换了MBA后习惯装上阅读器,但是第一次用就被惊到了,不知道这是有意为之还是出了BUG,反正等了几个月官方也不修,没办法就打算把书提出来用自带的BOOK阅读了:

⚠️⚠️⚠️注:本文只是为了技术交流,有兴趣可以自己分析自己用,本文不提供脚本或电子书下载!另外,为了防止被直接拿去下载,本文忽略了一些小细节,解密需要分析整个过程!
安卓逆向基础
按惯例,补点基础,然鹅忘得差不多了,以后想到什么再补吧
工具
工欲那啥必须那啥,Android分析的工具太多了,有些小工具会打包成工具箱,比如AndroidKiller,APKIDE等,还有很多是单独的工具或脚本,下面就简单记录一些常用的,还有很多很多很多会在某次分析中用到,就不写了...
运行
- 手机,你需要一台小米10嗷欻~~才怪~~,太新的手机也不好,我用的小米2特方便。不然的话用模拟器也可以,比如蓝叠,可使用修改器root,需要注意的是这次分析的爱屁屁没有x86的动态库,而frida对模拟器只能使用x86的server,并且若要hook arm的库需使用realm。
- ADB等工具,简单说明下ADB包括三部分,本电脑使用的adb和adb-server及被调试手机运行的adbd,执行adb的大部分命令会启动并连接adb-server,由它通过usb/网络与adbd通信,adbd执行实际命令,默认adbd运行权限也不高,可用adb root使它以root身份启动,其他常用命令可见adbsehll。那一套常用的还有Logcat,DDMS等。
分析
JEB和GDA差不多主要用于分析Java层代码,IDA用于分析和调试so文件
网络
这里分两类,一类是抓包的,比如r0capture,proxydroid,另一类是分析的,比如charles,fiddler,wireshark,burpsuite等
自动脱壳
FRIDA-DEXDump和Frida-Apk-Unpack都是使用Frida实现的自动化脱壳脚本,而FART是基于Android 6.0实现的ART环境下通过主动调用的自动化脱壳方案。
调试插桩
xposed和cydia是比较经典的hook框架,前者主要用于Java层而后者用于Native层,现在更多的会使用 Frida,它动态二进制插桩工具,可以做objc,java,native的HOOK,可以看到上面很多工具是基于它的,之后有时间会单独出一篇分析文章。
鸡识
安卓就Linux上加个手机框架,框架主要用Java虚拟机(dalvik/art)运行程序,和hotspot的栈机不同,它是基于寄存器的,也不使用Java标准的class结构,但是很类似,比如它的汇编smali其实很像普通的字节码,只是说里面有寄存器了,其实这里面的东西都是可以相互转化的。另外程序也可以运行Native的程序或调用Native的库,一半的爱屁屁就是Java+支持JNI语言(比如C/C++)写结合(可参考cxm),显然Java的字节码文件很容易反编译为Java代码,这丝毫不影响阅读,而其他编译为Native代码的部分就可以把客户端上那套保护机制直接套上,况且去符号的二进制文件本身分析就比较困难,所以现在的保护思路也是Java转Native,而之前的那几代在Java层面的保护也就是代码混淆,代码抽取,前者我们木的办法咯但是代码抽取的写个脚本也能弄出来,更多可以看OWASP的文档。
说回破解本身,大体和客户端一致,先熟悉下程序,搞清楚目标是啥,再静态分析看看整体长啥样,找找关键点,关键点也是那几拳,什么抓包,字符串,配置,元信息,定位到关键点再扩展一顿操作就🆗啦!
调试
分为Java的和Native的,前者一般用idea/as调它的smali代码,应用在启动时若全局设置了ro.debuggable=1或本地的AndroidManifest.xml设置了android:debuggable="true"则会创建调试线程,用户则可以附加调试;
java -jar apktool.jar d t.apk -o out # 解包
java -jar apktool.jar b out -o t.apk # 打包
sign t.apk # 每个apk都需要签名,可以想想自签名也行的那签名的意义
shell adb shell am start -D -n <packagename>/<MainActivity> # 以调试的方式启动,此时会挂起进程
adb forward tcp:8700 jdwp:<pid> # 创建端口转发
后者一般用ida的dbg_server调,这和普通的Linux程序调试没太大区别,只是在用USB连接时,需要用adb进行端口转发
adb push android_server /data # 这个目录好呀,可写可执行
# 也可以放根目录,需要改权限 mount -o rw,remount /
chmod +x android_server
adb forward tcp:23946 tcp:23946 # 通过adb端口转发
反调试
其实反调就那两种套路:检测调试与对抗调试,检测就是若有调试器就进入非正常逻辑,包括检测自身状态(如自身status文件,使用ptrace)与检测外部环境(如监听了23946等端口,运行着名为gdb的进程等);而对抗就是使用与调试器有冲突的功能实现正常逻辑(如隐藏自身进程,双子运行,异常运行),这样有调试器时程序就无法正常运行。
反调试是一种初级的对抗手段,因为它是可逆的,所以找到关键点pass掉就好了,这里记录一些点:
- 查看/proc/\<pid>/下的文件,如status的TracePid,stat的标志,wchan等
- 使用ptrace进行双子执行或者使用PT_DENY_ATTACH等
- 检查进程名,监听的端口
- 通过一些系统提供的接口,如isDebuggerConnected
阅读APP分析
分析要解密的文件
首先,找个远古时代的版本,因为越新的保护可能做的越好,我们的目的不是看它怎么保护的,而是弄出算法就行。可以去豌豆荚找找,一般都有,比如秋秋:
一般升级都会兼容旧版的,所以算法不会变,即使变也可以了解下初代的样子,下载安装好之后就可以运行它,登录账号下几本书后退出,先看看书本身的样子,像书籍这种比较大的数据它们都喜欢放sdcard里,最终在/storage/emulated/0/Android/data/com.jingdong.app.reader.campus/files/里找到了下载的书,它们以JEB后缀命名,但是都无法打开,先使用binwalk对文件进行分析,epub如下: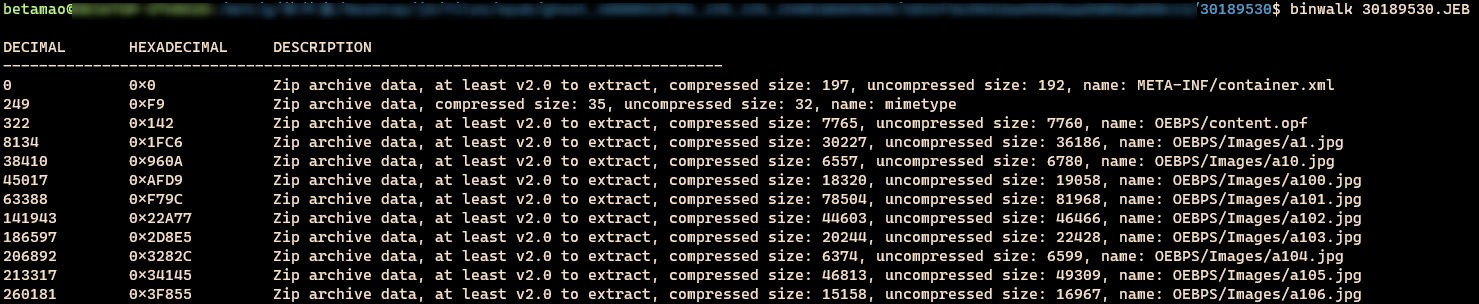
解压后发现图片正常,而文字被加密无法正常显示: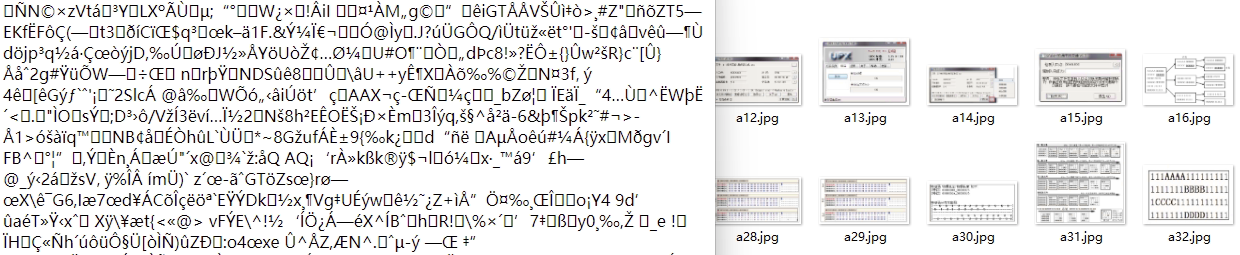
而对于pdf文件,可见它也使用自定义的过滤器进行了加密: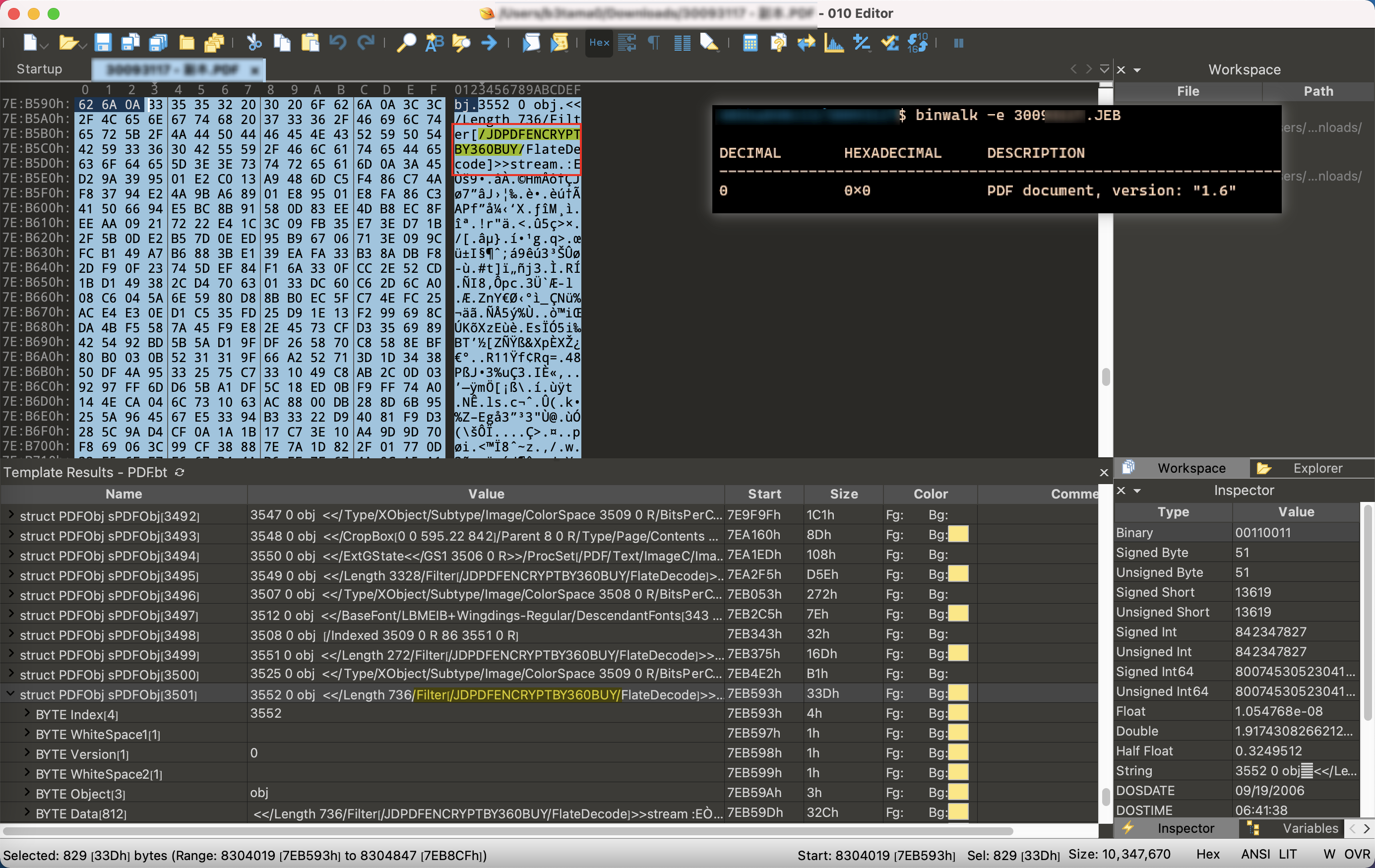
分析数据库
在移动破解中,数据库里面会有很多有用的线索,所以可以先看看,数据库一般会保存在/data/data/com.jingdong.app.reader.campus/databases,取出数据库,直接打开被告知文件非SQLite文件或已被加密,没办法只能先看apk文件了,用GDA打开,搜索SQL/SELECT等关键字,会发现数据库使用了greendao,打开官网发现它支持使用sqlcipher加密数据库,从so文件可以看出是版本3:
.rodata:00119EFB aCipherVersion DCB "cipher_version",0 ; DATA XREF: sqlcipher_codec_pragma_0+178↑o
.rodata:00119EFB ; sqlcipher_codec_pragma_0:off_6F6F8↑o
.rodata:00119F0A a340 DCB "3.4.0",0 ; DATA XREF: sqlcipher_codec_pragma_0+18E↑o
sqlcipher v3 使用AES256 CBC模式加密:
- 把一个数据库分成多个chunk(也可以把它叫做page,默认大小为4kB),每个chunk单独加密,显然password是相同的。
- 不同的是,每个chunk有自己的iv,iv被存在每个chunk的末尾,另外每次写数据都会生成新的iv。
- 对每个chunk,对iv与密文生成MAC(默认HMAC-SHA512),读时做校验
- 对每个数据库,会生成一个16B的盐,存储在文件开始处。加密密钥使用PBKDF2-HMAC-SHA512方式,默认迭代256000次。
- HMAC的key与加密的key不同,前者由后者使用PBKDF2进行二次迭代及一次交换生成。
- 若为了显示魔数等信息而放弃对数据库头部加密,那么盐只能被存在外部,每次打开数据库时显式指出。
- 其他。。。
不过不重要,网上一通搜索知道了怎么用工具解密:
sqlcipher-shell32.exe sk.db
sqlite> PRAGMA KEY = 'exm';
sqlite> ATTACH DATABASE 'sk_plaintext.db' AS plaintext KEY '';
sqlite> SELECT sqlcipher_export('plaintext');
通过全文搜索getEncryptedWritableDb或者getEncryptedreadableDb可以定位到获得加密数据库实力的代码处,回溯可以分析其密钥生成算法,然而。。。。它的密钥是硬编码的: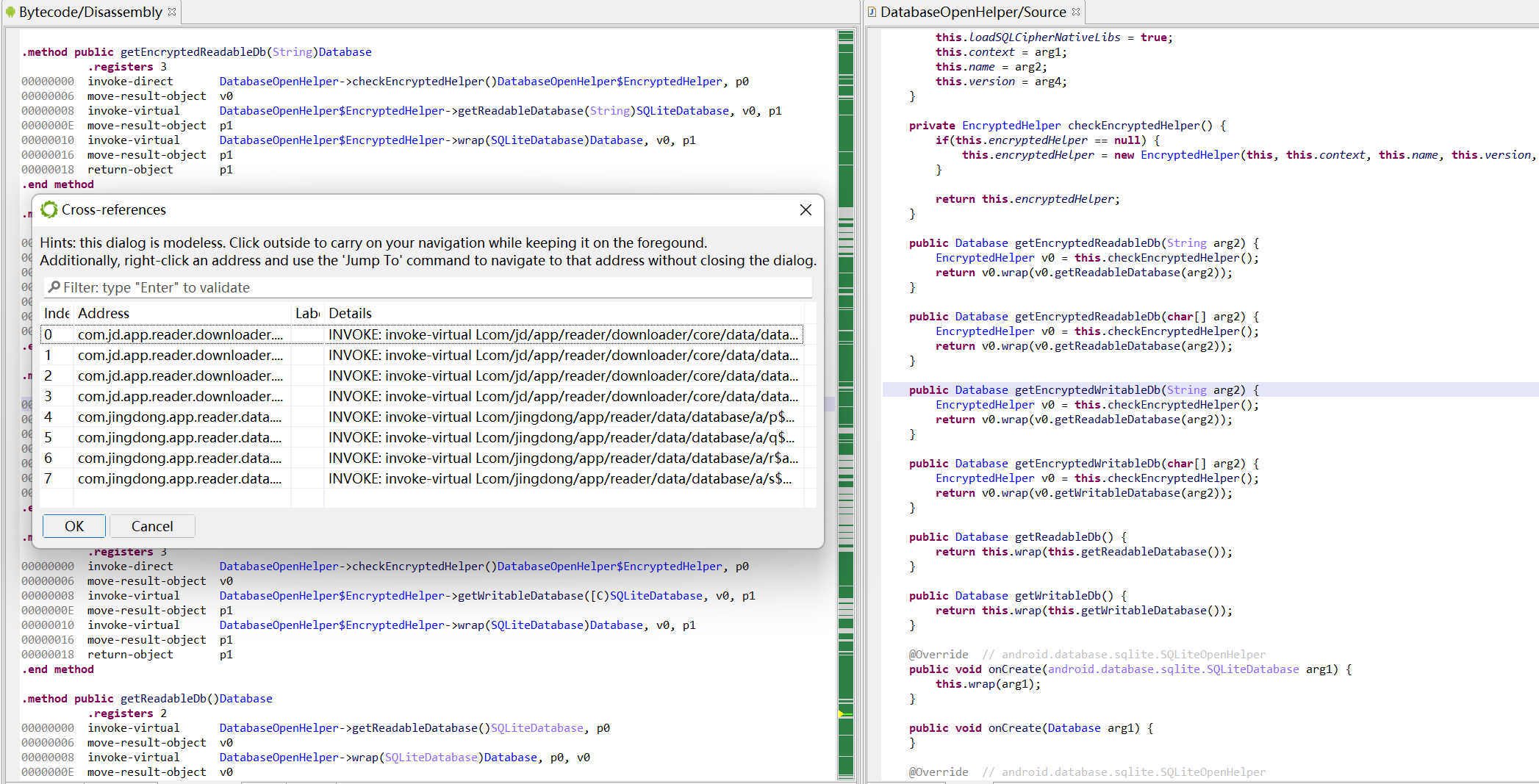
| 库名 | 密码 |
|---|---|
| books.db | SessionBookDataUtil |
| plugin.db | SessionPluginDataUtil |
| sync.db | SessionSyncDataUtil |
| team.db | SessionTeamDataUtil |
| chapter_divisions_book_store.db | password |
| download_failed_record.db | password |
| file_store.db | password |
| the_whole_book_store.db | password |
把数据库解密,可以看到文件的解密key来自books.db的key列: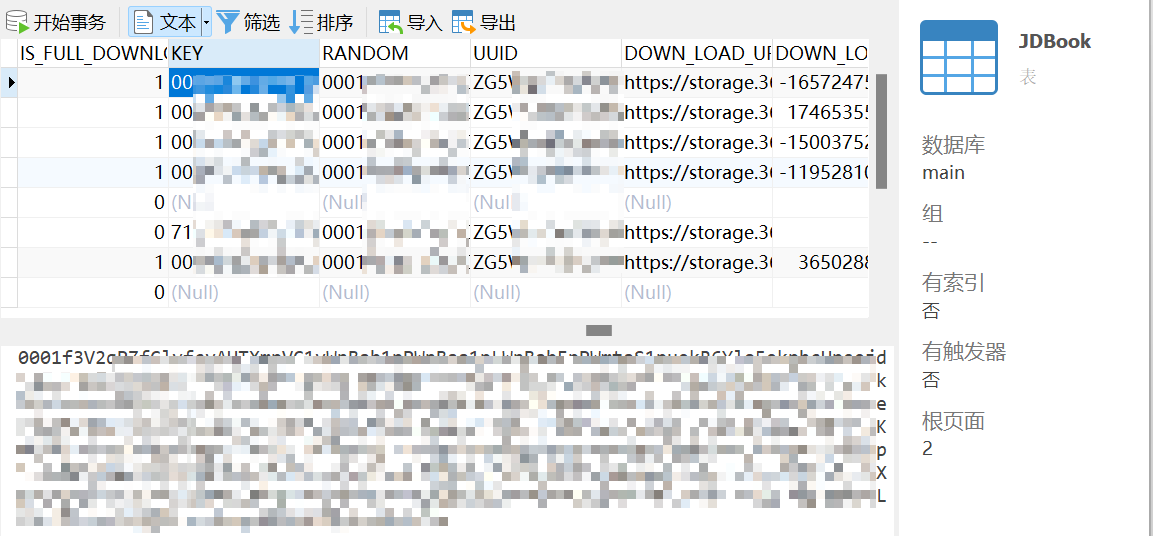
分析DEX
看到这里我下载的版本是没有做其他加固的,只有部分地方有混淆,通过搜索openbook,encrypt,decrypt等可以发现com.jingdong.app.reader.main.action.OpenBookAction里有如下内容: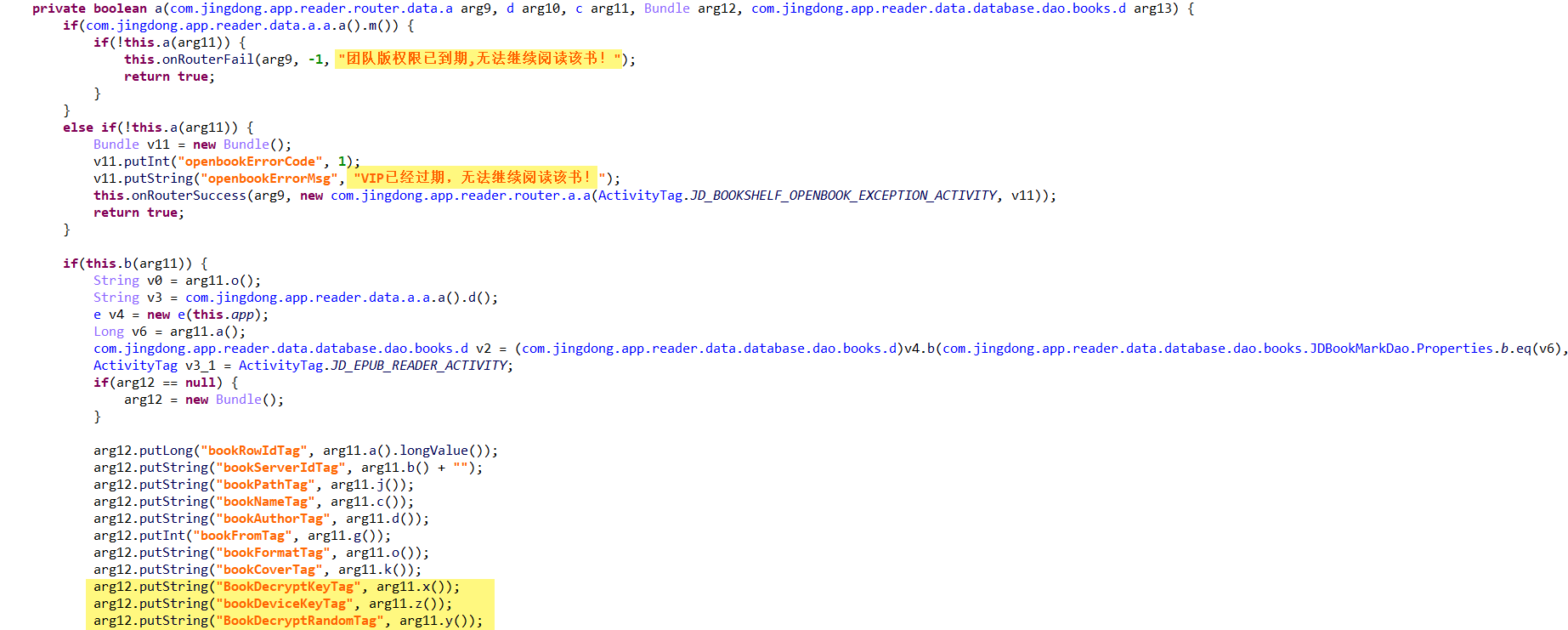
经分析arg11是com.jingdong.app.reader.data.database.dao.books.JDBookDao表的映射,所以通过数据库操作与关键词可定位到com.jd.read.engine.jni.DocView: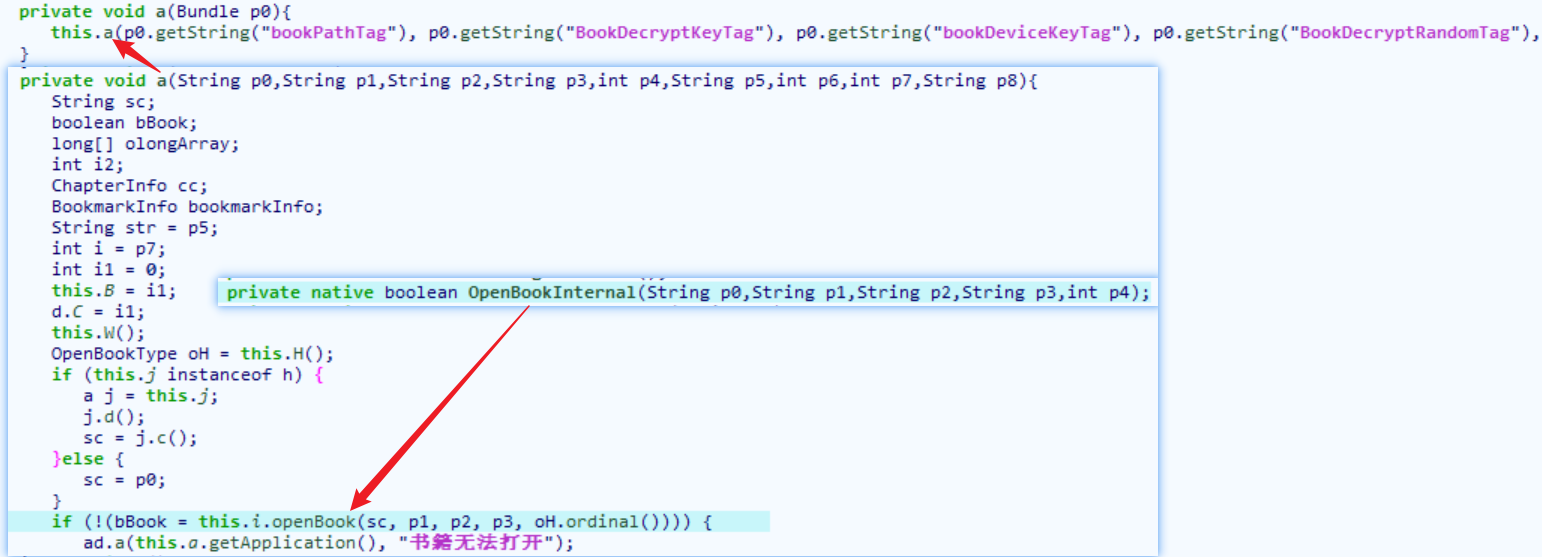
可见把这些数据传入到so里了,另外它的另一个参数表示书籍是否完整还是分章: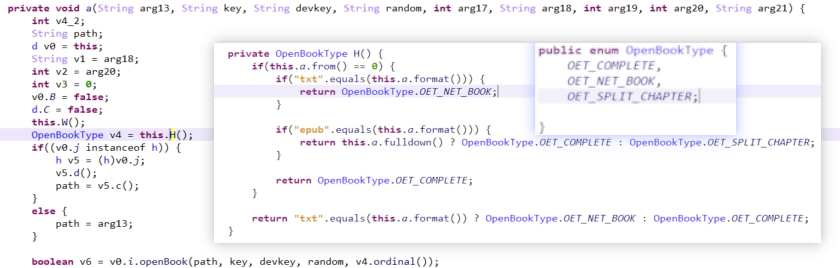
分析SO
上面已经知道怎么调用so了,现在就直接分析它,它是libDecryptorJni.so文件,定位函数时,如果时标准的函数名就是一一对应的,否则从JNI_OnLoad(registerNativeMethods)里面找,不过这里它用的标准名称!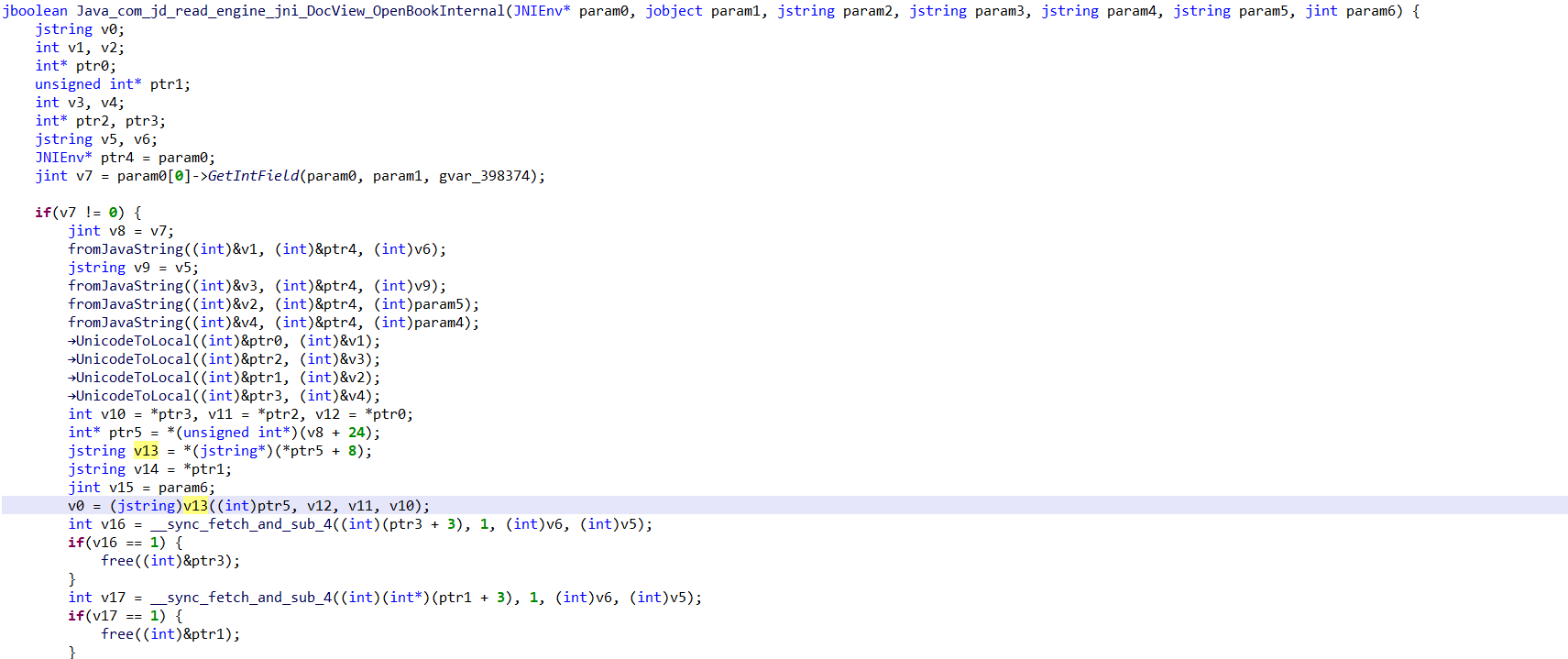
这里用jeb能很好识别ENV与arm的特定指令,如下在IDA中无法识别,遇到这种直接跳过即可:
因为习惯用IDA,所以还是用它接着搞,继续分析可以看到它根据类型使用三种不同的方式解密数据: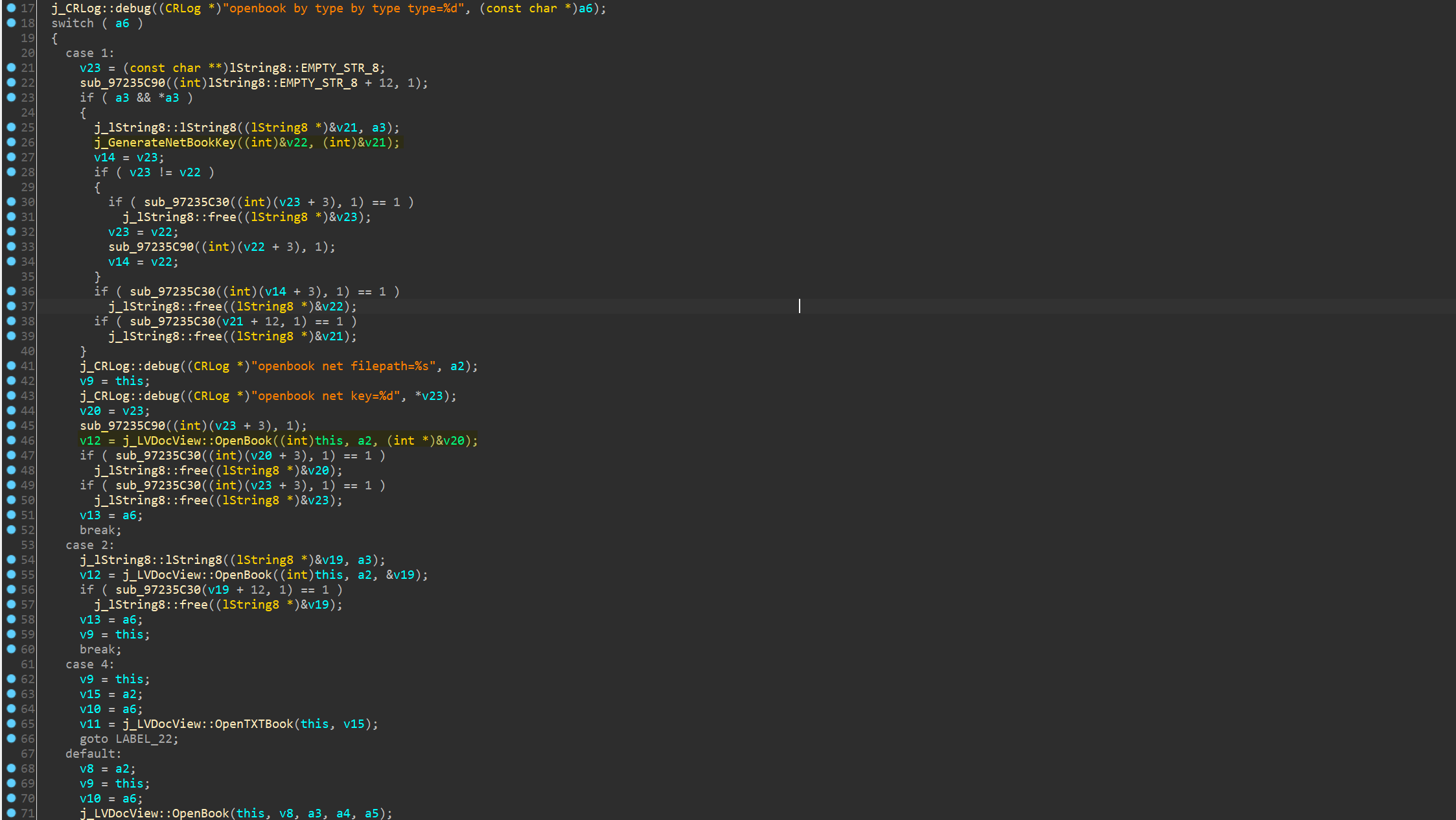
网络类型的会生成用现有的key生成一个新的key,分章节的只是使用了传入的KEY,而完本的把传入的Key,DeviceID和Random全部传入了,所以先看网络类型生成新Key的算法吧:
没有去符号,所以一眼就能看出是个双重MD5:
def generate_net_book_key(data: bytes):
data = md5(data).digest()
data = md5(data).hexdigest().upper()
return data.encode()
然后是完本的,它会调用GetContentKeyBuf,而GetContentKeyBuf又会调用j_j_AnalyticRightFileBuf,后者的结果中将会包含ID和CK,返回的是CK: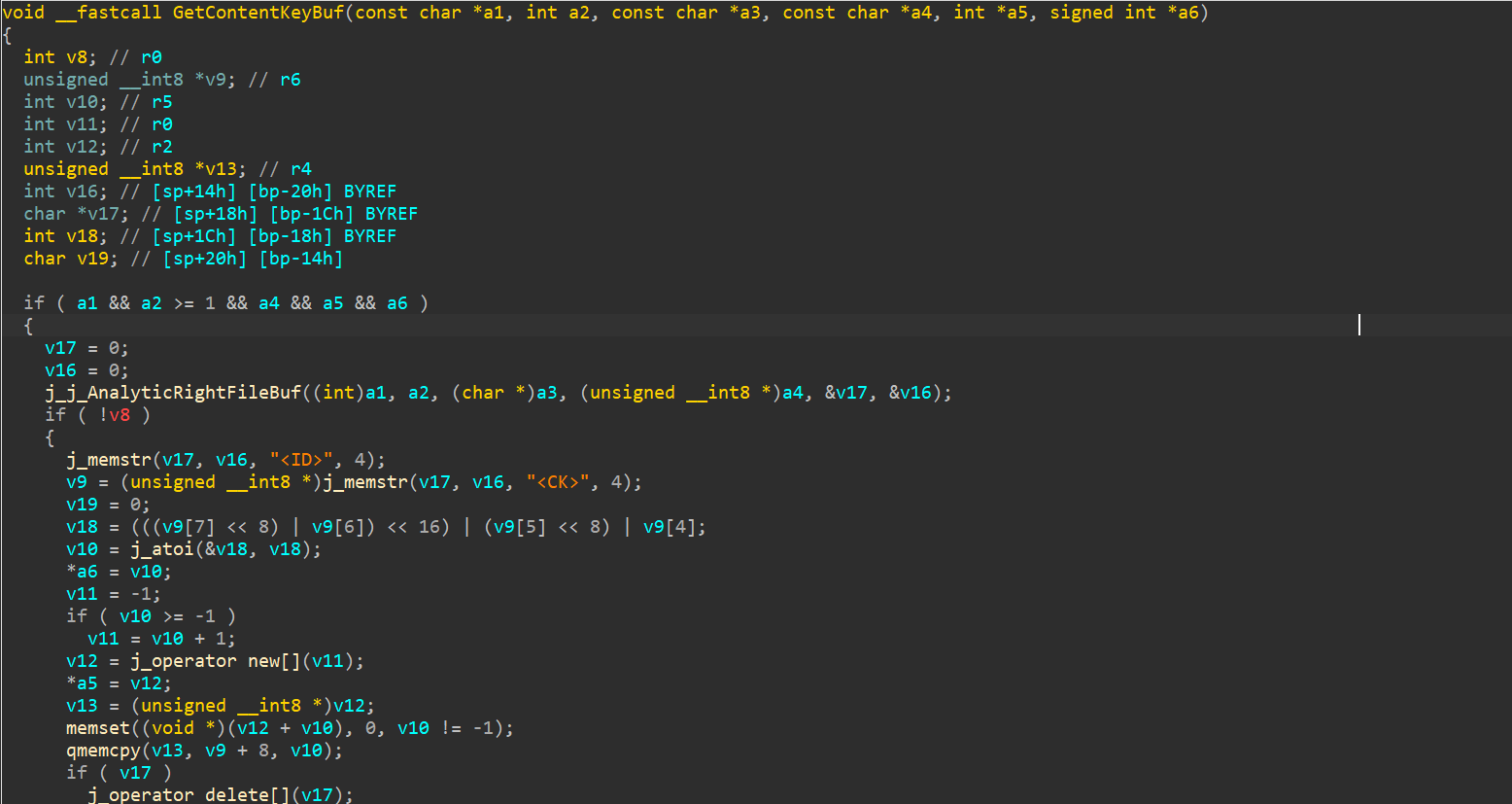
继续跟入j_j_AnalyticRightFileBuf,后续代码太多就不截图了,直接贴代码:
// key = 0001xxxxxxx<HS>0044yyyyyyy
v8 = (unsigned __int8 *)j_memstr((char *)a1, a2, "<HS>", 4); // 截取<HS>之后的部分,前四字节是长度,从而获取后面的数据
j_base64Decode(v12, v31, (char *)v11) // 解码数据,看后面可知它是32字节的hash值
v28 = (char *)v11;
*(_DWORD *)v45 = (((a1[3] << 8) | a1[2]) << 16) | (a1[1] << 8) | *a1; // 获取key前四字节,做版本号
v13 = a2 - 12 - v31;
v14 = j_DecryptByVersion((char *)a1 + 4, v13, &v42, &v41, v45); // 继续解密
v40 = 0;
v39 = 0;
j_j_Hash_256((int)v42, v41, (int)&v40, (int)&v39);
j_memcmp(v40, v28, 32) // 判断解密后的数据的hash是否与hash一致
...
j_DecryptCK(v42, v41, v38, v37, v36, v35, a5, a6); // 所有处理完的数据一起再进行解密
DecryptByVersion
继续入j_DecryptByVersion,需要版本号为0001,之后会调用StringDecryptQomolangma:
v9 = j_strcmp(a5, "0001");
v10 = j_j_StringDecryptQomolangma(a1, a2, a3, a4);
接着跟入StringDecryptQomolangma:
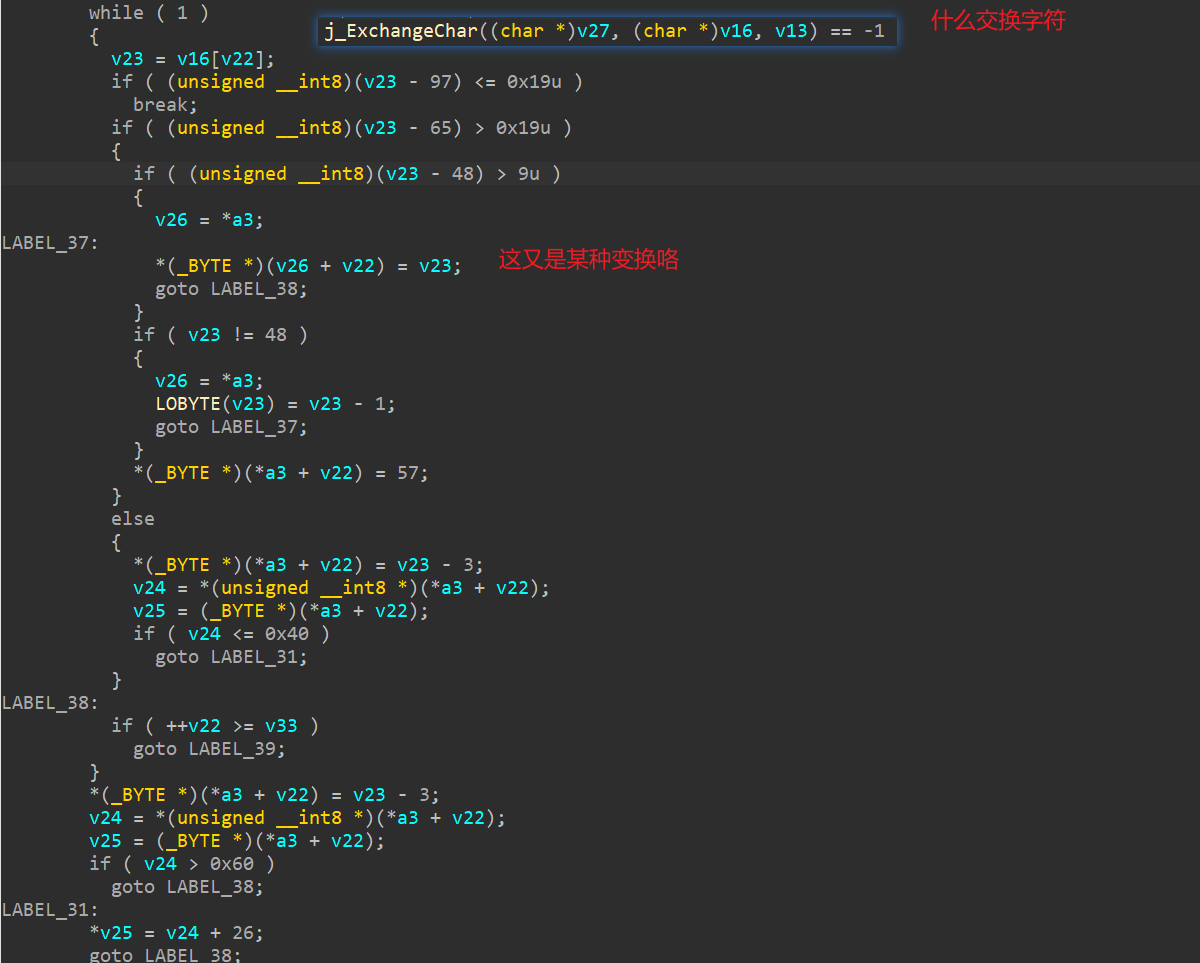
先说最后一种变换吧,就很简单的:
res = []
a_ascii, z_ascii, A_ascii, Z_ascii, zero_ascii, nine_ascii = map(ord, ('a', 'z', 'A', 'Z', '0', '9'))
for c in data:
if a_ascii <= c <= z_ascii:
c -= 3
c = c if c >= a_ascii else c + 26
elif A_ascii <= c <= Z_ascii:
c -= 3
c = c if c >= A_ascii else c + 26
elif zero_ascii <= c <= nine_ascii:
c -= 1
c = c if c >= zero_ascii else nine_ascii
res.append(c)
data = bytes(res)
现在分析那三个函数:
j_JY_Crypt
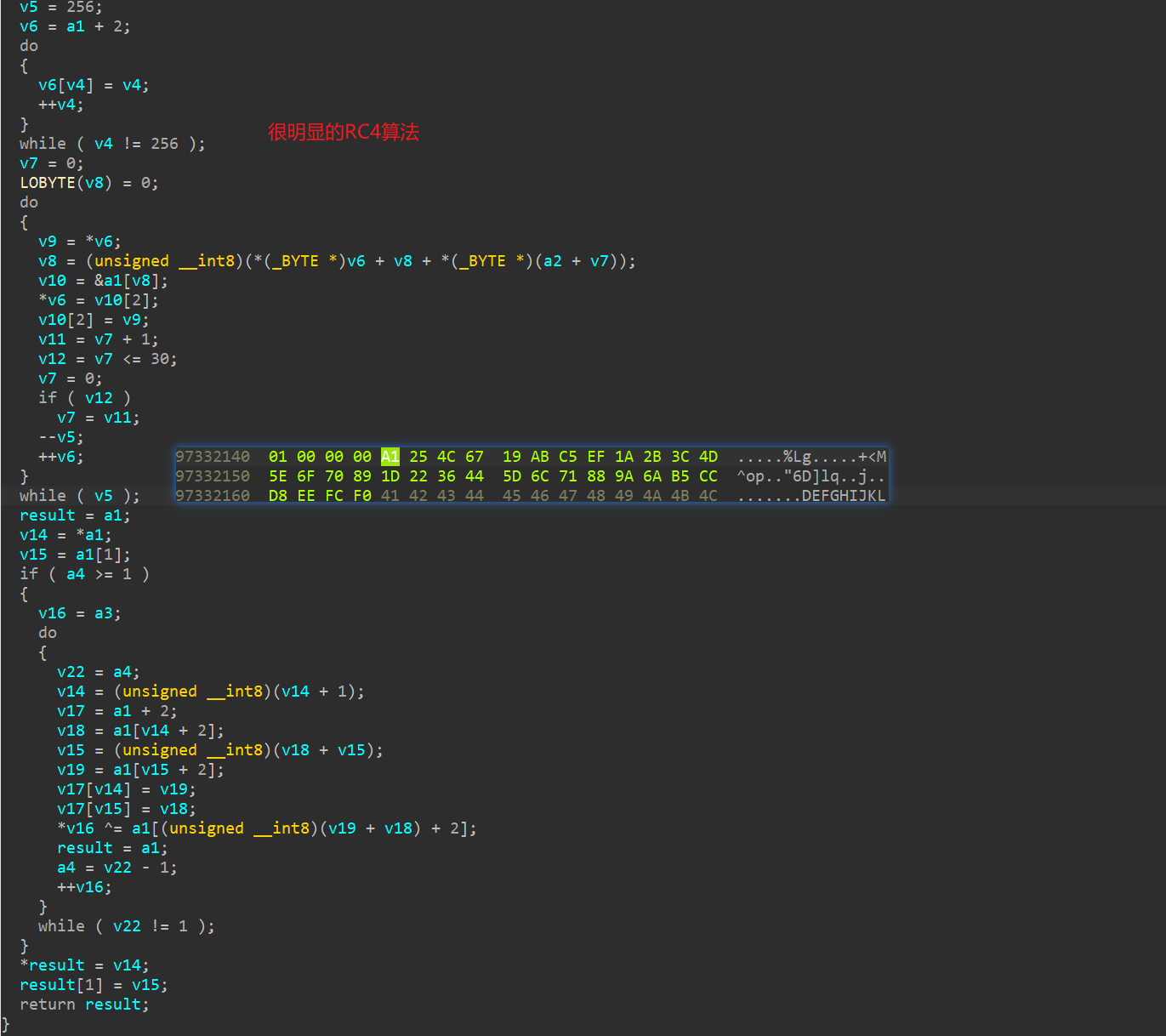
很明显是RC4算法,不多说。
BillDecode
经查询,它和网上的某种DRM解码很像: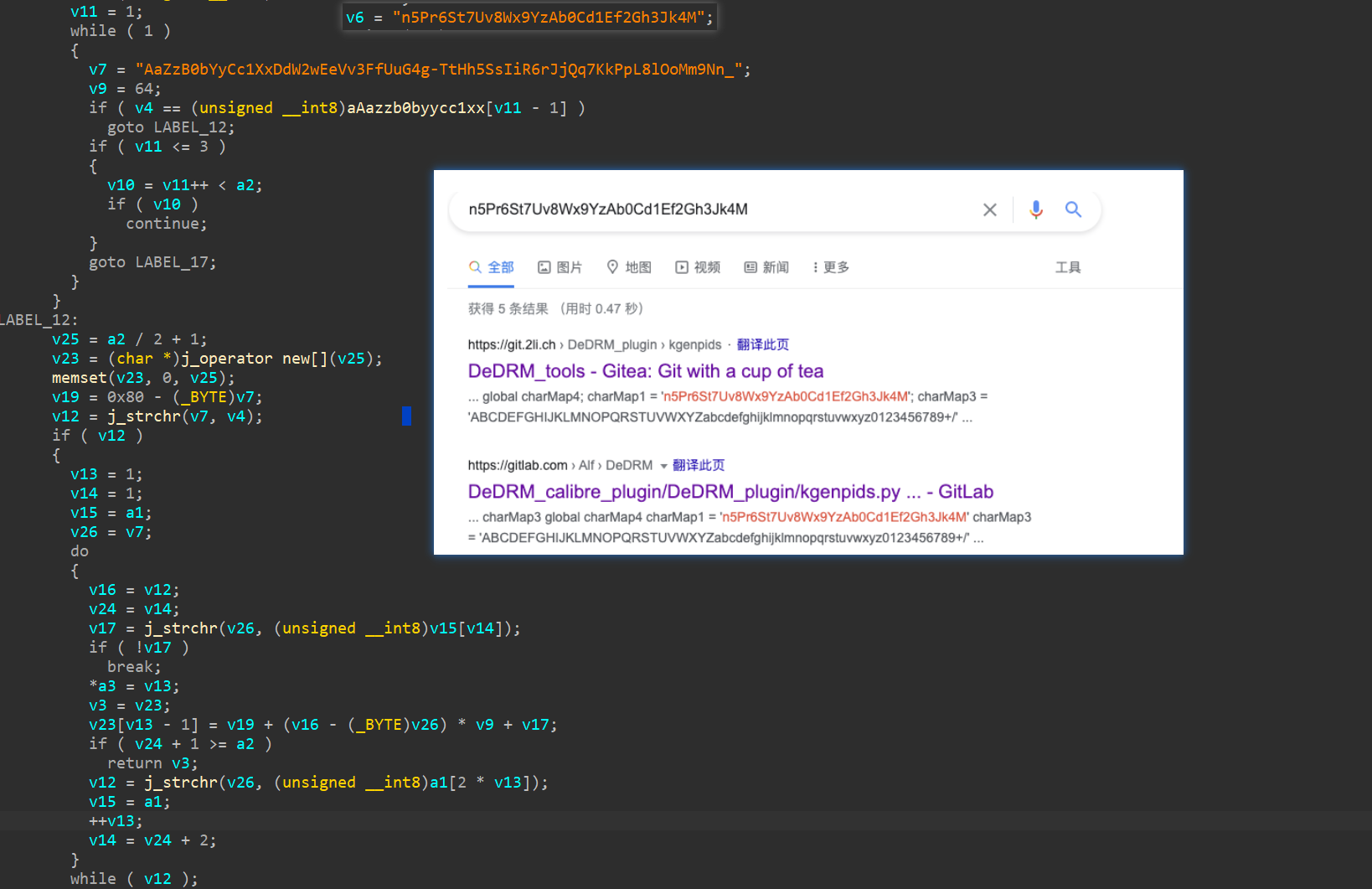
经分析它用了自适应的解码算法,如下:
BILL_TABLE0 = b"n5Pr6St7Uv8Wx9YzAb0Cd1Ef2Gh3Jk4M"
BILL_TABLE1 = b"AaZzB0bYyCc1XxDdW2wEeVv3FfUuG4g-TtHh5SsIiR6rJjQq7KkPpL8lOoMm9Nn_"
def bill_decode(data: bytes):
result = b''
for c in BILL_TABLE0[:8]:
if data[0] == c:
table = BILL_TABLE0
break
else:
for c in BILL_TABLE1[:4]:
if data[0] == c:
table = BILL_TABLE1
break
else:
raise Exception('????')
for i in range(0, len(data) - 1, 2):
high = table.find(data[i])
low = table.find(data[i + 1])
if (high == -1) or (low == -1):
break
value = (((high * len(table)) ^ 0x80) & 0xFF) + low
result += byte(value)
return result
ExchangeChar
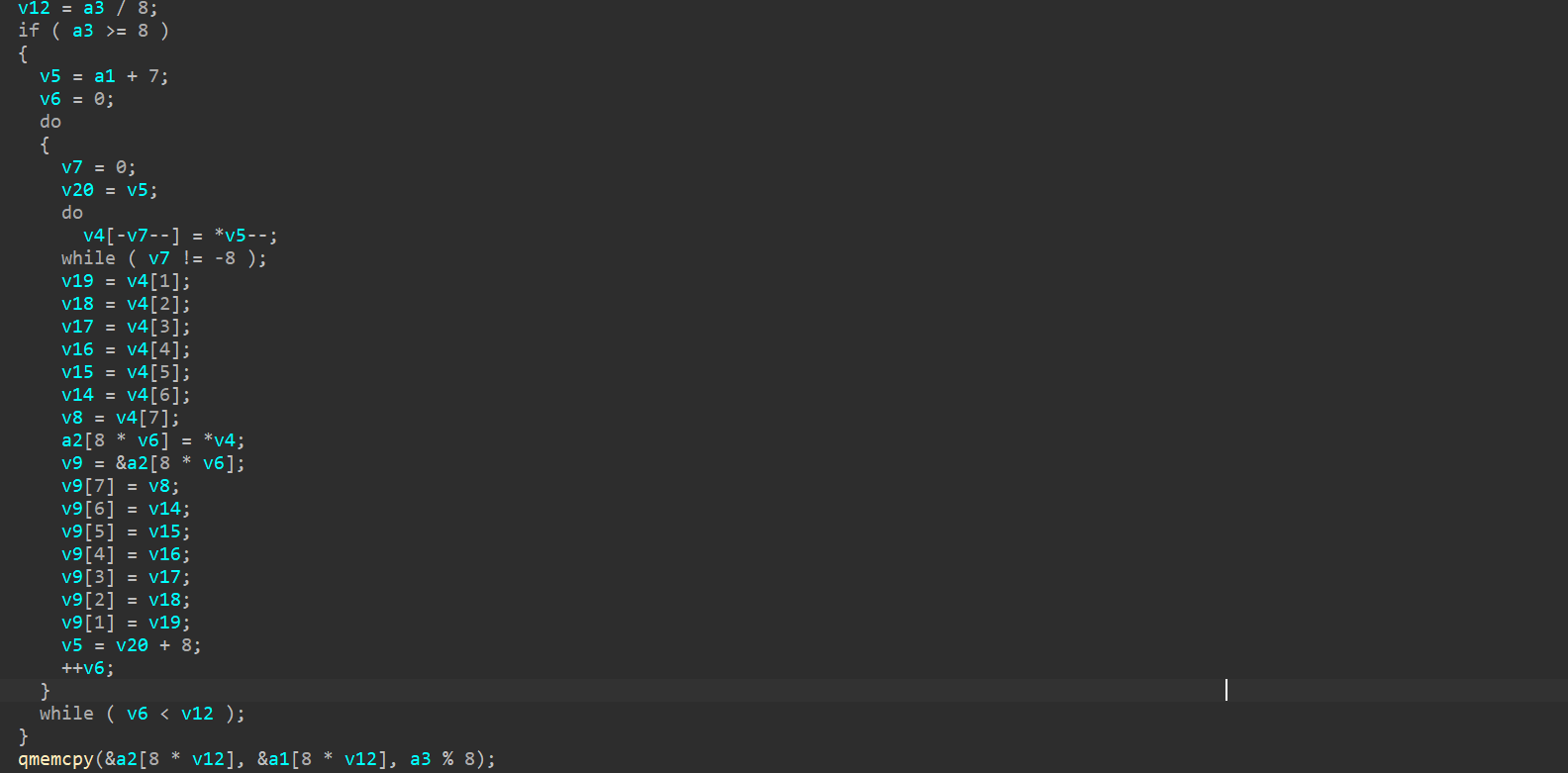
这就是一个简单的交换,以8字节为单位:
def exchange_char(data: bytes) -> bytes:
res = bytearray(data)
for i in range(0, len(data), 8):
res[i:i + 8] = data[i:i + 8][::-1]
return bytes(res)
DecryptCK
该函数大致如下: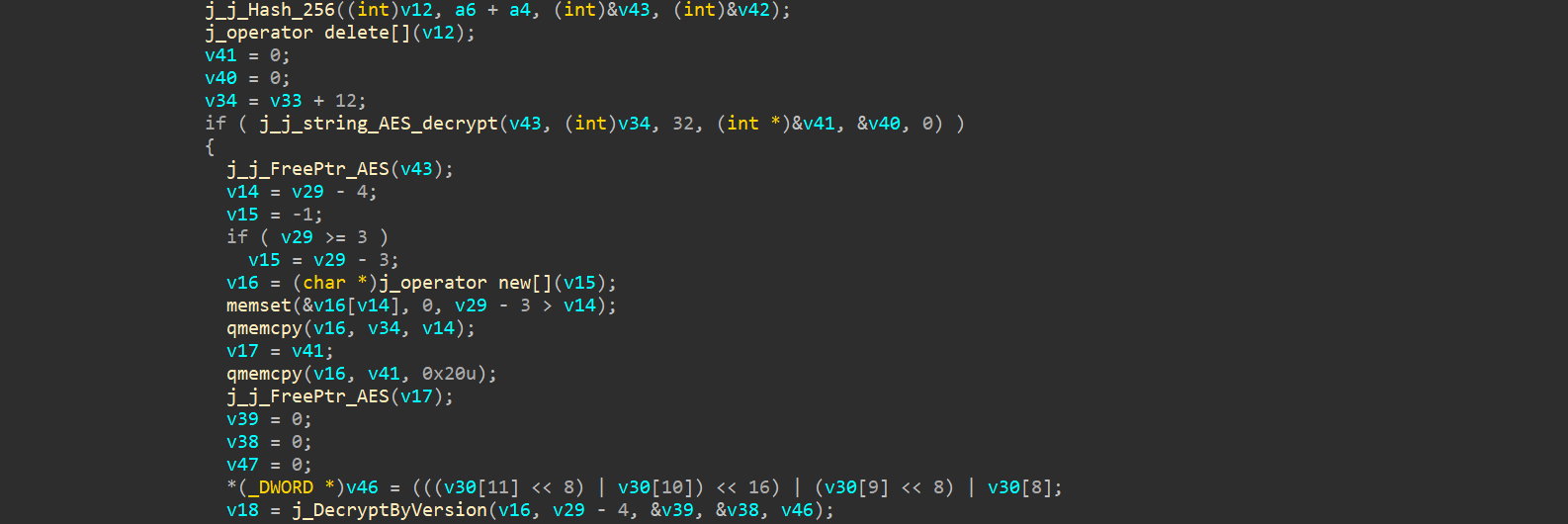
它解密了起始的32字节,并连接剩余数据再用之前分析的算法解码,这里还需要注意AES解密的工作模式,它其实用的是CBC模式,IV被硬编码进去了,全是0:
IV = b'0000000000000000'
def aes_pkcs7pad_decrypt(key: bytes, data: bytes):
key = sha256(key).digest()
cipher = AES.new(key, IV=IV, mode=AES.MODE_CBC)
plain = cipher.decrypt(data)
return pkcs7_unpad(plain)
jddecompress
综上,完本的也解密完了,终于轮到解密书籍的部分了,它们使用了同样的逻辑,就是AES解密之后再解压: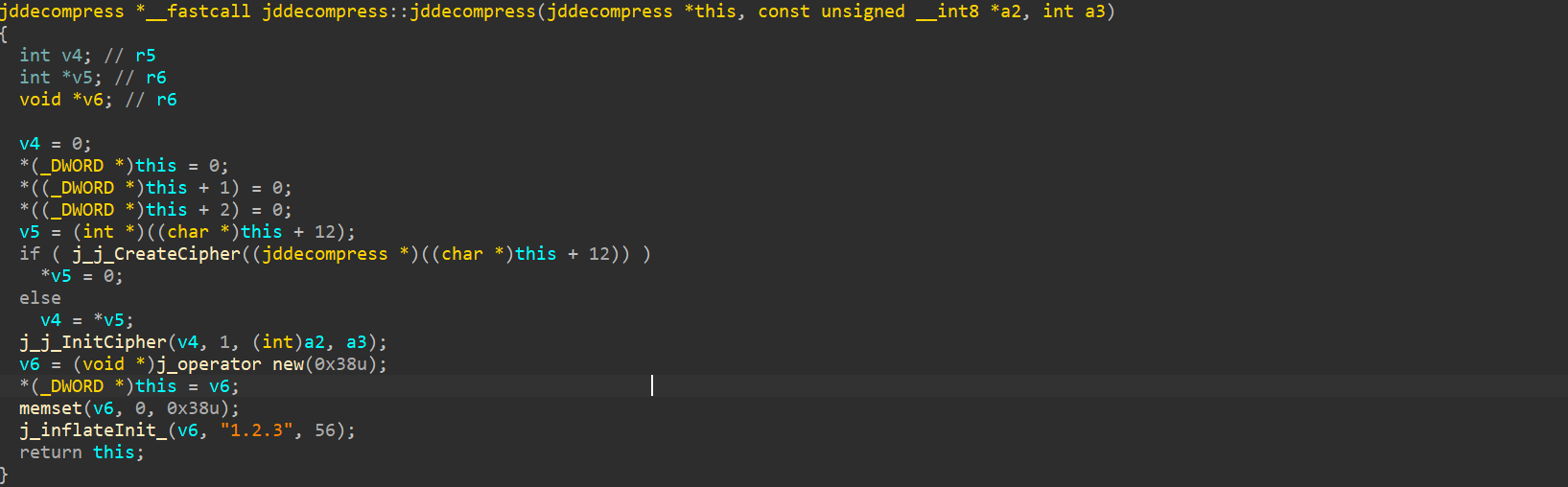
最后就是解密了,主要我想说PDF解密,现在已知PDF使用了filter去加解密数据,需要去写一个解密工具,本来我在网上搜了个库,看了下它不支持自定义过滤器,又打了个补丁让它去解密:
old_get_data = PDFStream.get_data
old_get_filters = PDFStream.get_filters
def get_data(self):
old_filters = old_get_filters(self)
for (f, params) in old_filters:
if f.name == 'JDPDFENCRYPTBY360BUY':
try:
self.rawdata = aes_pkcs7pad_decrypt(key, self.rawdata[:-1])
except Exception as e:
print(e)
return old_get_data(self)
def get_filters(self):
old_filters = old_get_filters(self)
for (f, params) in old_filters:
if f.name == 'JDPDFENCRYPTBY360BUY':
old_filters.remove((f, params))
return old_filters
PDFStream.get_data = get_data
PDFStream.get_filters = get_filters
然鹅,解完密翻代码没找到save方法,翻文档才发现它不支持修改文件...
!!!!最后,根据pdf文件格式,花了好几个晚上写了个简易的解析类才肝出来,简单说下,PDF从尾部向前解析,先读trailer获取xref,再根据它解析对象,对象只需要关注stream对象,把它解密并去掉字典里的过滤器,再调整几个表的偏移即可: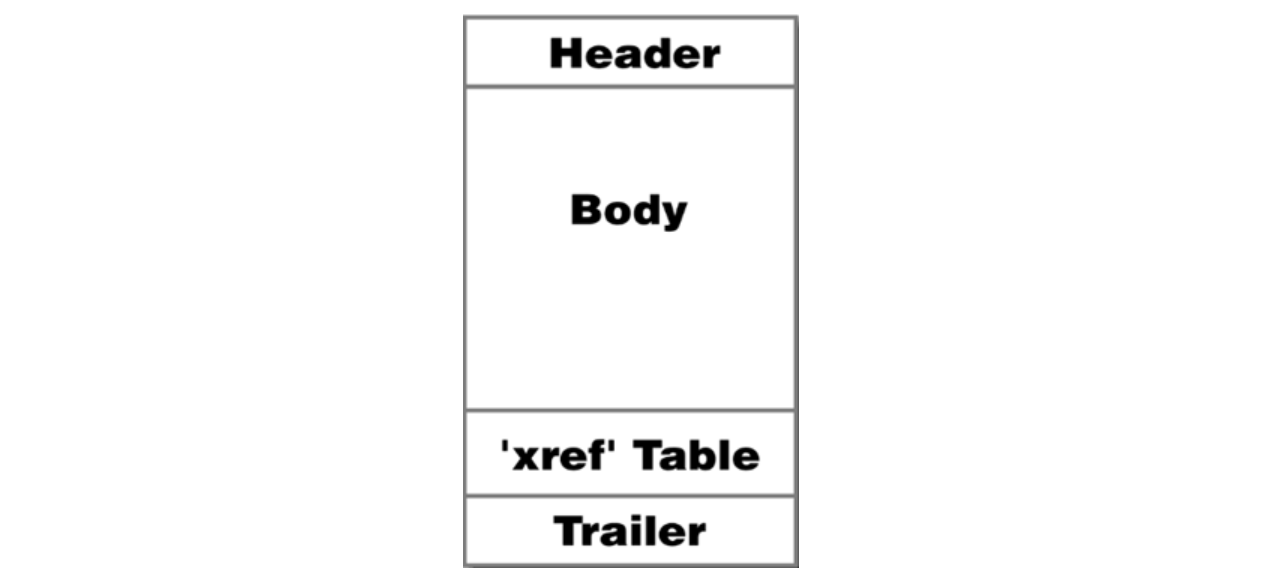
最后的结果如下: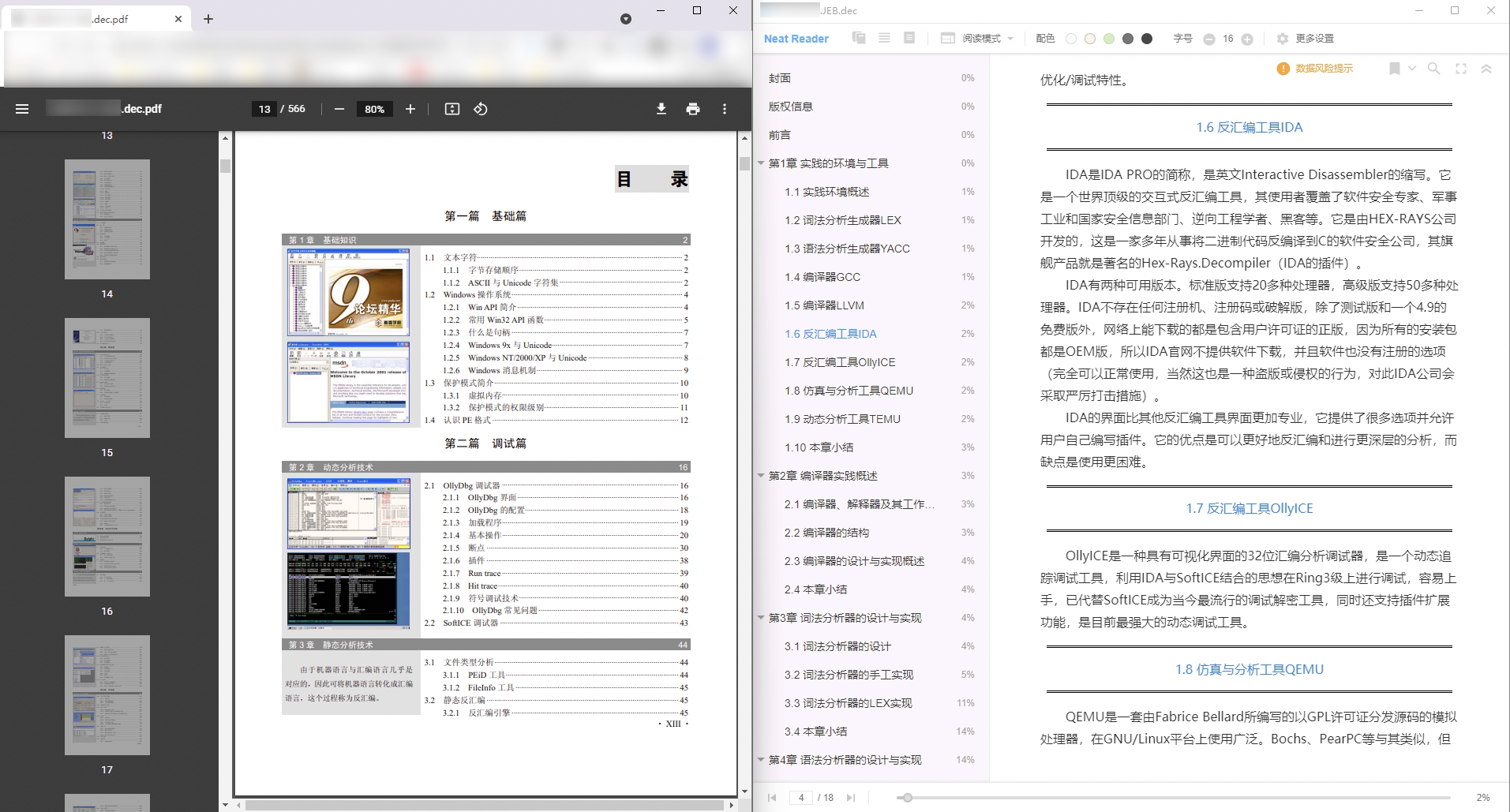
最后最后最后
欢迎孟晚舟回家!!!!!