TRACE
在进行程序分析或排错时,trace是必备的工具,使用它可以快速了解程序运行情况,发现问题点,例如常见的跟踪open函数就能知道它尝试打开哪些文件,结果如何,文件打开顺序是什么,再跟踪read就知道它以怎样的顺序读取了哪些数据。
在Linux下最常见的就是strace与ltrace,前者用于跟踪系统调用与信号,后者增加了动态库跟踪。它们全都使用了Linux提供的调试接口,ptrace机制,对于strace它的实现就很简单了,因为系统本来就提供了syscall的追踪,所以它只需要设置ptrace参数就可以实现上述功能,而ltrace更加复杂,查看它的源码会发现HOOK了PLT,于是调用动态库函数也就能被追踪到了。
这两个轻量追踪工具是程序分析的必备工具,但是它们全都使用了ptrace机制,作为一种系统提供的调试机制,linux实现中是一个进程最多只能同时被一个进程调试,也就意味着它们不能同时使用,也不能与其他调试工具,如gdb同时使用,更进一步若程序自带反调试那么此时需要先Bypass它。由于他们是多进程间通信,且必须要先陷入内核,因此代价极大,另外就是它们的功能比较固定难以扩展,它们实现了这几种操作的跟踪但是要追踪其他指定的函数比较困难,而且当前它只支持监视不支持修改。

在windows上同样有很多跟踪工具,比较常用的是sysinternals套件与apimonitor,没深入分析过他们原理但是思想应该类似:
动态二进制插桩
上面提到strace与ltrace的优点与不足,而二进制插桩工具就能弥补它的不足。动态二进制插桩(Dynamic Binary Instrumentation,DBI)是一种在程序运行时向二进制文件中插桩的技术,其中的Instrument原意是仪器,表示获取内部运行信息,翻译为插桩可能是通过插入代码来实现此功能,其实这种技术的目的就是直接监视/修改运行中的二进制程序,监视是获取运行的信息,如寄存器上下文,内存,文件读写等,而修改就是改变原有逻辑,就是一种HOOK方式,其实调试器也能实现这些功能,但是调试器依赖硬件与系统软件实现,并且是不同进程间通讯,而插桩是直接把桩代码植入目标程序内,这会有更好的性能与隐蔽性!
二进制插桩框架很多,如QBDI,Triton,Valgrind,Dyninst,Dynamorio,Pin,Frida等,其中QBDI可以对指令和代码块进行插桩从而和Frida互补,Triton插桩用的Pin,它更出名的是污点追踪,符号执行与约束求解功能;Valgrind更多作为一个Sanitizer检测器用;Dynamorio是惠普和MIT合作的,Pin是Intel与Virginia合作的产品,据说它们前者速度快后者更稳定,我总感觉Pin作为Intel家的产品应该速度会更快呢,嗯,这两个我都没用过,我选Frida!
其实除了调试与插桩外,还有其他方式也能实现监视与修改的功能,比如用Qemu,Qemu的硬件虚拟化倒是与调试很像,而软件虚拟化模拟执行就可以在解释到感兴趣的点时实现额外的功能,另外还有就是硬件机制,如Intel的Trace Process,这个我又不懂了。。。
FRIDA
介绍
上面提到很多插桩框架,而选择Frida是因为它实在太方便了,它有如下特点:
- 丰富的语言绑定,在最求性能或实现一些底层功能时可使用C/C++,这点可以看每个devkit例子,而除此之外它的后端还提供了Python/JS/.NET/Swift等语言的绑定,可以任意选择一种语言实现高级功能。
- 优秀的跨平台能力与支持多种语言,它支持Native(x86/arm/mips/aarch)架构(使用capstone进行反汇编),支持windows/Mac/IOS/Linux/Android/QNX等平台,支持Native/Java(dalvik/art/hotspot)和Objc等语言。
- HOOK接口使用JS实现,相比C/CPP编写与调试都方便了很多,在使用V8时它有兼容的调试接口可以直接调试JS,而且JS异常捕获导致语法错误不会影响被跟踪程序,另外还有大量的库可供直接使用,node的包管理机制也很容易分享hook代码。frida最初使用V8引擎作为JS运行时,作为宇宙第一JS引擎它的语法支持与性能自然不必多说,但是它的开销比较大,而且JIT需要RWX权限,因此为了在某些环境下运行引入了duktape,它的最大缺点就是只支持ES5标准,于是之后被quickjs替换,现在quickjs是默认运行时,在执行脚本时可以通过runtime修改。在使用v8引擎时,可添加
--debug,此时通过chrome等客户端对js进行调试。 - 开源,在遵从开源协议的前提下随便改,不像pin只提供了API,frida完全开源而且代码组织非常合理,因此可以很方便的增加自己的功能。
- 天生反调试特性,首先它不依赖调试机制(若使用注入机制会短暂的使用调试机制),它和目标进程在同一进程空间,因此通过系统调试机制的特性对抗分析将失效,而且它的很多设计也考虑到了反调试,详见作者官方文档。
- 为了避免虚拟机切换的开销,在hook时可以直接使用native代码,如使用xxwriter直接写汇编,也可以使用Module去加载自己编写的动态库,为了可移植性,frida内嵌了TinyCC,因此可使用CModule直接嵌C代码,如果觉得它的效率不行,也可以用gcc/clang去编译CModule(其实和so差不多了),此时可用
frida-create cmodule去生成模板。
注:用Native代码是为了降低虚拟机切换的开销,实际上V8的JIT在运行一段时间后性能并不弱于(甚至更强)C编译后的。
功能:
- Trace功能,允许跟踪线程,捕获每个函数、每个块,甚至每个执行的指令。除了跟踪代码之外,它还允许您在任何地方添加和删除指令。
- 不需要源码与调试信息就可以插桩,插桩后可查改任意内存/寄存器
- HOOK功能,可查改任意函数的参数,返回值,修改函数逻辑,也可以直接调用任意函数,比如某函数实现解密功能,之前可以用代码提升或用LIEF之类的工具将其导出再调用,但这可能需要处理很多环境问题,而Frida可以直接在原环境内存中调用任意函数,并且这不限于native代码,也包括Java与objc。
- ...
原理
它的架构图如下:
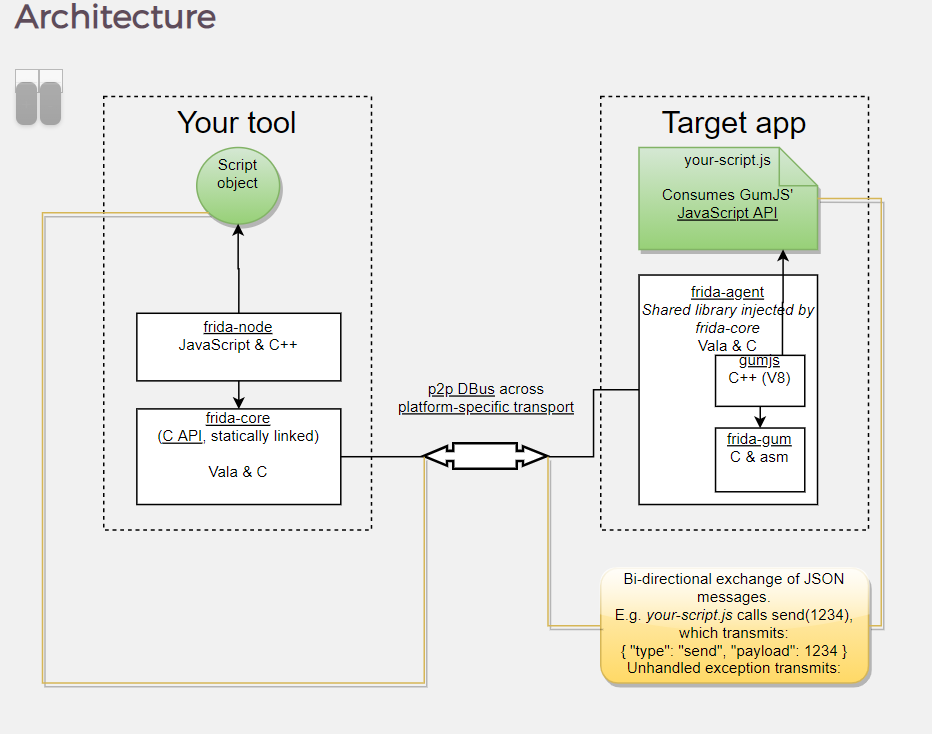
它分为两部分,调试端与目标端,调试端核心是frida-core,它由C和Vala编写,它负责注入frida-agent到目标进程,并使用PIPE等方式通信,用户工具使用frida的语言绑定与frida-core交互,在frida-agent里它的核心是frida-gum,它由C&ASM实现插桩功能,不过我们一般是使用GumJS提供的API来实现HOOK,它算是一种绑定吧,上面已经提到了它的优点。
对于用户,下面是一种更直观的视图,它演示了接下来要说到的Inject模式时的视图:
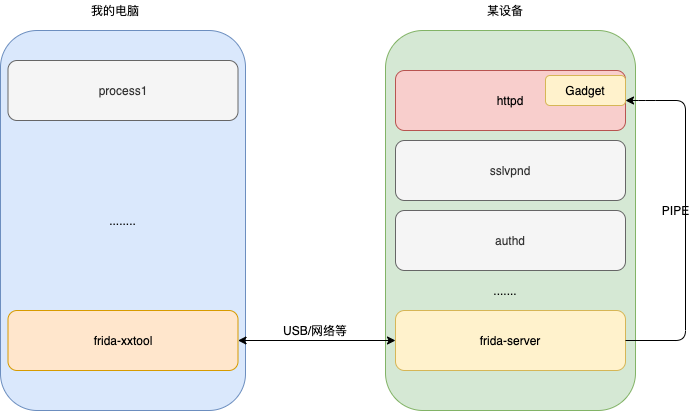 frida-server在目标系统的全局运行,Agent(Gadget)被注入到目标进程中,它们通过管道通信,另外用户编写的工具通过网络等方式与frida-server通信,frida-server此时作为一个代理处理用户与目标进程间的通信。
frida-server在目标系统的全局运行,Agent(Gadget)被注入到目标进程中,它们通过管道通信,另外用户编写的工具通过网络等方式与frida-server通信,frida-server此时作为一个代理处理用户与目标进程间的通信。
操作模式
它支持三种注入方式,它通过将核心功能编译为动态库(Gadget)并注入到目标进程,再使用额外的线程执行HOOK等操作,所以此处的注入就指是把这个动态库注入:
- 修改目标二进制文件(Embedded),把核心直接嵌入/索引到二进制文件里,它在启动时就会加载它。
- 使用系统链接特性(Preload),如使用
LD_PRELOAD或DYLD_INSERT_LIBRARIES等方式加载Gadget库 - 使用远程代码注入技术(Inject),它需要有对应的权限,并且会短暂的使用调试机制,但是能直接操作正在运行,不能重启的进程。
非远程注入
在注入模式不好用的时候,如某程序是init进程,不便在它初始化前对其插桩,此时可以使用此方式,它提供一个gadget.so,可以通过打补丁等方式注入到目标,并在目标执行前执行插桩操作,它默认会在进入目标逻辑前挂起程序,并提供frida-server兼容的TCP调试接口,因此可以和注入模式一样进行插桩操作:
# 通过链接器注入
root@bm:~/frida/build/frida-linux-x86_64/lib/frida/64# LD_PRELOAD=./frida-gadget.so cat
[Frida INFO] Listening on 127.0.0.1 TCP port 27042
# 与frida-server方式不同,此时它只有一个名为Gadget的进程
root@bm:~/frida# frida-ps -R
PID Name
----- ------
98367 Gadget
# 使用frida-trace追踪,此时会恢复挂起的程序
root@bm:~/frida# frida-trace -i read -R Gadget
Instrumenting...
read: Auto-generated handler at "/root/frida/__handlers__/libc_2.31.so/read.js"
read: Auto-generated handler at "/root/frida/__handlers__/libpthread_2.31.so/read.js"
Started tracing 2 functions. Press Ctrl+C to stop.
/* TID 0x18348 */
5428 ms read(fd=0x0, buf=0x7f57340e2000, count=0x20000)
6830 ms read(fd=0x0, buf=0x7f57340e2000, count=0x20000)
在此时它有四种工作模式,第一种如上会监听一个端口等待客户端连接,还有一种常用的模式是自动执行某路径的插桩脚本,这可以通过与库同名的配置文件指定,具体配置项见文档。
注入
这里多说说第三种方式,它就是远程代码注入(远程DLL注入)
- 获取权限,这在windows下需要管理员权限使用
AdjustTokenPrivileges获取调试权限,Linux为root即可 - 使用如
ptrace或OpenProcess调试函数附着目标进程,此时会劫持其线程 - 在被劫持线程上,调用mmap等获取一片内存,该内存需要有读写执行权限(由于操纵其他进程,此时需要解析其地址)
- 将bootstrapper代码注入该区域
- 执行bootstrapper后,它会装载
frida-agent并创建新线程去执行它 - 恢复原线程,此时完成
frida-agent注入,它以一个单独线程运行,并使用命名管道与客户端通信。
它的屁屁踢里有演示这个过程:
1.debugger(frida-server)和debuggee(目标)互不侵犯:
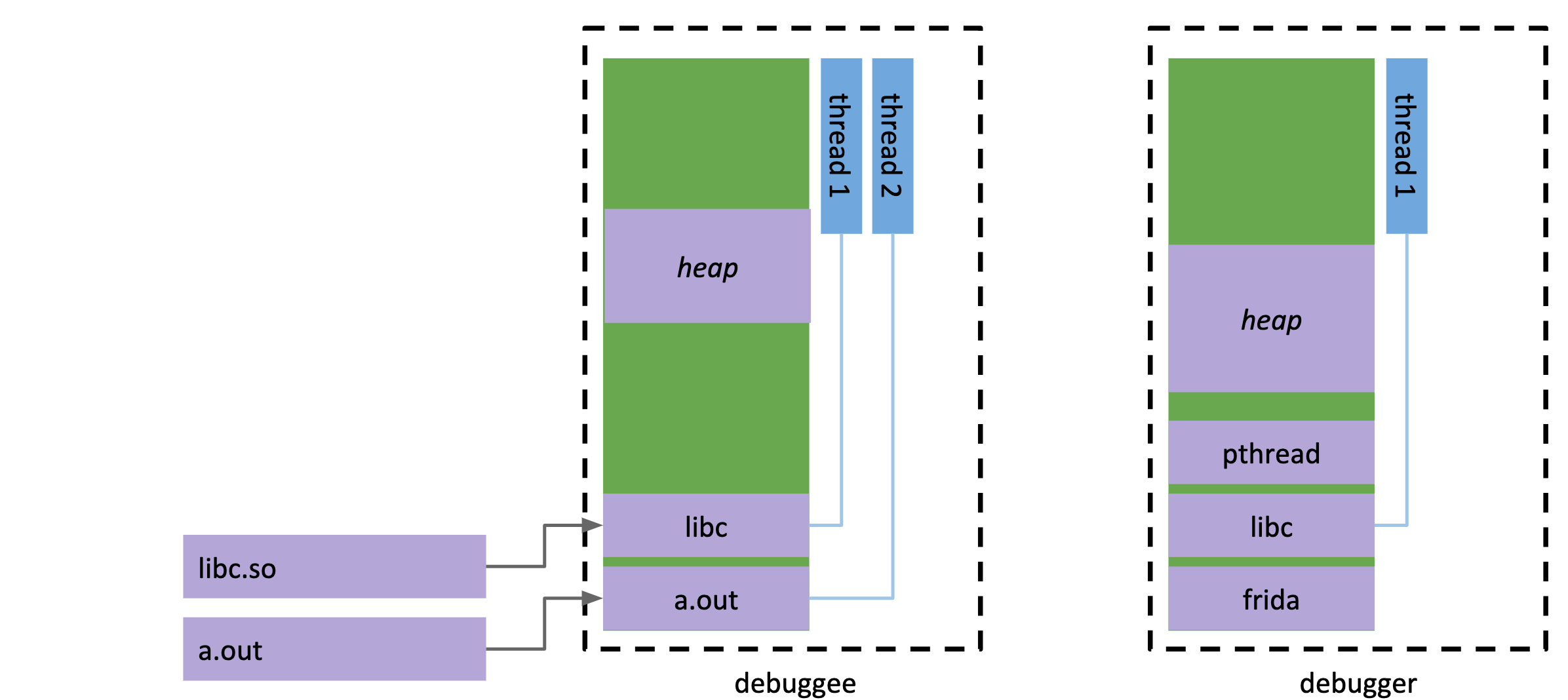 2.debugger释放它体内的agent.so(gadget)到一个临时文件夹
2.debugger释放它体内的agent.so(gadget)到一个临时文件夹
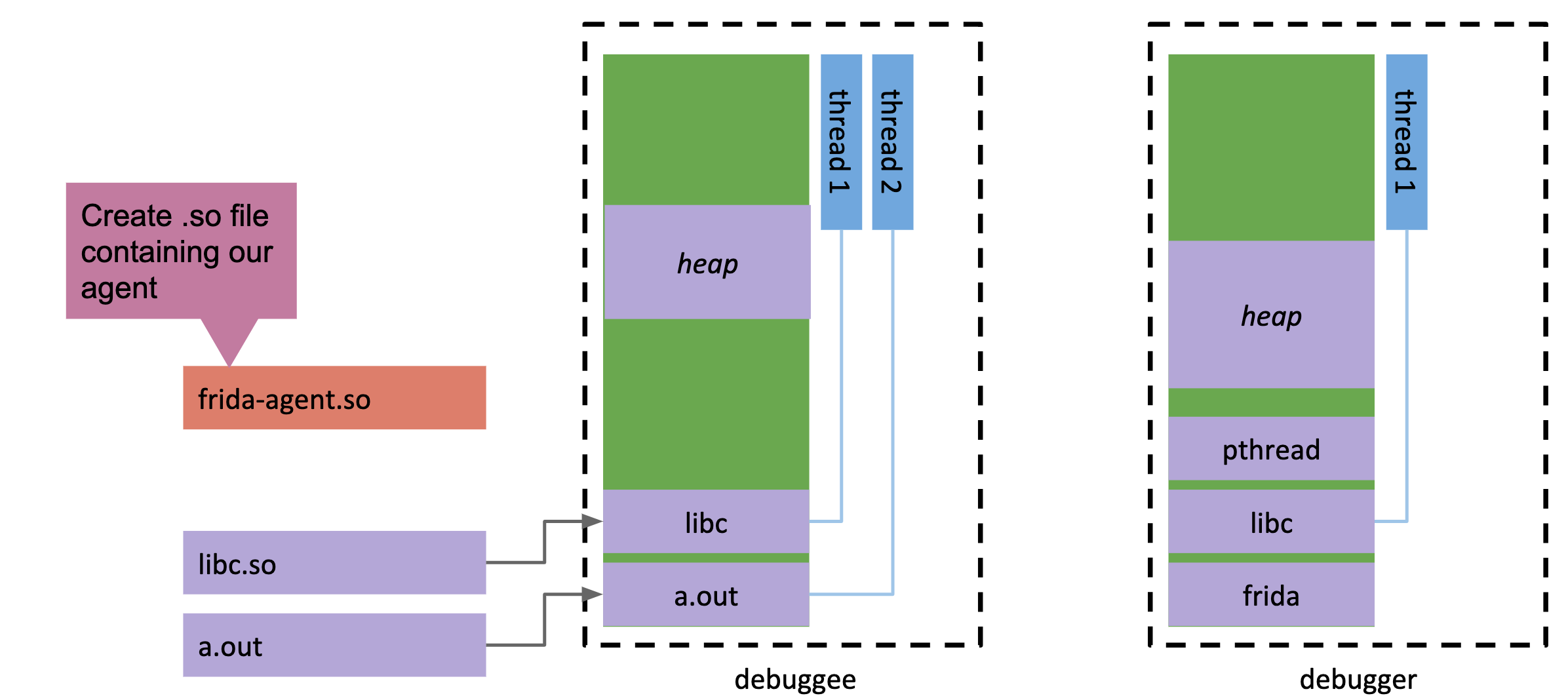
3.debugger通过调试接口附加到debuggee上,此时debuggee会挂起,debugger在debuggee中申请一片空间,并把bootstrapper代码填入:
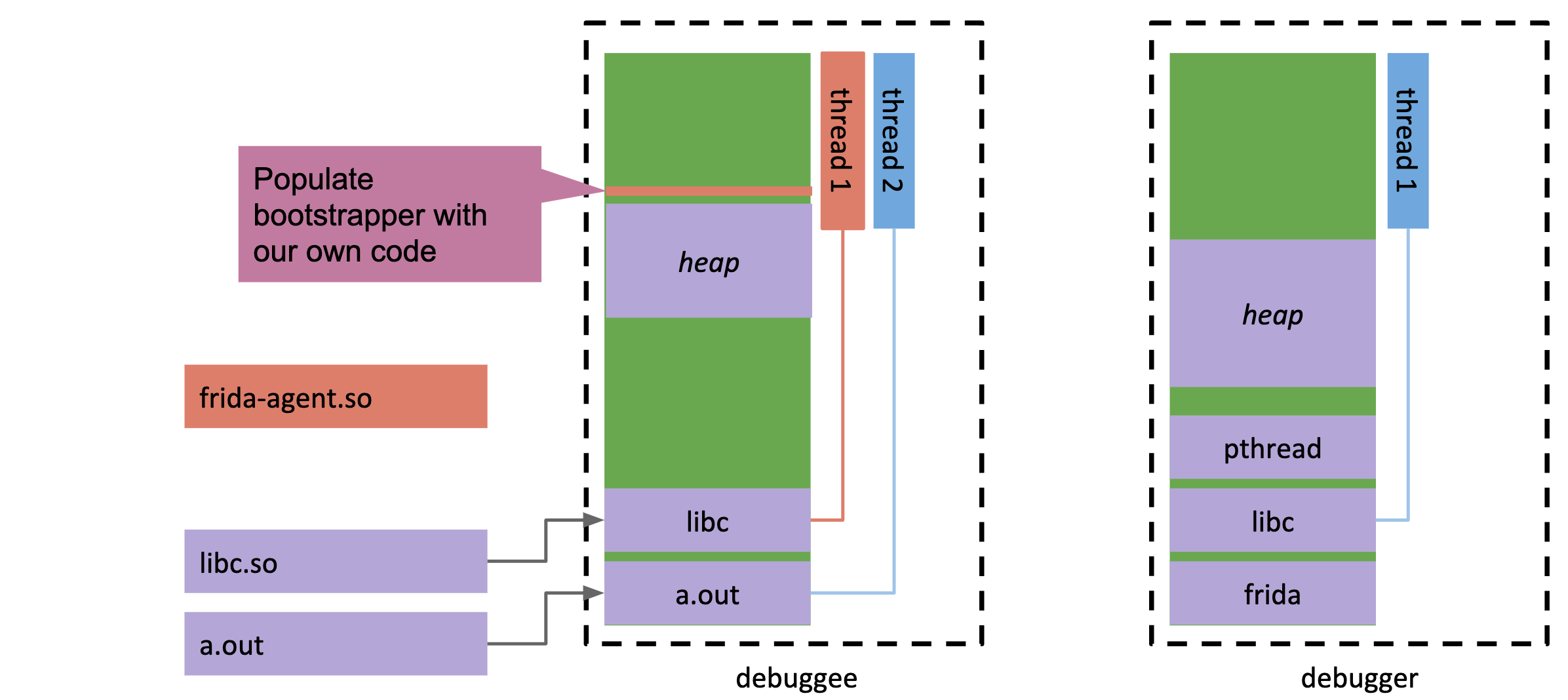 4.debugger修改debuggee的pc令其执行bootstrapper的代码,这段代码的作用是创建新的线程并通过FIFO与debugger通信,新线程将加载agent到debuggee中:
4.debugger修改debuggee的pc令其执行bootstrapper的代码,这段代码的作用是创建新的线程并通过FIFO与debugger通信,新线程将加载agent到debuggee中:
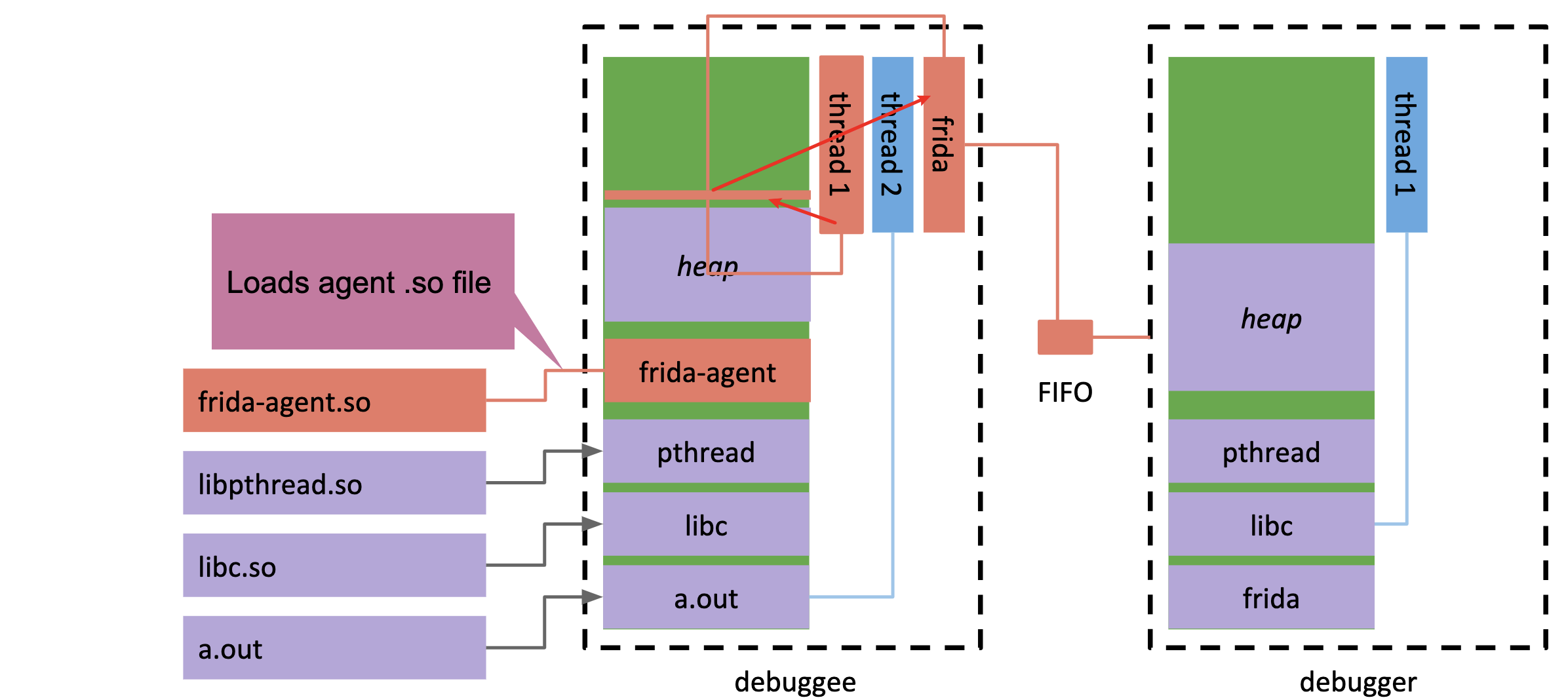 5.新线程在加载so时会初始化并执行它的代码,而debugger就可以选择恢复原来的线程,让它们继续执行:
5.新线程在加载so时会初始化并执行它的代码,而debugger就可以选择恢复原来的线程,让它们继续执行:
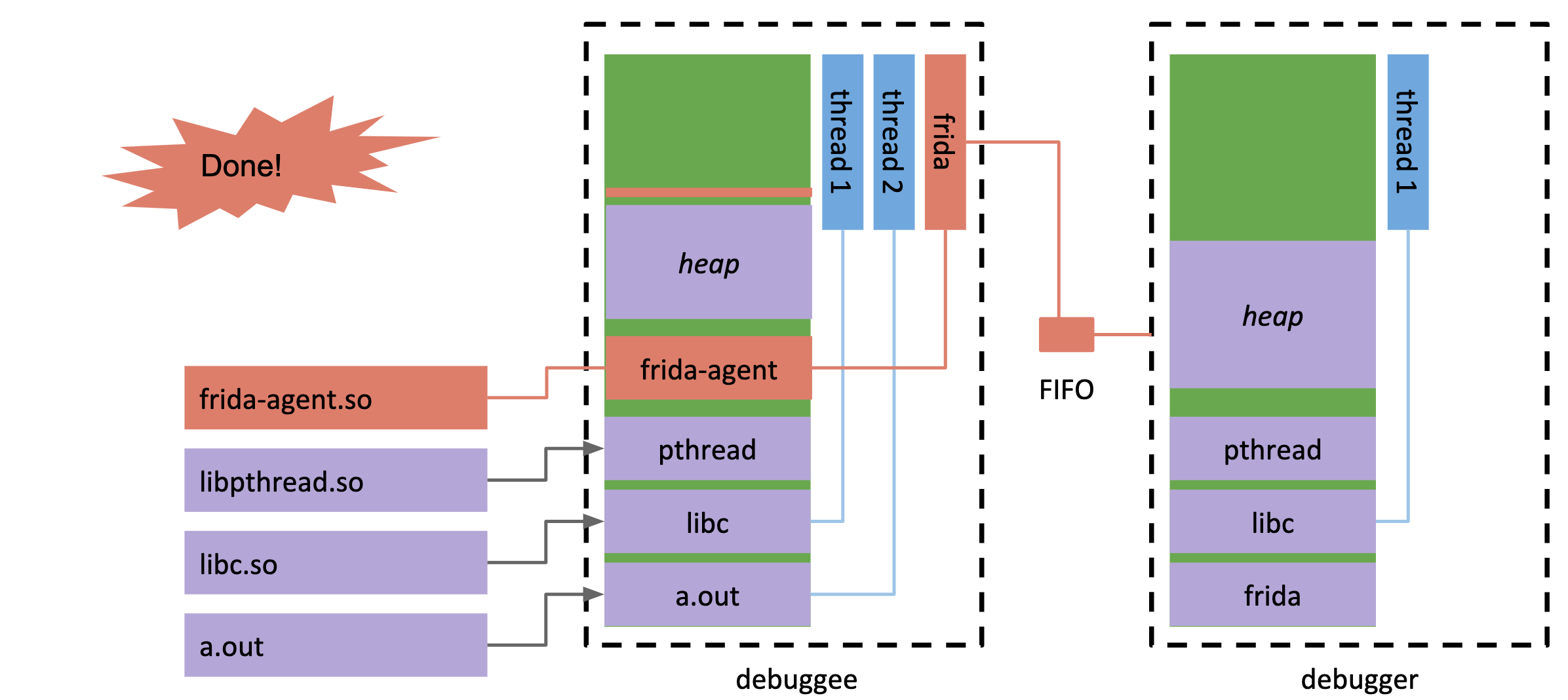 Linux上关键部分的代码如下,它位于frida-core仓库下:
Linux上关键部分的代码如下,它位于frida-core仓库下:
/* 附着到目标进程上*/
ptrace (PTRACE_ATTACH, pid, NULL, NULL);
waitpid (pid, &status, 0);
/* 保存线程的原始上下文 */
ptrace (PTRACE_GETREGS, pid, NULL, saved_regs);
/* 解析目标的mmap位置并调用以分配一块可读写执行的内存,此时它还是用的原线程的栈 */
ptrace (PTRACE_GETREGS, pid, NULL, ®s)
regs.rip = resolve_remote_libc_function (pid, “mmap”);
regs.rdi = 0;
regs.rsi = 8192;
regs.rdx = PROT_READ | PROT_WRITE | PROT_EXEC;
regs.rcx = MAP_PRIVATE | MAP_ANONYMOUS;
regs.r8 = -1;
regs.r9 = 0;
regs.rax = 1337;
regs.rsp -= 8; // 向下压栈
/* 执行mmap并获取分配到的地址*/
ptrace (PTRACE_POKEDATA, pid, regs.rsp, DUMMY_RETURN_ADDRESS) // 将无效返回地址放入栈上,用于暂停线程返回调试器
ptrace (PTRACE_SETREGS, pid, NULL, ®s)
ptrace (PTRACE_CONT, pid, NULL, NULL)
frida_wait_for_child_signal (pid, SIGTRAP)
ptrace (PTRACE_GETREGS, pid, NULL, ®s)
bootstrapper = regs.rax
/* 执行bootstrapper并等待返回,此时把栈迁移到新分配的空间了 */
ptrace (PTRACE_GETREGS, pid, NULL, ®s)
regs.rip = bootstrapper
regs.rsp = bootstrapper + 8192
ptrace (PTRACE_SETREGS, pid, NULL, ®s)
ptrace (PTRACE_CONT, pid, NULL, NULL)
frida_wait_for_child_signal (pid, SIGTRAP)
/* bootstrapper执行完毕时,已经将agent注入并运行,现在恢复原线程上下文并deattach*/
ptrace (PTRACE_SETREGS, pid, NULL, saved_regs)
ptrace (PTRACE_DETACH, pid, NULL, NULL)
bootstrapper代码如下:
// 创建并执行新线程并陷入返回调试器
so = dlopen (“libpthread.so”, RTLD_LAZY)
thread_create = dlsym (so, “pthread_create”)
thread_create(&worker_thread, NULL, bootstrapper + 128, NULL)
int3()
// 而在新的线程中,它会打开一个命名管道
fifo = open(fifo_path, O_WRONLY)
write(fifo, “frida_agent_main”, 1)
so = dlopen(“frida-agent.so”, RTLD_LAZY)
entry = dlsym(so, “frida_agent_main”)
entry(DATA_STRING)
close(fifo)
现在,frida-agent已经注入并作为一个新线程运行,这对原程序是无感的(不是说隐蔽的),并且由于在同一进程,通过命名管道,客户端可以轻易的下发指令操作目标进程。
勾子操作
还是按屁屁踢里的图,它的HOOK只有函数级HOOK,所以要处理的内容很少,如下它在函数的入口进行了修改跳到新的位置,处理完后再跳转回去:
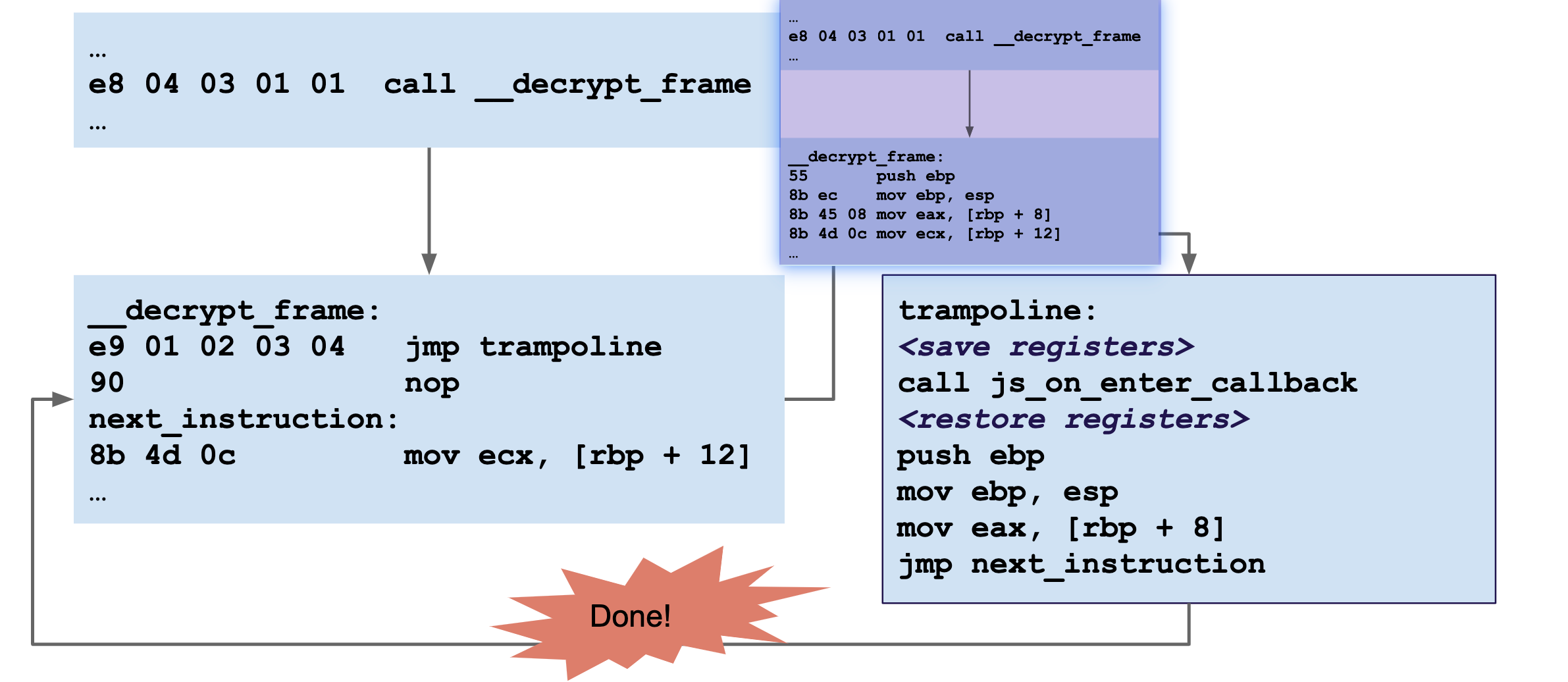 不过这实际上还有很多东西要处理,如代码的相对地址,在桩代码里获取的地址应该是原来的地址,另外还有自修改代码等问题,作者都处理了。
不过这实际上还有很多东西要处理,如代码的相对地址,在桩代码里获取的地址应该是原来的地址,另外还有自修改代码等问题,作者都处理了。
追踪操作
它的stalker是更能体现插桩,简单看如下图:
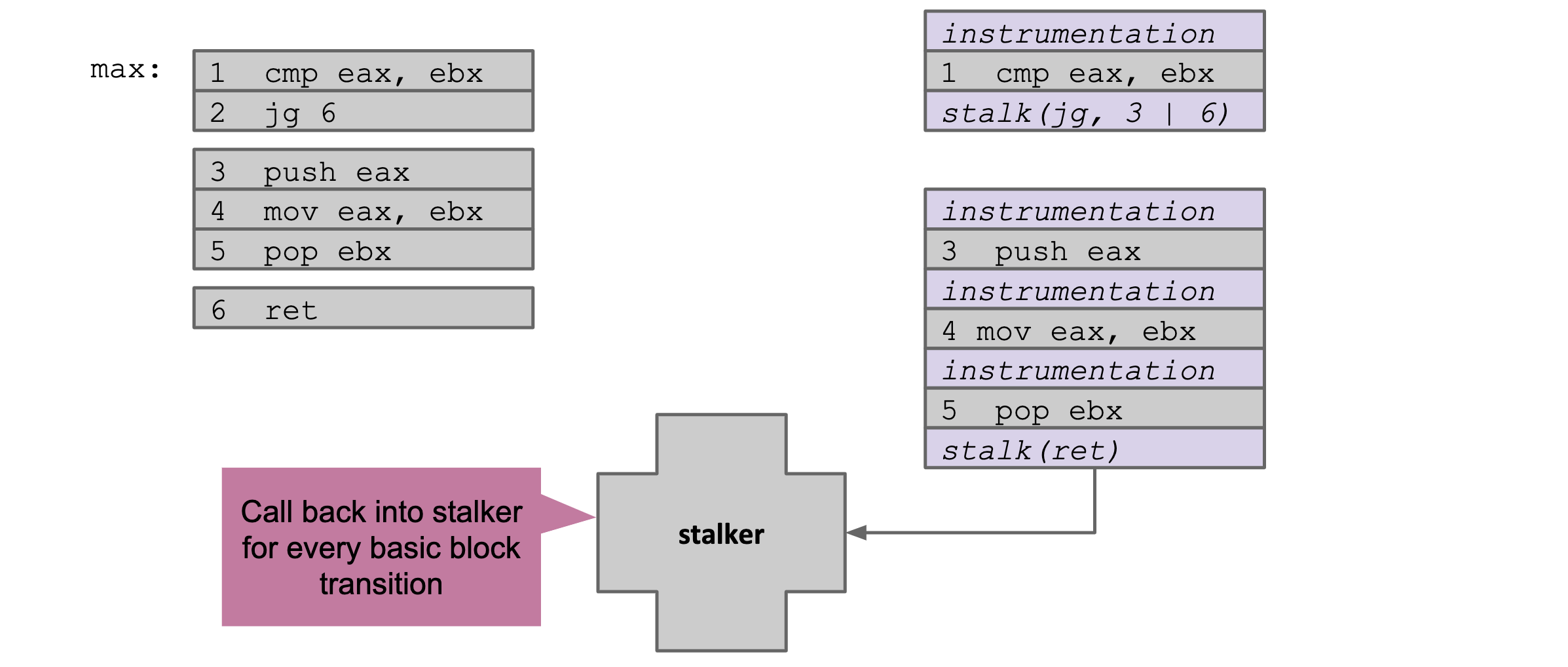 实际上似乎很复杂,要处理很多细节,可以看官方文档,以arm做例子讲的不熟悉没看能用就行。
实际上似乎很复杂,要处理很多细节,可以看官方文档,以arm做例子讲的不熟悉没看能用就行。
Java勾子
没细看,先留着,目测它hotspot用的是jvmti,delvik和art应该类似。
常见问题
由上可知,只要一个frida-server能在目标系统上运行,它就能注入目标进程,如frida-server是32位而目标进程是64位,只要frida-server里相关的代码按64位编写,gadget.so为64位即可,事实上frida也确实会内嵌多版本的gadget!默认情况下,debugger是使用debuggee的libc库函数进行so注入的,而为了获取debuggee里所需函数的地址,它是通过从本身获取函数偏移,从/proc获取目标里的加载基址(Windows常见的代码注入方式)来实现的,此时就需要debuggee的libc和debugger的libc完全一致,我们自己编译的frida-server可能需要用编译时的libc,此时就会有一个常见的问题unable to inject library into process without libc:
 其实就是两个libc不一致,一种粗暴的解决方法就是直接把debuggee的相关地址硬编码进去,例如:
其实就是两个libc不一致,一种粗暴的解决方法就是直接把debuggee的相关地址硬编码进去,例如:
diff --git a/src/linux/frida-helper-backend-glue.c b/src/linux/frida-helper-backend-glue.c
index b99963a1..e46133c2 100644
--- a/src/linux/frida-helper-backend-glue.c
+++ b/src/linux/frida-helper-backend-glue.c
@@ -2982,6 +2982,42 @@ frida_resolve_library_function (pid_t pid, const gchar * library_name, const gch
GumAddress local_base, remote_base, remote_address;
gpointer module, local_address;
+ if (g_strcmp0 (library_name, "libc") == 0){
+ remote_base = frida_find_library_base (pid, library_name, &remote_library_path);
+ if (remote_base == 0)
+ return 0;
+ if (g_strcmp0 (function_name, "open") == 0){
+ remote_address = remote_base + 0xE5B60; // open64
+ }else if (g_strcmp0 (function_name, "close") == 0){
+ remote_address = remote_base + 0xE6670;
+ }else if (g_strcmp0 (function_name, "write") == 0){
+ remote_address = remote_base + 0xE5EF0;
+ }else if (g_strcmp0 (function_name, "syscall") == 0){
+ remote_address = remote_base + 0xEF2E0;
+ }else if (g_strcmp0 (function_name, "__libc_dlopen_mode") == 0){
+ remote_address = remote_base + 0x12B410;
+ }else if (g_strcmp0 (function_name, "__libc_dlclose") == 0){
+ remote_address = remote_base + 0x12B520;
+ }else if (g_strcmp0 (function_name, "__libc_dlsym") == 0){
+ remote_address = remote_base + 0x12B490;
+ /*}else if (g_strcmp0 (library_name, "pthread_create") == 0){
+ remote_address = remote_base + ;
+ }else if (g_strcmp0 (library_name, "pthread_detach") == 0){
+ remote_address = remote_base + ;
+ */}else if (g_strcmp0 (function_name, "mmap") == 0){
+ remote_address = remote_base + 0xEF4D0; // mmap64
+ }else if (g_strcmp0 (function_name, "mprotect") == 0){
+ remote_address = remote_base + 0xEF5F0;
+ }else if (g_strcmp0 (function_name, "munmap") == 0){
+ remote_address = remote_base + 0xEF5C0;
+ }else{
+ printf("Not Found libc func: %s\n", function_name);
+ return 0;
+ }
+ printf("libc func <%s> addr : 0x%08x\n", function_name, remote_address);
+ return remote_address;
+ }
+
local_base = frida_find_library_base (getpid (), library_name, &local_library_path);
g_assert (local_base != 0);
注:若需要调试,可参考https://github.com/frida/frida/issues/1107 编译出含符号的版本,并添加输出信息来调试。
安装
普通安装
Frida分为控制端与服务端,对于控制端可直接使用如下命令安装Python Binding和工具包:
pip install frida
pip install frida-tools
为了使用类型提示可安装TypeDefine:
npm install @types/frida-gum # -g 安装到全局
从frida 17.0.0开始,运行时桥不再被直接绑定在GumJS里了,意思就是要对Java/OC/Swift插桩需要单独再安装对应的桥(否则在开发时就会发现Java/ObjC这些全局变量不存在):
npm install frida-objc-bridge
npm install frida-java-bridge
npm install frida-swift-bridge
而对于服务端,一般来说可以直接下载预编译的二进制文件,根据目标系统的平台选择合适的文件即可。此时安装了frida的核心,python binding与python的易用工具,说明如下:
- frida:repl工具,可很方便的调试脚本与实时交互式编码分析。
- frida-compile:对js/ts进行编译,从而处理依赖与新语法(编译为ES5)问题,比如桩代码可能实现多个功能,每个功能位于单独的文件,另外想要使用一些三方库,而frida只能指定一个脚本,此时需要使用此工具,另外想使用新语法或者使用TypeScript,可以使用它编译出frida支持的js文件。
- frida-create:用于生成cmodule和agent模板。
- frida-portal:分布式插桩,没用过。
- frida-kill:杀杀杀进程。
- frida-ps:列出进程。
- frida-join:应该和portal相关吧,没用过。
- frida-ls-devices:列出存在的设备。
- frida-trace:它实现了类似ltrace的功能。
重新编译
上面已经提到Frida官方提供预构建的二进制文件,一般直接使用即可,但是有时会需要自己重新编译,如需要对它进行修改,或预编译的二进制文件无法在目标环境运行。已知frida由控制端和服务端构成,它们间可以通过网络,USB等方式连接,所以控制端一般都能直接使用,但是服务端需要运行于目标系统,像我们分析的网络设备都是千奇百怪的环境,一般都无法直接在那里面运行,因此需要自己构建匹配的二进制文件(frida-core),详细的如下:
1.下载源码git clone --recurse-submodules https://github.com/frida/frida.git
2.如果直接使用系统自带的工具链,那么根据官方文档,安装必要的工具包后执行make,它就列出要编译的目标,加上即可,如make core-linux-x86_64,对于tool和node需要有dev的python与node。
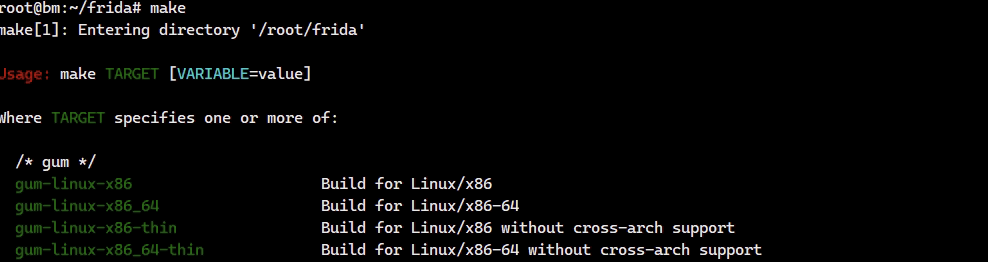 它会下载预先构建的SDK,就是一些依赖的库,然后使用gcc和g++编译。
它会下载预先构建的SDK,就是一些依赖的库,然后使用gcc和g++编译。
3.但是一般我们需要使用交叉编译,配置交叉编译工具链,操作系统选旧一点的,如果没有提供选项就选择Git源并设置tag号(如v3.2),另外需要启用g++与multilib,详见之前文章。
4.编辑releng/setup-env.sh文件,它里面有个大的switch case,在这里面修改,如下:
case $host_os in
linux)
host_arch_flags=""
host_cflags=""
case $host_arch in
x86)
host_arch_flags="-m32 -march=pentium4"
host_cflags="-mfpmath=sse -mstackrealign"
host_toolprefix="/usr/bin/"
;;
x86_64)
host_arch_flags="-m64"
host_toolprefix="x86_64-linux3.2-linux-gnu-" # 修改
;;
xxxxx)
OLD_64) # 添加
host_arch_flags="-m64"
host_toolprefix="x86_64-xxoo-linux-uclibc-"
;;
一般来说只需修改x86_64的工具链前缀,之后在make时它会下载预编译的库文件,并用该工具链进行编译,但有时库也需要自己编译,此时需要新加一个条目。
5.新增条目后,需要先运行make -f Makefile.sdk.mk FRIDA_HOST=xxxxx-OLD_64,它会下载依赖库的源码(deps目录),并使用配置的工具链先编译库依赖库,这里有两个点需要注意:为cpid设置代理,如export HTTPS_PROXY=192.168.202.1:7890,否则拖不下来,另外在编译V8时需要足够的内存。
6.和第二步一样,使用make编译,只是若使用交叉工具链,需要将工具链的地址添加到path环境变量中,此处需要注意,若修改了setup-env.sh文件,需要先执行make clean,否则修改不会在之前构建的项目下生效。
7.将它和它依赖的库传输到目标系统,依赖库在sysroot下,有时会出现如下错误:
/data2/sysroot # ./frida-server
sh: ./frida-server: not found
是因为它的ld不存在,把它复制过去就好啦:
root@bm:~/x-tools/x86_64-linux31-linux-gnu/x86_64-linux31-linux-gnu/sysroot# readelf -l frida-server | grep program
There are 12 program headers, starting at offset 64
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
/data2/sysroot # ls /lib64/ld-linux-x86-64.so.2
ls: /lib64/ld-linux-x86-64.so.2: No such file or directory
/data2/sysroot # ln -s /data2/sysroot/lib64/ /lib64
/data2/sysroot # LD_LIBRARY_PATH=/data2/sysroot/lib64 ./frida-server -h
Usage:
frida [OPTION?]
Help Options:
-h, --help Show help options
...
用法
API
GUMJS
因为它内部的API可能易变而且难以编写,所以一般都是使用它的JS导出,它有完全的功能,如挂钩函数、枚举加载的库、它们的导入和导出函数、读取和写入内存、扫描内存以获取模式等:
| 类型 | 作用 |
|---|---|
| Frida Info | 注入的Frida Gadget的运行时信息,如版本号,内存占用,JS引擎等。 |
| Process Info | 主要是进程信息(平台架构,线程,指针与内存页大小,加载的模块等),线程信息(栈回溯),内存信息(内存搜索,分配,复制,保护权限修改,读写监视)和模块信息(模块名称,内存范围,导出导入符号等),另外的CModule也在这里面,它能将提供的C代码编译并执行,从而在一些热点处提高效率。 |
| DataTypes | 表示数据类型,JS与Native间数据类型是无法直接转换的,Frida提供了Native的封装,如int32封装为Int32,指针封装为NayivePointer,此时就可以对该类型的数据进行相关操作,如对指针可以读指向的字符串,指向的数字等。 |
| Function | 表示函数与回调类型,当值表示Native的函数指针时,JS中是NativeFunction,通过指定函数的签名,就能在任意位置创建函数或调用任意位置的函数了。 |
| IO | 文件操作与网络操作,如打开文件,监听Socket或外向网络连接。 |
| SQLite | 对sqlite数据库文件进行增删查改操作。 |
| Native HOOK | 最常使用的,它分为Interceptor和Stalker,前者用于对函数HOOK,后者用于执行追踪,它可按函数级/代码块级/指令级等不同粒度对执行进行追踪,注意Interceptor不支持指令级HOOK,但可配合Stalker实现该效果。 |
| ObjC | 没用过。 |
| JAVA HOOK | 对Java虚拟机进行操作,包括类加载,类枚举,访问任意类与对任意类进行hook等操作。 |
| Instruction | 可对X86,Arm,Thumb,AArch64,Mips等指令集进行读写,重定位,读为反汇编这在检查内存某处实际的指令很有帮助;写是把汇编代码专为机器码,如在内存中打一些小补丁用它会很高效;另一个重定位是能将一片代码移动到其他位置,它会自动处理代码中的偏移。 |
⚠️:在Arm32上可能有混合指令,Arm指令固定长度是4字节,而Thumb是2字节,正常运行都不会使用地址的最低位,因此可用最低位为1表示thumb指令,在执行跳转时便可以进行正确的地址切换,而在frida中,如插桩或指令解析时,需要根据目标指令的类型对地址执行加1操作:
Note that on 32-bit ARM this address must have its least significant bit set to 0 for ARM functions, and 1 for Thumb functions. Frida takes care of this detail for you if you get the address from a Frida API (for example Module.getExportByName()).
下面简单贴一些代码样例加深理解,真正使用时可根据需要从上表中找对应API。
Native
一般都是使用Interceptor对函数进行hook,它有两个方法:attach可在进入函数前与函数返回前进行hook,此时就可以对参数与返回值进行读取或修改操作,而replace是进行更进一步的hook,它相当于完全替换原函数,因此可在它里面做更灵活的操作(也可以再调用原函数):
// 直接跟踪read函数,输出它的参数和返回值
function trace_read() {
Interceptor.attach(Module.findExportByName(null, "read"),
{
onEnter(args) {
this.fd = args[0].toInt32();
this.buf = args[1];
this.len = args[2].toInt32();
},
onLeave(ret) {
console.log(`===>read(${this.fd},0x${this.buf.toString(16)},${this.len}) \n${hexdump(this.buf, {
length: ret.toUInt32(),
header: false
})}\n<===`)
}
}
)
}
trace_read()
// 对于未导出的函数,可通过偏移获取,如下
let modName = 'libebk-engine.so';
let ebookkBase = Module.getBaseAddress(modName);
let inflateAddr = ebookkBase.add(0x1368B8);
let inflateRetAddr = ebookkBase.add(0x15FFBC);
function inflateTrace() {
Interceptor.attach(inflateAddr, {
onEnter: function (args) {
if (this.returnAddress == inflateRetAddr) { // 当inflate在指定位置被调用时进行hook
this.next_in = args[0].readPointer(); // 保存它的参数,此时分析出它的第一个参数值zlib ctx,因此保存想要的信息
this.avail_in = args[0].add(4).readU32();
this.next_out = args[0].add(0x0c).readPointer();
this.avail_out = args[0].add(0x10).readU32();
console.log(`=============inflate start==============
${this.next_in},${this.avail_in}
${dumpmem(this.next_in, min(64, this.avail_in))}
`)
} else {
console.log(`diff=========> ${this.returnAddress}!=${inflateRetAddr}`)
}
},
onLeave: function (ret) {
if (this.returnAddress == inflateRetAddr) {
// 在函数结束时,就可以知道函数执行信息了
console.log(`
${dumpmem(this.next_out, min(64, this.avail_out))}
=============inflate end==============
`)
}
}
})
}
// repace样例
var ptracePtr = ptr("0x18bad1078"); //直接指定,ptrace函数地址
var OriginPtrace = new NativeFunction(ptracePtr, 'void', ["pointer", "pointer", "pointer", "pointer"]);// 将该地址指定为函数指针
Interceptor.replace(ptracePtr, new NativeCallback(function(arg1, arg2, arg3, arg4) {
// 此时完全替换了函数,就可以先处理参数,再决定是否要调用原函数,并最终返回结果
if (arg1 == 31) {
console.log("Hook ptrace Bypass!!!");
return 0;
}
else {
return OriginPtrace(arg1, arg2, arg3, arg4);
}
},'int', ['int', 'pointer']));
stalker还没用过先不写,感觉做覆盖率分析会很有用。有个容易被忽略的点需要注意,分配新变量后,要关注它的生命周期,比如方法内部的变量若未逃逸会在方法运行结束被垃圾回收机制处理,若再访问会出现非预期结果,可以使用this将其作用域扩大,不过这里面有个容易出错的点,箭头函数的作用域是当前(外部)函数,所以在箭头函数里用的this是指外部的this,因此一般不要用它。网上有很多使用示例[1][2]可多感受一下。
JAVA例子
使用Java.perform(cb)附加到虚拟机开始执行Java插桩,它内部可使用Java.use获取类,从而对方法进行重写;使用Java.choose对类实例进行操作:
Java.perform( () => {
// 此处直接hook类的方法,输出它的
let EncryptionUtil = Java.use("me.betamao.utils.EncryptionUtil");
EncryptionUtil.encrypt.implementation = function(key, value){
console.log(`Key: ${key} Value: ${value}`);
return this.encrypt(key, value); // or EncryptionUtil.encrypt.call(this, key,value);
}
// 对于存在重载的方法,可以使用overload指定签名
secret_key_spec.$init.overload("[B", "java.lang.String").implementation = function (x, y) {
send('{"my_type" : "KEY"}', new Uint8Array(x));
return this.$init(x, y);
}
// 直接调用类方法
let Util = Java.use("me.betamao.utils.Util");
console.log(`encode: ${Util.encode('123')}`);
// 对于对象方法,需要先用choose获取类的所有对象,此时可以对对象进行读写,也可以调用它的方法
Java.choose("me.betamao.utils.Util", {
onMatch: function(instance) {
console.log(`[ * ] Instance found in memory: ${instance} name: ${instance.name()}`);
},
onComplete: function() { }
});
// 对于特殊方法,如构造函数,可使用$new
var string_class = Java.use("java.lang.String");
var my_string = string_class.$new("hello world")
// 加载指定类,如一些功能代码使用java编写,可编译为dex/class再加载到vm中调用
Java.openClassFile("/data/bm.dex").load();
});
在处理Java HOOK时常需要处理类型转换,比如js和java类型转换,这种看转换方向选择js或Java代码实现就好了。另外在勾取hotspot时,需要它有调试符号,不过应该不是必要条件,暂时没用到所以先不管啦。要使用其他功能可见网上的代码或官方API文档。
C/CPP
一般没必要用吧,不过也可能会用上,比如自己写个工具,或者与其他工具结合(Xposed在启动时全局插桩),releng/devkit-assets下有三个例子,分别演示了用C远程注入,在C里调JS插桩和完全用C实现插桩,最常用的应该是C里调JS插桩吧,它的代码如下:
// 嵌入的都需要先初始化Gum
gum_init_embedded ();
// 选择js引擎后端,还可选v8
backend = gum_script_backend_obtain_qjs ();
// 创建桩代码
script = gum_script_backend_create_sync (backend, "example",
"Interceptor.attach(Module.getExportByName(null, 'open'), {\n"
" onEnter(args) {\n"
" console.log(`[*] open(\"${args[0].readUtf8String()}\")`);\n"
" }\n"
"});\n"
"Interceptor.attach(Module.getExportByName(null, 'close'), {\n"
" onEnter(args) {\n"
" console.log(`[*] close(${args[0].toInt32()})`);\n"
" }\n"
"});",
cancellable, &error);
g_assert (error == NULL);
// 指定message回调函数
gum_script_set_message_handler (script, on_message, NULL, NULL);
// 加载脚本
gum_script_load_sync (script, cancellable);
// 调用open,此时桩会输出trace,注意桩不会跟踪frida gadget的代码,但此处不输入gadget代码
close (open ("/etc/hosts", O_RDONLY));
close (open ("/etc/fstab", O_RDONLY));
context = g_main_context_get_thread_default ();
while (g_main_context_pending (context))
g_main_context_iteration (context, FALSE);
// 结束清理现场
gum_script_unload_sync (script, cancellable);
g_object_unref (script);
gum_deinit_embedded ();
Client
简单使用
我们使用时主要是使用JavaScript写HOOK代码,API参见官方文档,此处推荐用TypeScript编写,此时可使用JetBrain家的IDE,如Pycharm可配置TS自动编译,否则也可以使用frida-compile进行编译。
 一般来说,我们可以直接使用命令行工具进行HOOK,常用的命令如下:
一般来说,我们可以直接使用命令行工具进行HOOK,常用的命令如下:
frida -l .\fortigate.js -H 127.0.0.1:5555 -p 3871 --runtime=v8
# -l xx.js 指定HOOK脚本,它会自动监视文件修改并实时加载最新的内容
# -H 远程地址
# -p 要attach的进程ID
# -n name 要附加的进程名,若有多个同名进程则必须使用-p
# -f filename 创建新进程并附加,它能在目标执行前进行hook,连双生进程也能秒
# --debug 在使用v8时可进行调试
# --realm=native|emulated 在调试android模拟器时,需要此选项
若使用-l指定了脚本,frida在运行时会加载指定的脚本并进入repl界面,在此界面可以继续交互式操作,另外它会一直监视指定的脚本,所以可以任意修改脚本内容,它会实时重新加载脚本并执行。调试时,需要切换到v8引擎,并添加调试参数,如--runtime=v8 --debug,之后可使用chrome调试,直接打开chrome://inspect/选择连接的设备即可:
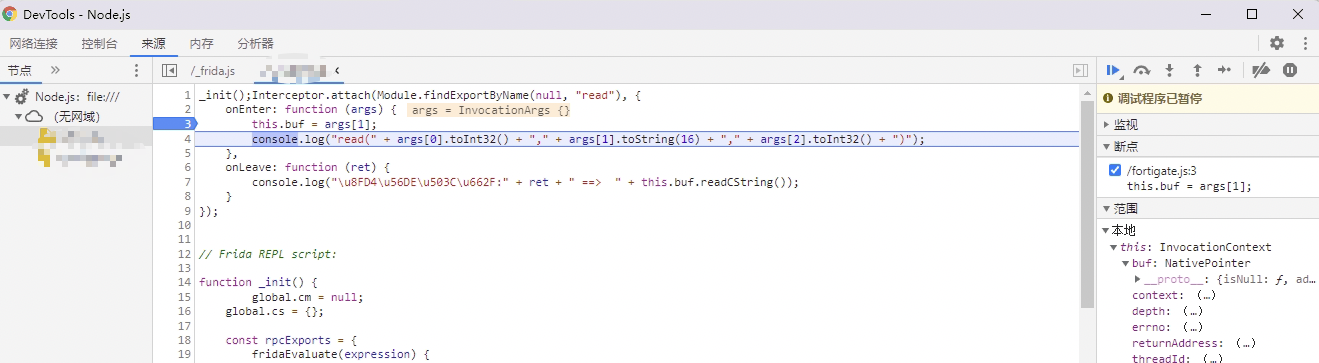 另外也可以使用JetBrain去调试,它可以直接调TS看着更舒服。
另外也可以使用JetBrain去调试,它可以直接调TS看着更舒服。
复杂使用
天对地,雨对风,简单对复杂!一般用frida命令行工具就可以直接进行简单hook了(如上),但若想再自动化点,或进行更复杂的hook(等遇到自然就知道了)就需要写客户端代码了,frida提供了多种语言绑定,可以用熟悉的语言写客户端,如下为python示例:
import frida
import sys
js=open('hook.js','r').read()
def on_message(message, data):
...
pid = device.spawn(['sslvpnd',['-x']]) # 启动程序并挂起
print("[+] Got PID %d" % (pid))
session = device.attach(pid) # 附着
script = session.create_script(js) # js为hook代码
# Callback function
script.on('message', on_message) # 注册回调,on_message用于和debuggee传递数据
script.load() # 加载脚本
device.resume(pid) # 恢复进程
input() # 卡!不然程序就结束啦
也可以直接附加到正在运行的程序:
import frida
import sys
session = frida.attach('hello')
script = session.create_script("""
Interceptor.attach(ptr("0x1400B54b0"), {
onEnter(args) {
send(args[0].toInt32());
}
});""")
def on_message(message, data):
"""
message 传递文本数据,它的type表明消息类型,send表述普通数据,error表示异常
data 用于传输二进制数据,它不必使用json进行编码
"""
if message['type']=='send':
print(message['payload'])
script.post({'type':'poke', 'my_data':'ha?'})
script.on('message', on_message)
api = script.exports # 此处可以通过api.xxx()调用hook代码导出的函数,hook代码可通过rpc.exports导出任意函数供远程调用
script.load()
input()
若安装node binding可以使用如下代码:
'use strict';
constco = require('co');
constfrida = require('frida');
constload = require('frida-load'); //!!
let session, script;
co(function*() {
session = yieldfrida.attach('hello');
constsource = yieldload(require.resolve('./agent.js'));
script = yieldsession.createScript(source);
script.events.listen('message', message => {console.log(message);});
yieldscript.load();
}
);
附: 关于Frida-Stalker、QBDI和Unidbg的分析可见Android动态二进制插桩与指令级追踪