注:本文未完待续,部分内容等啥时遇到再写...
现在很多产品都用protobuf做序列化了,相比于xml/json等它并不是那么直观,本文描述如何分析它...
protobuf介绍
这玩意儿是谷歌发布的,它的特点就是快,占用空间小,原因就是它针对性很强,只传数据,而且是用高度优化的方式编码数据,类似于程序语言中的序列化只编组对象状态而不编码类描述,protobuf也是如此,它会使用TAG为每个域编号,序列化时只编组编号与值而不再有其他信息,解析方按固定的偏移解析数据(解析代码写死的),整个过程不再需要描述信息因此算是对人类不友好了...
语法
protobuf使用时,是先编写.proto文件,它使用proto语法,在该文件里主要定义message与service,之后再使用编译器protoc将.proto编译为需要的目标语言,如.py/.java/.go等,开发时就可以在对应的项目中导入protoc生成的代码来进行序列话与反序列化操作了,而本文主要聚焦的也是.proto文件的恢复。
message
在定义数据类型时主要用它,它类似于一个结构体,如下:
message SearchRequest {
required string query = 1;
optional int32 page_number = 2 [default=0];
optional int32 result_per_page = 3;
}
它里面可包含多个域,每个域有类型,名称与编号,其中名称并不重要,编号不可重复,而类型有如下种类:
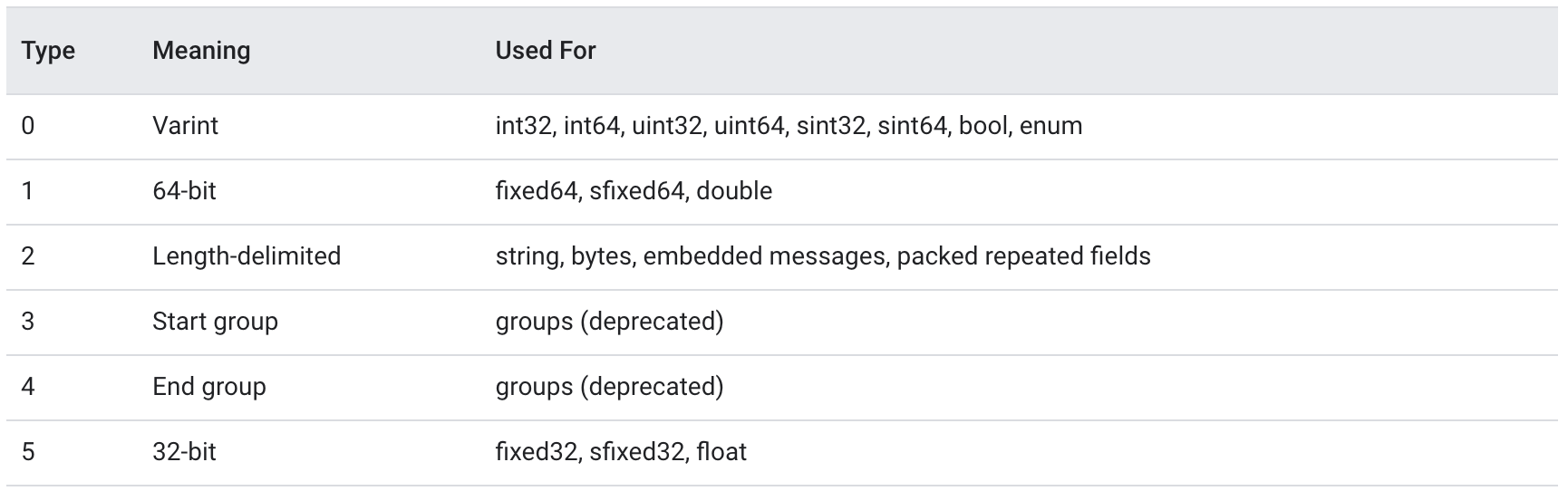 Used For列是可用的类型。回到上面的定义,
Used For列是可用的类型。回到上面的定义,query = 1的1不是值为1而是它的编号为1,required表示这个域一定要存在,protobuf在反序列化时并不是顺序读取并填充对应域,而是逐个读取域并根据编号为指定域赋值,因此当没有required关键字时可以不传递该域的数据,同样也可以多传输一些不存在域的数据,此时protobuf会直接抛弃它!另外常见的语法是option,它类似注解置于域定义之后,有一些内置的选项如上的default表示默认值,用户可以自己定义选项,通过这些可以指定编译器做一些自动化工作,如protobuf与json转换等。
message就是用来表示数据的,随便找两个proto文件就能看懂了,因此不再赘述...
service
既然用到protobuf,那么大多数情况都会带着RPC,同样也是用proto去写接口,再用编译器生成stub和skeleton,这里面常见的是百度的bRPC和谷歌的gRPC,这个以后再写...
service SearchService {
rpc Search(SearchRequest) returns (SearchResponse);
}
编码
这个可以看401的文章,这里借他的图简单说下:
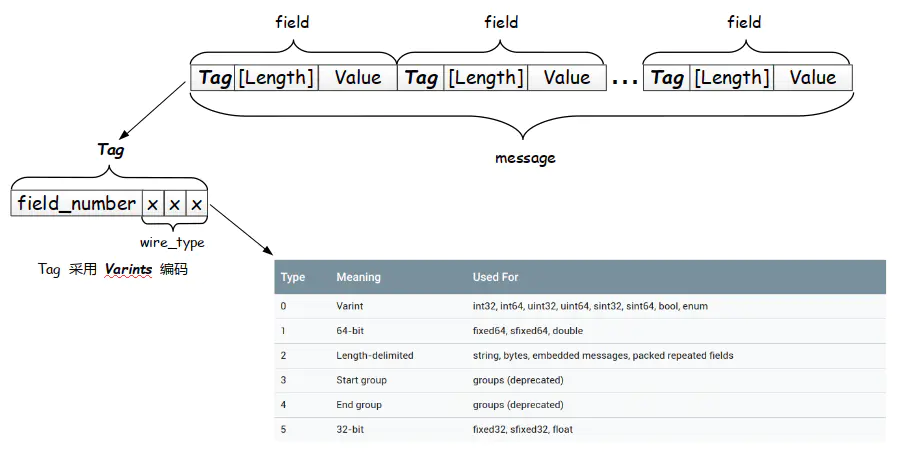 先看又下图,和上面贴的图内容一致,尽管在语法上有很多类型可用,但是在proto序列化时,实际只有6种类型(其中两种还废弃了),如当使用int32/int64等时,其实它都属于Varint类型,这里面要注意sint32和sint64,和C语言一样,它们在底层和int32/int64是一样的,只是解释方式不同,前者使用ZigZag来编码优化了负数的空间效率,因此当我们在不知道proto描述而解析一个序列化后的数据时,并不知道它到底是有符号还是无符号,从而得出截然不同的含义,此时需要自己判断。再看类型2它包含4类类型,其实就是先写长度再放值数组。
先看又下图,和上面贴的图内容一致,尽管在语法上有很多类型可用,但是在proto序列化时,实际只有6种类型(其中两种还废弃了),如当使用int32/int64等时,其实它都属于Varint类型,这里面要注意sint32和sint64,和C语言一样,它们在底层和int32/int64是一样的,只是解释方式不同,前者使用ZigZag来编码优化了负数的空间效率,因此当我们在不知道proto描述而解析一个序列化后的数据时,并不知道它到底是有符号还是无符号,从而得出截然不同的含义,此时需要自己判断。再看类型2它包含4类类型,其实就是先写长度再放值数组。
现在回头来看图,一个序列化数据是一个个field组成的,而一个field由三部分组成:TAG-Length-Value,TAG包含了域的编号与域的类型,这里的类型就是上图表格里的Type,可以看到它并不会包含具体的类型信息,它只是为了指导反序列化如何读后续的Length与Value罢了。
图里Variant编码多次出现,它是指变长整数值,类似UTF8编码,用最高位来表示是否读完单个值,而具体值使用补码编码。
反射
类似一些其他编程语言,protobuf也支持反射,通过反射能实现更灵活的功能,还能减少生成的目标代码量,而要使用反射就要有元信息,这些元信息保存着.proto里定义的各种描述信息,这里依然可以看401的文章,简单的说,如使用Message的反射功能,则是先获取到Message的描述信息,这一般通过名字从某个字典里查询或通过某指针计算得到,知道它才能知道某个域的偏移(如通过域的名字找到域),之后再获取Message的实例,对其进行读取或赋值操作:
// 直接通过类的方法获取描述符
const Descriptor* descriptor = pb.GetDescriptor();
const Reflection* reflection = pb.GetReflection();
// 使用描述符,通过名字获取到与描述符,从而对其进行赋值操作
const FieldDescriptor* fool_field = descriptor->FindFieldByName("fool");
reflection->SetInt32(&pb, fool_field, 233);
支持反射,编译器会解析.proto文件为描述符,将其序列化作为常量值,在运行时反序列化为描述符对象并注册到一个字典来实现动态特性,这里是常量值也就意味着它是代码的一部分会一直在目标程序中,不会被strip等方式去除。
关于protobuf的基础知识可见官方文档或翻译版本,此处不再多说。
逆向分析
通过元信息
上面提到在支持反射功能时,会保存proto描述信息的元信息,因此若目标存在反射功能时,通过直接提取这些元信息即可直接恢复出.proto
Protobuf为例
上面已经提到protobuf是平台无关的,而描述符是protobuf序列化存储,因此用protoc生成的所有语言的描述符序列化数据都是通用的,只要能被定位到就能使用通用的方式提取,存在自动化的工具pbtk,它支持图形化和命令行启动,前者需要安装很多包没必要,直接使用命令行的方式就好了,它自带了三个提取器,可分别用于从二进制/Jar包/Web方式提取信息。
Python实例
python基本能拿到源码,也就是.proto编译后的文件,一般以xxx_pb2.py的文件,打开该文件其实可以手动构造回.proto,但是有更简单的方式,直接定位到serialized_pb:
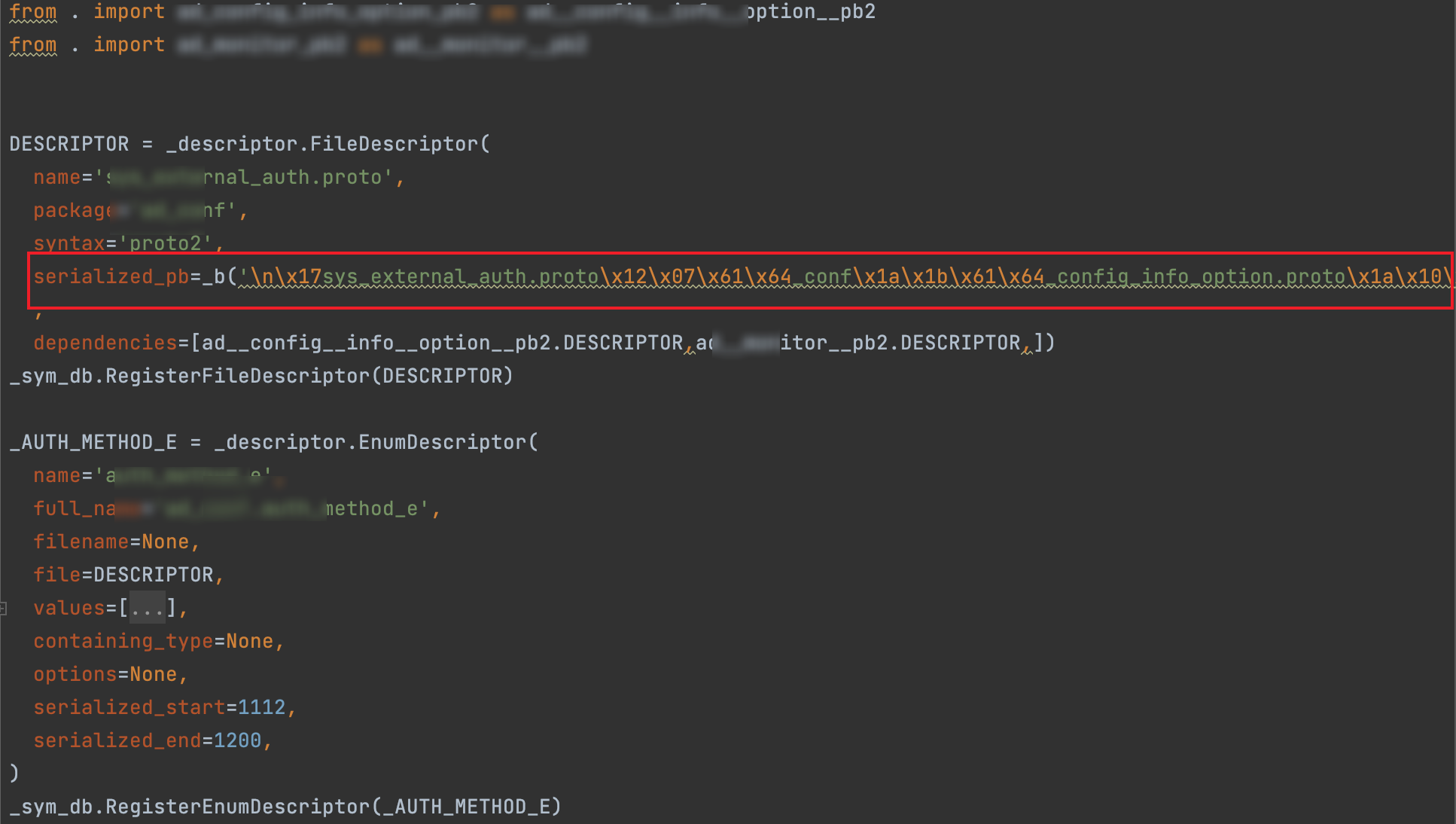 它就是序列化后的描述符,通过它可以恢复出.proto,其实就是借助pbtk,新建一个提取器,运行即可获取相应的.proto:
它就是序列化后的描述符,通过它可以恢复出.proto,其实就是借助pbtk,新建一个提取器,运行即可获取相应的.proto:
def walk_pb2(path):
try:
with open(path, 'rb') as fd:
binr = fd.read()
except Exception:
return
pb = re.findall(br'serialized_pb=_b\((.+)\)', binr)
for item in pb:
data = eval(b'b'+item) # 怕了吗?
# Parse descriptor
proto = FileDescriptorProto()
proto.ParseFromString(data)
# Convert to ascii
yield descpb_to_proto(proto)
Protobufc为例
protobufc是protobuf的C实现,在很多C代码中会常用,它与Google的实现方式不同,但是依然很好分析,它存在三个魔数:
class ProtobufMagic(object):
PROTOBUF_C__SERVICE_DESCRIPTOR_MAGIC = 0x14159bc3
PROTOBUF_C__MESSAGE_DESCRIPTOR_MAGIC = 0x28aaeef9
PROTOBUF_C__ENUM_DESCRIPTOR_MAGIC = 0x114315af
通过它就可以定位到对应的描述符,这里简单贴下代码:
def autoParseAllMessage():
start_addr = get_imagebase()
magic = ProtobufMagic.PROTOBUF_C__MESSAGE_DESCRIPTOR_MAGIC
magic = b2a_hex(pack('>I', magic)).decode()
while True:
addr = find_binary(start_addr, SEARCH_DOWN, magic)
start_addr = addr + 1
if addr == BADADDR:
debug('scan finish...')
break
if not isMessage(addr):
continue
debug('find addr {}'.format(hex(addr)))
try:
parseMessageDescriptor(addr) # 解析所有message描述符
except Exception as e:
debug('addr {} err: {}'.format(hex(addr), e))
auto_wait()
def parseMessageDescriptor(addr):
STRUCT_NAME = 'ProtobufCMessageDescriptor'
if get_type(addr) == STRUCT_NAME:
return True
get_int_val = partial(getFieldIntVal, addr, STRUCT_NAME)
assert get_int_val('magic') == ProtobufMagic.PROTOBUF_C__MESSAGE_DESCRIPTOR_MAGIC
if not setType(addr, STRUCT_NAME):
debug('set addr "{}" type "{}" failed'.format(hex(addr), STRUCT_NAME))
return False
n_fields = get_int_val('n_fields')
fields_addr = get_int_val('fields')
FIELD_DESCRIPTOR_SIZE = getStructSize('ProtobufCFieldDescriptor')
# setStructArr(fields_addr, 'ProtobufCFieldDescriptor', n_fields)
for i in range(n_fields):
addr = FIELD_DESCRIPTOR_SIZE * i + fields_addr
parseFieldDescriptor(addr) # 解析对应的域
详细代码我粘Gist上啦。
struct {
descripter;
reserved;
feilds[];
}
自行分析
尽管反射是默认的编译选项,但是也可以禁用反射功能,此时就不会再保存元信息了,此时就需要自己去分析...
第一步:获取数据格式
这是最关键的一步,上面已经提到protobuf在通常的使用过程中是不需要描述信息的,通过传输的数据或存在的代码就可以完全恢复出数据的格式,这个可以手动分析,直接用protoc可解码抓到的合法包:
protoc –decode_raw < cap.bin
也有在线工具[tool_1][tool_2]可以解,编程可使用blackboxprotobuf或protobuf库的解析功能,大多数时候通过它解析出结果再修修补补就可以进行测试了,也不必关注.proto文件的定义。
注:1. 在gRPC-h2中抓的包可能是压缩的无法直接解析,需要先解压再解析。 2. 可能一个包里存在多条序列化的数据,此时需要将其分割再处理,此时它可能会采用length-prefix方式组合,也可能是其他方式需要具体分析啦。
第二步:分析域名称
这个名字其实就是自己遍,有符号就用符号,比如符号表没去除那么其实每个功能都会有相应的函数,通过函数名就能知道域名称,没有就只能自己猜了...