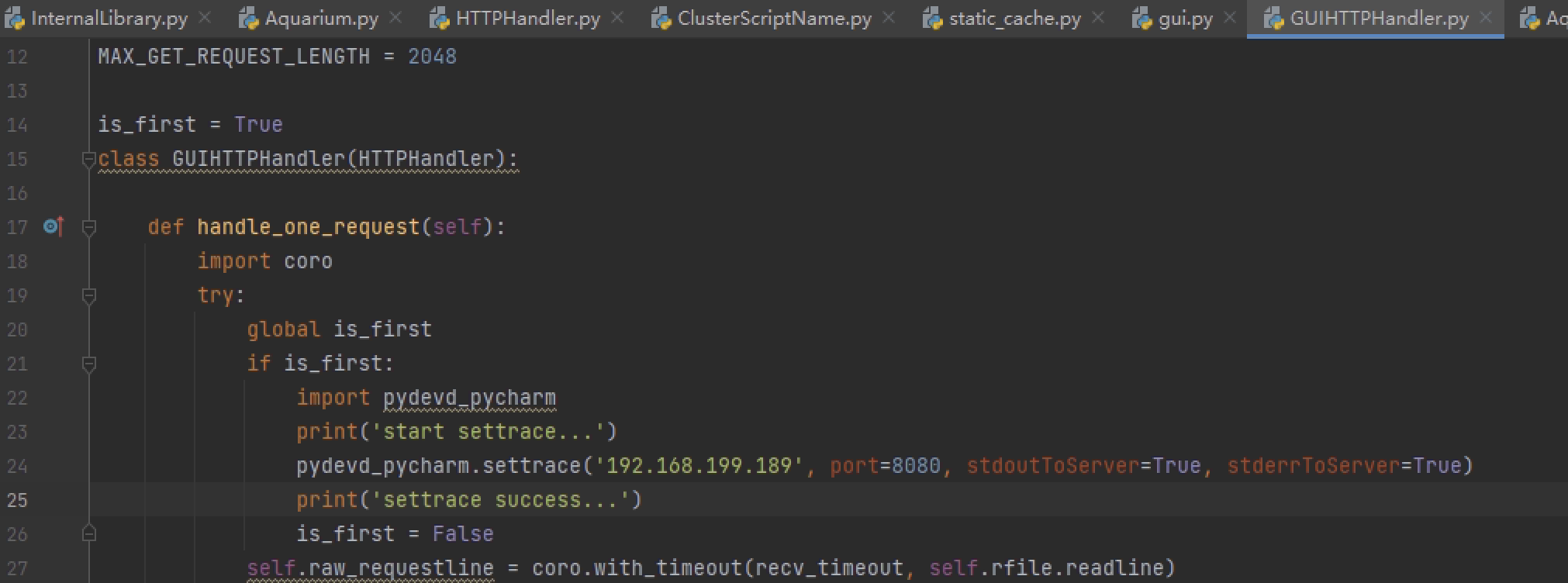
注:此处也可以直接用猴子补丁去封装coro的spawn和new方法,让其在执行协程方法func前先执行注册...
再次启动服务,即可调试HTTP处理逻辑:
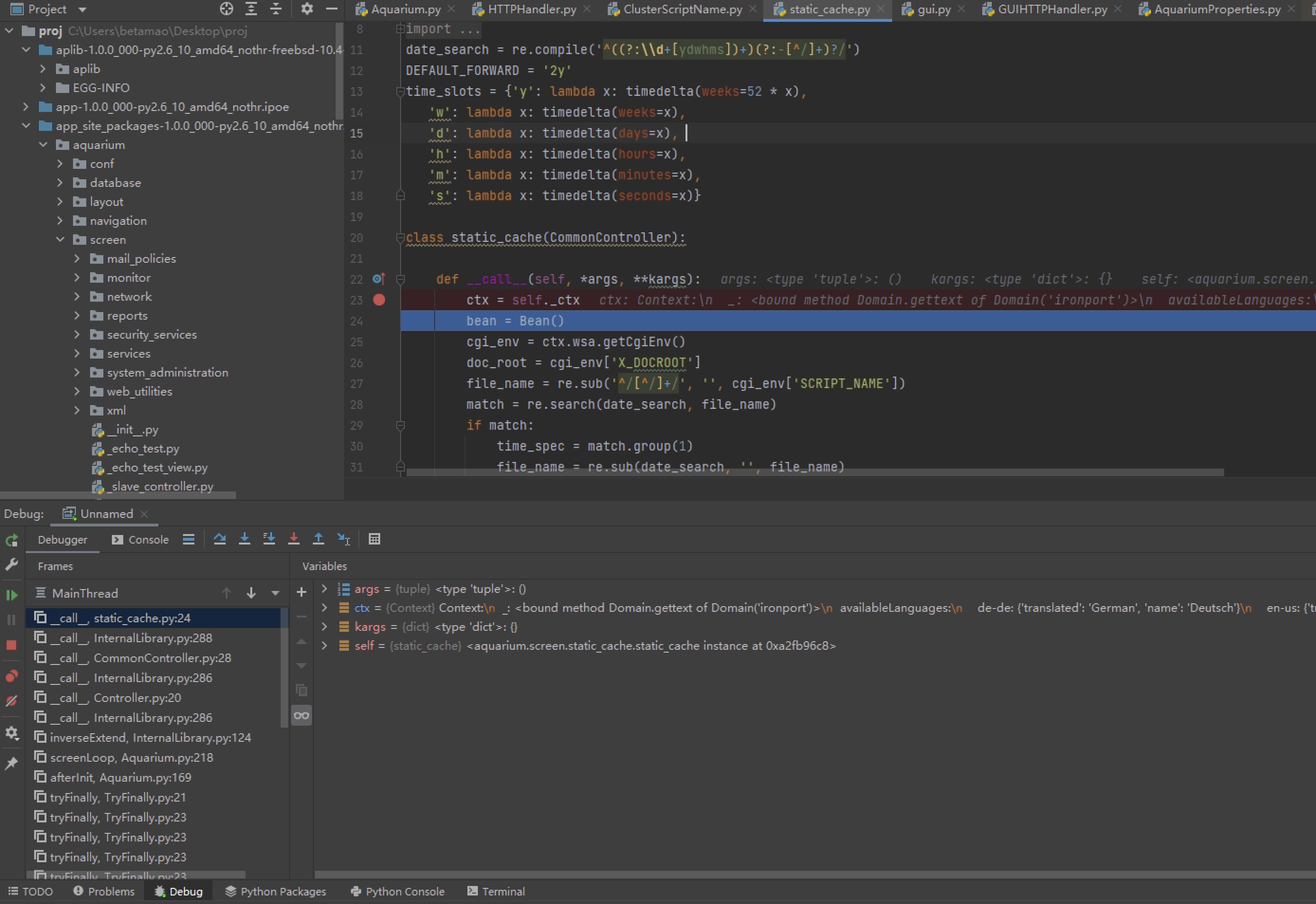
如上...完!