如果打开一本设备驱动程序的书或者Intel芯片集手册,总是会有PCI这个字样,可见它在外设中的流行度,本篇简单记录下PCI与PCIe的一些规范,帮助理解驱动与设备虚拟化的一些细节,尽管PCI是架构无关的但本文只关注X86架构...
PCI与PCIe
Peripheral Component Interconnect即外围设备互联,是一种流行的局部总线标准,它用于连接外围设备(如网卡,磁盘等),大致可分为旧的并行接口PCI/PCI-X与新的串行接口PCIe,尽管它们在硬件实现上有很大的差异,但是软件层面它们很相似,因此本文无特别说明可认为它们一致,PCI总线可连接PCI设备或者通过桥连接另外的PCI或其他总线,如下:
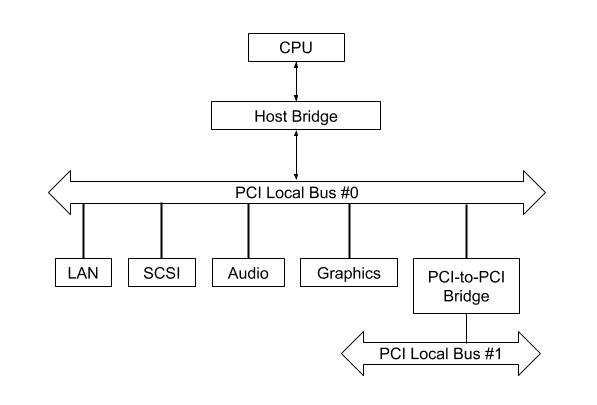
可见CPU与PCI总线通过Host桥相连,Host桥起着数据缓冲与地址转换作用。PCIe在硬件上有很大的不同,如它不再有Host桥,而是用RC(Root Complex)实现类似的功能,另外使用Switch连接设备,使设备能点到点通信。
配置空间
PCI使用单独的地址空间,可使用8位总线(bus)号,5位设备(device)号,3位功能(function)号组成BDF地址,使用该地址可访问PCI的配置空间(也叫配置寄存器 configuration register),对此要使用CPU IO空间的CONFIG_ADDRESS=0xcf8和CONFIG_DATA=0xcfc端口进行数据操作,它们都是32位的(4个8位的连续寄存器组成单个32位),如下图:

其中最高位是配置使能位,因此在访问时BDF地址需要或上0x80000000,关于配置空间读取可参考arch/x86/pci/early.c代码,如下:
u32 read_pci_config(u8 bus, u8 slot, u8 func, u8 offset)
{
u32 v;
outl(0x80000000 | (bus<<16) | (slot<<11) | (func<<8) | offset, 0xcf8);
v = inl(0xcfc);
return v;
}
特别注意,Function表示功能单元,即逻辑设备,一个物理设备可能会实现不同种类的多个功能,此时在逻辑上可认为它们是单独的多个设备,这在SR-IOV中还会遇到。
配置空间是所有PCI设备(包括桥)都有一片区域,原始PCI为256字节,后来扩展为4KB,可认为PCIe为4KB,其中前64字节规范里已定义,后面的地址厂商可自定义(如存放MSI或PM相关的Capability),它们的前0x10字节作用一致,并由HeaderType字段决定0x10之后的布局,如下为HeaderType为0(表示通用类型)时的布局:
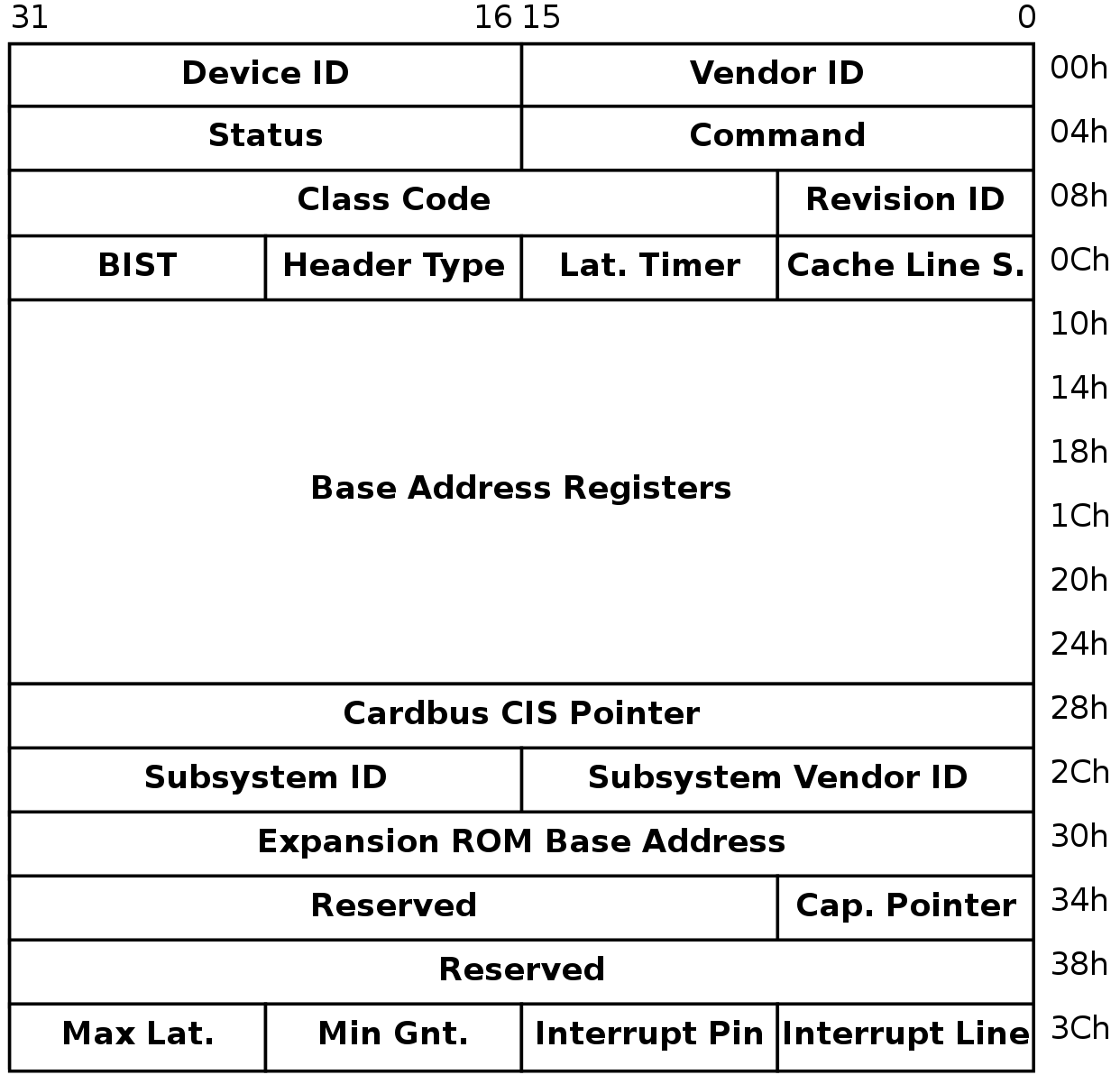
驱动程序通过设备ID与厂商ID识别设备,Status表示设备当前状态,Command用于指定操作,ClassCode可表示设备类型(如网卡,显卡,声卡等),另外需要特别关注的是位于偏移0x10-0x28的最多6个的基地址寄存器BAR,它们每个为32位,其中最低位表明映射类型,是MMIO还是PIO,它由厂商设定用户无法修改,并根据此类型来决定其他位的作用,如当为0时,1-2表示可映射到哪些空间,3表示是否可以预取,不像通常的内存,有些空间读取后状态会改变,因此不能预读,剩下的基地址是16字节对齐的(唯一需要注意当表示可以加载到64位空间时,两个连续的BAR表示基址),如下图:

BAR还有另一个作用,通过向其写入0xFFFFFFFF并读取值,再对其取反加一即可得该位置的大小。 另外还需注意,配置空间只有前256字节支持使用IO指令操作(它其实是一个兼容操作),余下的部分必须使用新的MMIO机制访问,那么当然在PCIe中整个4K范围其实都可以使用MMIO进行读写。
另外在理解PCI时,PCI桥也特别重要,PCI设备的发现使用DFS探测,PCI桥会记录其下的总线与设备使用资源等信息,此处不再详细解释。
设备空间
PCI除了拥有配置空间外,还使用BAR指定额外的空间,BAR的部分位是可写的,CPU通过分配地址空间并将其写入对应的BAR来设置PCI设备的存储位置,x86系列CPU对IO端口支持两种访问方法,即内存映射IO(Memory Map I/O)与端口映射IO(Port Map I/O):
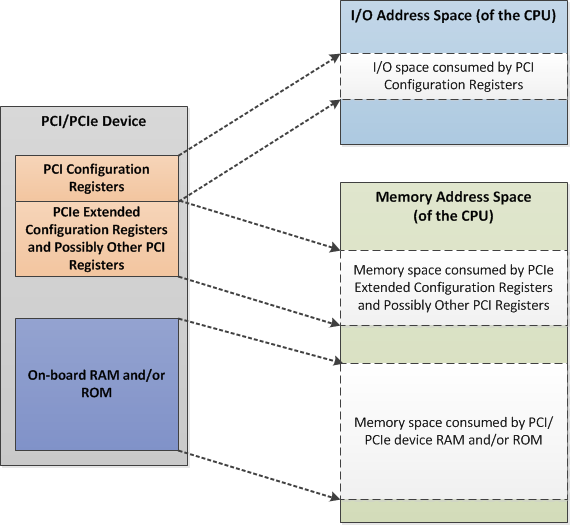
注意,此处的设置是告知设备当收到该地址的请求时作出响应,实际的存储位置是位于设备上的某寄存器或RAM之上。
MMIO
它是和DRAM共享地址空间,也就意味着在传统32位系统上(无PAE),存在使用MMIO的外设时,4G的物理内存并不能完全映射到4G物理地址上,因为MMIO会占用一片区域,如下图:
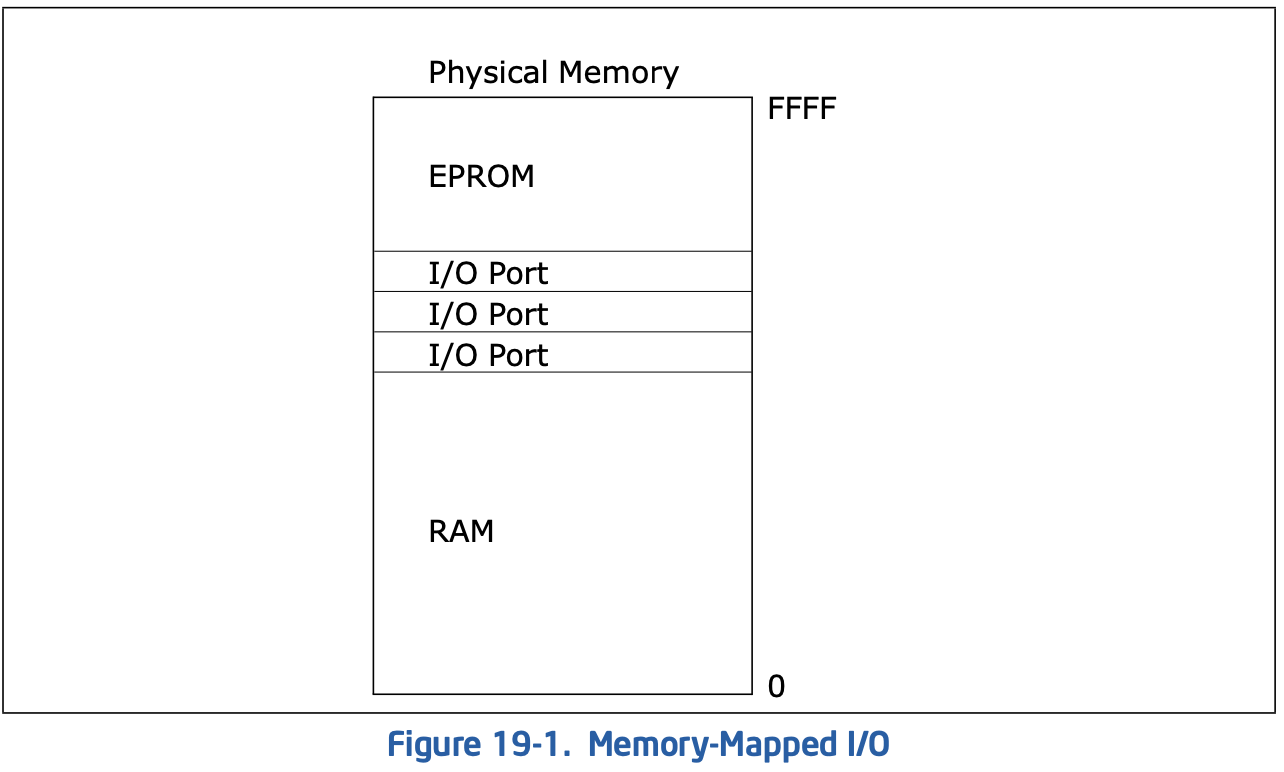
这种映射的优点是访问IO端口时和访问普通内存一致,可使用各类指令,而且对IO端口的保护由段页机制实现。使用这种方式,需要将分配的物理地址空间(注意不是分配内存)标记为MMIO类型,这样在访问时,MCH就知道是该让SDRAM去响应还是让外围设备去响应,另外还需要将这片空间的起始地址写入对应的BAR,之后设备会监听对该地址区域的访问,并对其进行响应。
在Linux下常用如下API进行使用:
struct resource* request_mem_region ( unsigned long start, unsigned long n, const char *name); // 注册要使用的内存区域
void* ioremap(unsigned long phys_addr, unsigned long size, unsigned long flags); // 建立页表映射
unsigned int ioread32(void __iomem *addr); // 使用
void iounmap ( void * addr); // 释放内存
void release_mem_region ( unsigned long start, unsigned long n); // 释放资源,即删除注册的信息
可通过iomem查看内存地址空间注册情况:
root@bm:~# cat /proc/iomem
00000000-00000fff : Reserved
00001000-0009e7ff : System RAM
0009e800-0009ffff : Reserved
000a0000-000bffff : PCI Bus 0000:00
000c0000-000c7fff : Video ROM
000ca000-000cafff : Adapter ROM
000cc000-000cffff : PCI Bus 0000:00
000dc000-000fffff : Reserved
000f0000-000fffff : System ROM
00100000-bfecffff : System RAM
bfed0000-bfefefff : ACPI Tables
bfeff000-bfefffff : ACPI Non-volatile Storage
...
PIO
这是一个独立的地址空间,x86系列有4k(65536)个可用地址,即0x0000-0xFFFF,每个地址能访问8位io端口,也可以把两个连续地址合并访问16位端口,4个连续地址合并访问32位端口,尽管这里的合并不要求对齐,但是对齐性能更好。这种映射的访存需要专用指令,如inb/outb等,但它不占用物理地址空间,因此它也叫isolated I/O,该种方式的访存保护由EFLAGS寄存器中对应的标志位确定,另外TSS中也有port map用于指定在非特权时能访问哪些端口:
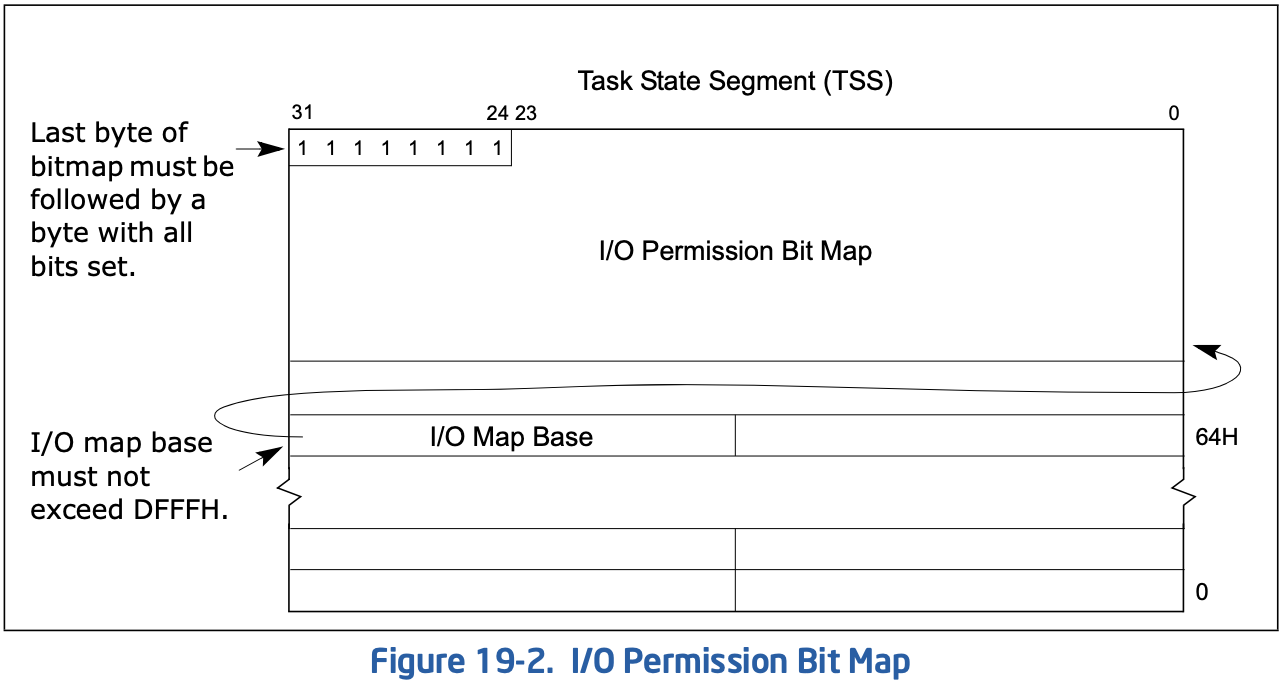
在Linux下使用常用如下的API:
void request_region(unsigned long from, unsigned long num, const char *name); // 注册一片资源
unsigned char inb(unsigned short int port); // 对inb汇编指令的封装,读数据
另外可通过ioports查看io端口使用:
root@bm:~# cat /proc/ioports
0000-0cf7 : PCI Bus 0000:00
0000-001f : dma1
0020-0021 : PNP0001:00
0020-0021 : pic1
0040-0043 : timer0
0050-0053 : timer1
0060-0060 : keyboard
0061-0061 : PNP0800:00
0064-0064 : keyboard
0070-0071 : rtc0
0080-008f : dma page reg
00a0-00a1 : PNP0001:00
...
DMA
回忆一下计组,以前外设要和内存交换数据需要经过CPU,这当然不好,于是有了直接内存访问(Direct Memory Access),它使外设可以直接与内存交换数据。例如网卡的实现中,它会告诉外设从内存的哪个地址存放数据,于是当接收到数据时它可以直接写入到内存固定区域,再向系统发送中断请求,此时CPU就可以直接操作内存中的数据了。
在使用DMA时,有两个点需要关注:
- 内存分配:外设需要一片内存进行读写,对这片内存操作时不会经过MMU,因此有两个问题,设备寻址范围可能有限,如早起ISA设备可能只有24根地址线,只能寻址16M的内存;另一个问题是系统在运行一段时间后内存会碎片化,可能不能找到满足大小的连续内存页。在虚拟直通设备中这些问题可能更加严重,还好出现了分散/聚集技术与IO虚拟化技术可以解决这些问题。
- 一致性:在DMA系统中有多个组件能主动访问存储器,这可通过总线仲裁来保证一致,而CPU还有高速Cache挡在中间,此处就需要软件或硬件实现一致性了。
在Linux下要使用dma一般使用如下API:
/* 用于设置设备所支持的dma寻址位数 */
int dma_set_mask(struct device *dev, u64 mask);
/* 为设备分配一致性DMA空间,其实就是寻找个合适的位置建立页表,它的返回值是虚拟地址,而第三个参数是物理地址 */
void* dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, int falg);
/* 一致性dma映射池用于小内存情形 */
struct dma_pool *dma_pool_create(const char *name,struct device *dev, size_t size,size_t align, size_t allocation); // 创建一个dma池
void *dma_pool_alloc(struct dma_pool *pool,int mem_flags,dma_addr_t *handle); // 从dma池中分配空间
/* 建立流式DMA映射,它的第四个参数指定了数据的传输方向,使用它可建立回弹缓冲区 */
dma_addr_t dma_map_single(struct device *dev,void *buffer,size_t size, enum dma_data_direction direction);
/* 流式dma在映射后取消映射前禁止CPU访问,此时可使用此函数将控制权转移给CPU */
void dma_sync_single_for_cpu(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_directction direction);
/* 当控制权给CPU后设备不应该访问,CPU访问结束应使用此函数交还控制权 */
void dma_sync_single_for_device(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_direction direction);
中断
之前的两篇从硬件机制与软件实现两个角度描述了PIC在收到中断后如何投递给CPU,CPU又是如何处理它们的,此处描述PCI外设是如何将中断投递给PIC的。
IRQ
这是最原始的形式,PCI设备必须支持该方式,每个PCI设备可拥有INTA#到INTD#四根请求线,通过PCI总线最终与PIC相连,当需要请求中断时,它通过该引脚发送信号到PIC,CPU再通过状态寄存器定位到中断源。一般来说设备只会使用一个中断请求线,此时它们必须使用INTA#引脚,为了均衡PCI插槽之间一般会采用如下方式相连:
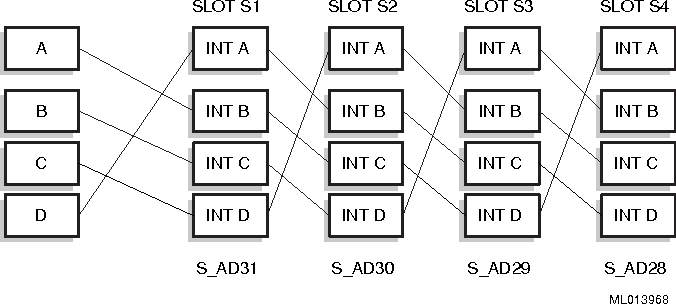
此时插入的四个使用INTA#的设备最终会使用到PIC的四个不同引脚。由于PCI的易扩展性,有时人们并不知道某设备使用的是哪个中断引脚,在X86上一般是采用一种推荐的映射关系并由BIOS维护中断路由表记录这种关系,如下:

另外PCI的配置空间里有两个寄存器与它相关:
- Interrupt Line:记录当前设备使用的中断向量号。
- Interrupt Pin:记录该设备使用哪个引脚向PIC发送中断请求。
注:对于普通设备,需要探测中断,一般的探测方法要么是对所有中断号注册中断服务例程并让设备发出中断,再根据服务例程获取到中断号,另外也可以直接让设备发送中断,通过检查状态位看哪个IRQ出现了IRQ_WAITING来识别中断,但PCI设备能直接通过 提供中断号免去了探测的过程。
MSI/MSI-x
中断硬件里已经提过,在APIC里每个核心都有自己的中断控制器,它使用前端总线中断(FSB Interrupt Message)事务进行中断传输,不再必须使用中断线来实现中断请求,也不再需要INTA脉冲获取中断向量号,PCI在后来的规范中也规定了可使用该机制的中断请求方式,即MSI(Message Signal Interrupt)与其升级版MSI-x,PCI不强制实现它们俩,PCIe必须实现它们之一。MSI通过Capability ID=xx识别,其结构如下:

MSI-x作为它的升级版,它的格式如下,可见它新增了一张MSI-x表专门用于存放中断消息的地址与数据,这张表位于BAR所指区域,使用时需要根据BIR获取区域基址加上表偏移获取表地址,使用单独的表使它的中断号不必连续:

现在在PCI上基本见不到IRQ形式的中断请求了,但是经常在驱动中看到一个叫做Legacy的,它会使用INTx封装函数,其实是一种兼容实现,它通过消息模拟了INTx线。
虚拟化
一提到虚拟化一般会想到虚拟机,其实普通的系统也用到了很多虚化技术,例如在每个进程看来它都拥有整个地址空间就是内存空间的虚拟化,虚拟化技术最直接的目的就是提高设备利用率与性能的,如下是几个和PCI相关的硬件虚拟化技术:
IOMMU/VT-d
类似MMU,IOMMU是对外设而言的地址转换单元,内存地址映射实现了两个功能:
- 隔离:不同进程间的内存不能相互访问,一个进程做的所有操作不会影响到其他进程,它访问不了其他进程的数据。
- 独占:在单一进程看来它独占了整个地址空间,它可以任意使用地址而不必担心该地址已被其他进程占用。
IOMMU技术也是为了实现类似的功能的,上面已经提到,外设对主存储器的访问是不经过MMU的,因此它可以读写任意内存,这不仅影响系统的稳定性,还有极大的安全隐患,另一个问题是一些外设能访问的地址空间是有限的,一些外设需要大片连续的物理地址,因此只能把一些区域预留下来应对外设可能的需求,这不仅可能造成浪费,而且在外设过多时可能也根本无法满足要求。而这在虚拟化时问题更加明显:
- 对于客户机,它所以为的物理地址(PA)其实是客户机物理地址(GPA),这个地址要经过EPT或影子页表转换才是外设所需的宿主机物理地址(HPA),这之间的地址转换必须由VMM进行,包括双向的寄存器地址值与存储访问地址
- 客户机在访问外设时不会有感知,在它的视角它有访问整个外设的权限,但外设一般不会被某个客户机独占,某个客户机也不能独占系统所有外设,因此为了安全与功能可用性必须对这加以限制,这增加了VMM实现的复杂性

其实IOMMU是amd的命名,VT-d是intel的命名,它们使用了不同的方式实现了相同的功能,显然IOMMU更直观,因此尽管本文只关注intel实现但是也使用这个名字。类似MMU,该系统使用TA(Translation Agent)根据ATPT(Address Translation and Protection Table)做地址转换,外设使用的PCI总线域地址被HOST桥/RC转换为存储器域地址,但这个地址不是内存的真实地址,例如在虚拟化下它其实是GPA,还需再由TA转换为HPA,为了提升地址转换的速度还可实现IOTLB,和TLB类似它用于缓存这种转换关系:
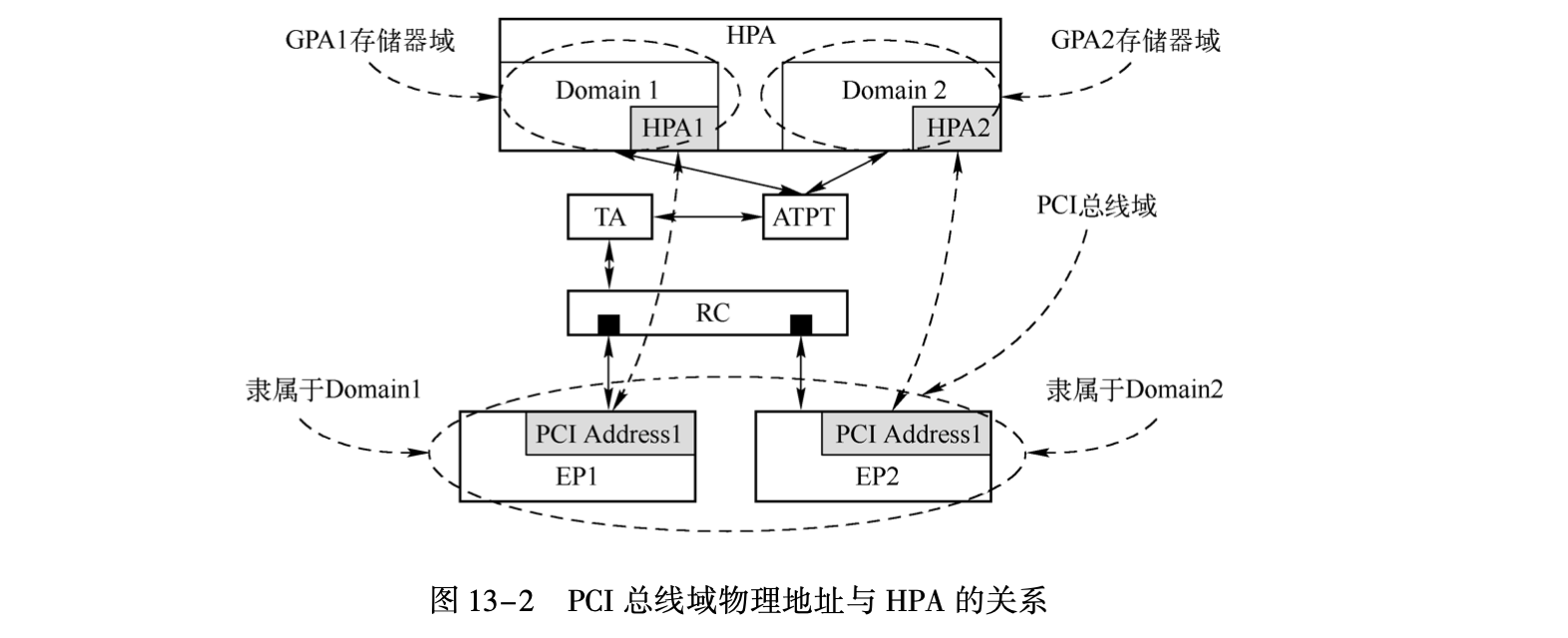
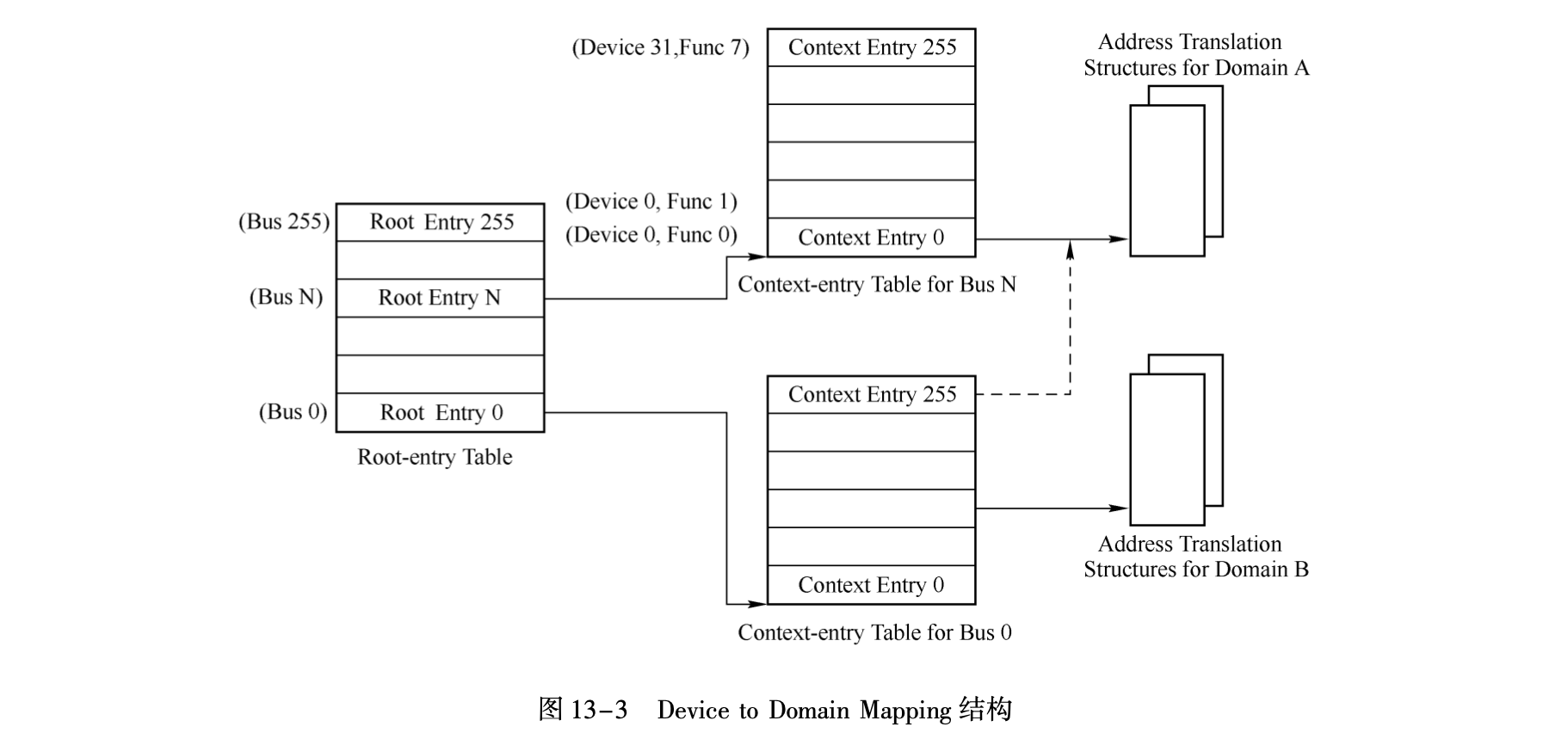
在Intel下它使用DMA remapping实现,它使用BDF地址索引转换表,如下它的总线对应着Root-entry Table,其下每个Function对应一个Context-entry Table,后者记录真正的转换表的地址,由于一个虚拟机用的GPA是一样的,因此多个Function可以共用ATPT以节省空间:
SR-IOV
在虚拟化中,对物理外设的使用在全虚拟化时一般有两种方式:
- 代理方式:Guest不直接与外设交互,Guest访问外设操作被VMM拦截,它代理访问外设,并把结果再转发回Guest,此时设备由VMM管理,因此该设备可以被多客户机同时使用。
- 直通方式:VMM不再直接管理外设,而是把它交给Guest,此时像内存拷贝这些操作就不必再经过VMM了,此时效率会提高很多,但是外设是被某一客户机独占了。
再回到一般情况,系统使用设备时一般一个硬件在系统视角就是一个设备,那么它是有瓶颈的,经分析发现它有些硬件还可以复用,再在此基础上添加几个硬件就能成倍提高性能,此时在系统视角就像有多个设备,相关技术有多队列,单根IO虚拟化(Single-Root IO Virtualization),多根IO虚拟化(Multi-Root IO Virtualization)等,多队列会在网卡中再提,此处谈谈PCI里的SR-IOV,相对于MR-IOV可虚拟总线,SR-IOV主要虚拟单个设备,设备原来的功能叫做物理功能(PF),在此上虚拟的功能叫做VF,它们会共享配置空间,但每个设备会有有独立的BAR空间,如下:
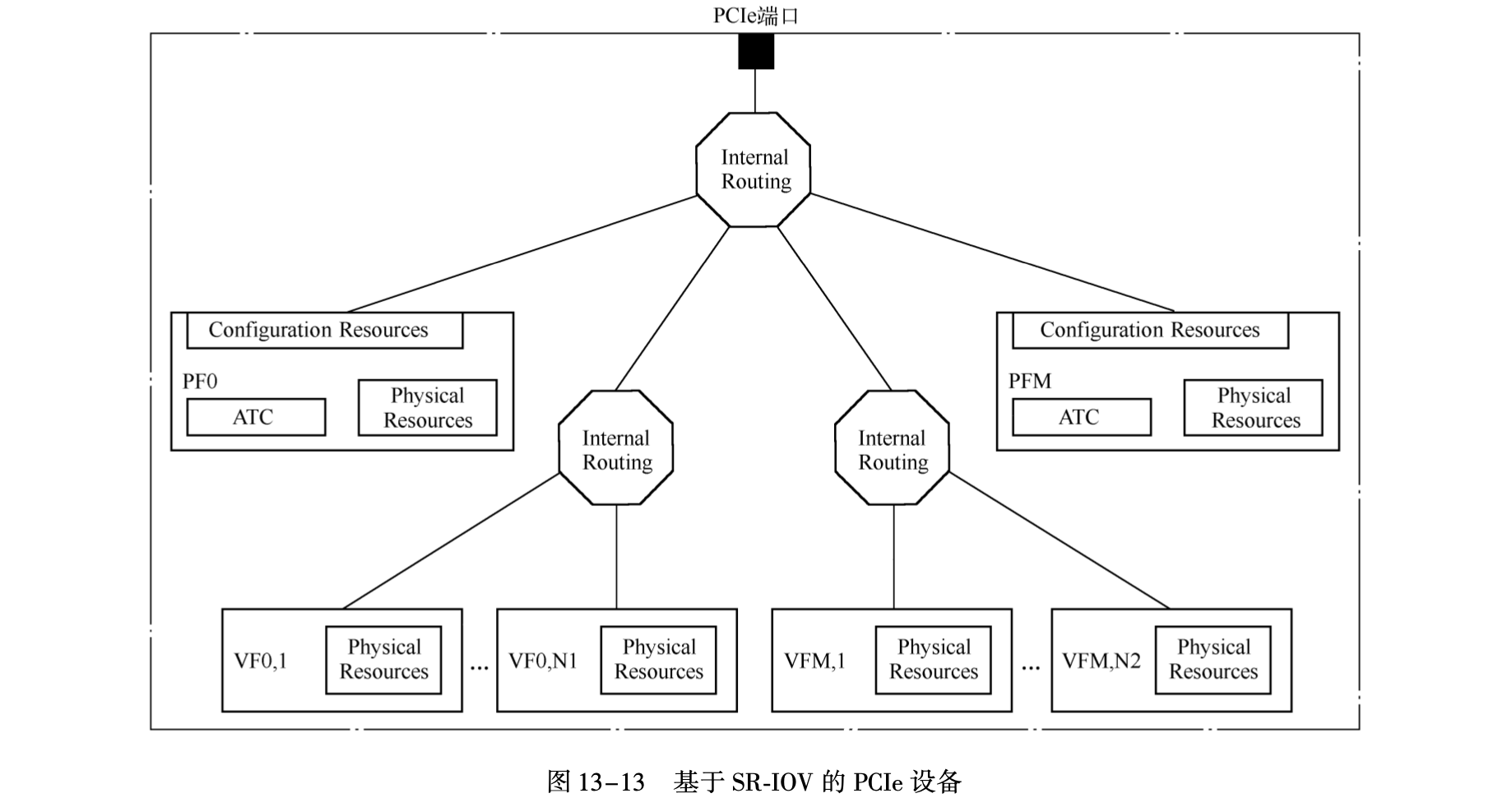
注:根据"Efficient High-Performance Computing with Infiniband Hardware Virtualization"VF没有单独的配置空间,它不能被配置因为它不能访问物理设备,PF与其下的VF拥有同样的配置,若VF修改配置则将会影响所有设备,但微软的"SR-IOV Virtual Functions (VFs)"又说每个VF有它自己的配置空间,疑惑🤔,先按前者理解吧!
Linux下的PCI
一般打开一本讲解驱动开发的书或直接看网卡的驱动,总是会感到迷惑,它们直接使用BAR空间而并没有初始化,实际上这部分的初始化是由其他固件程序与驱动完成的,首先BIOS/ACPI等会初始化PCI,Linux在rest_init中也会进行PCI总线枚举并初始化(当然PCI支持热插拔,这部分应该机制类似),这个过程很繁琐就不记了,知道这事就👌。
Linux对PCI操作进行了封装,常见操作如下:
int pci_register_driver(struct pci_driver *drv); // 注册设备
int pci_enable_device(struct pci_dev *dev); // 激活设备,设置IORESOURCE_MEM|IORESOURCE_IO标志
void pci_set_master(struct pci_dev *dev); // 设为主设备,表示能主动获取总线
int pci_set_consistent_dma_mask(struct pci_dev *dev, u64 mask); // 设置掩码
int pci_request_regions(struct pci_dev *dev, const char *res_name); // 注册pci设备所需的资源
在用户空间,可使用lspci命令查看存在的pci设备,配置空间,对应的驱动等信息:
mao@bm:~$ lspci -t -v -nn
-[0000:00]-+-00.0 Intel Corporation 440FX - 82441FX PMC [Natoma] [8086:1237]
+-01.0 Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II] [8086:7000]
+-01.1 Intel Corporation 82371SB PIIX3 IDE [Natoma/Triton II] [8086:7010]
+-01.2 Intel Corporation 82371SB PIIX3 USB [Natoma/Triton II] [8086:7020]
+-01.3 Intel Corporation 82371AB/EB/MB PIIX4 ACPI [8086:7113]
+-02.0 Cirrus Logic GD 5446 [1013:00b8]
+-03.0-[01]--
+-04.0-[02]--
+-05.0 Red Hat, Inc. Virtio network device [1af4:1000]
+-06.0 Red Hat, Inc. Virtio block device [1af4:1001]
\-07.0 Red Hat, Inc. Virtio memory balloon [1af4:1002]
mao@bm:~$ sudo lspci -v -x -s 00:05.0
00:05.0 Ethernet controller: Red Hat, Inc. Virtio network device
Subsystem: Red Hat, Inc. Virtio network device
Physical Slot: 5
Flags: bus master, fast devsel, latency 0, IRQ 10
I/O ports at e060 [size=32]
Memory at fea23000 (32-bit, non-prefetchable) [size=4K]
Memory at fe400000 (64-bit, prefetchable) [size=16K]
Expansion ROM at fea10000 [disabled] [size=64K]
Capabilities: [98] MSI-X: Enable+ Count=3 Masked-
Capabilities: [84] Vendor Specific Information: VirtIO: <unknown>
Capabilities: [70] Vendor Specific Information: VirtIO: Notify
Capabilities: [60] Vendor Specific Information: VirtIO: DeviceCfg
Capabilities: [50] Vendor Specific Information: VirtIO: ISR
Capabilities: [40] Vendor Specific Information: VirtIO: CommonCfg
Kernel driver in use: virtio-pci
00: f4 1a 00 10 07 05 10 00 00 00 00 02 00 00 00 00
10: 61 e0 00 00 00 30 a2 fe 00 00 00 00 00 00 00 00
20: 0c 00 40 fe 00 00 00 00 00 00 00 00 f4 1a 01 00
30: 00 00 a1 fe 98 00 00 00 00 00 00 00 0a 01 00 00
另外也可以从sys分区查看使用的资源等动态信息:
mao@bm:~$ sudo ls -la /sys/devices/pci0000\:00/0000\:00\:05.0/
-rw-r--r-- 1 root root 4096 Dec 20 20:24 broken_parity_status
-r--r--r-- 1 root root 4096 Sep 30 16:59 class
-rw-r--r-- 1 root root 256 Sep 30 16:59 config
-r--r--r-- 1 root root 4096 Sep 30 16:59 device
-r--r--r-- 1 root root 4096 Dec 20 20:24 dma_mask_bits
lrwxrwxrwx 1 root root 0 Sep 30 16:59 driver -> ../../../bus/pci/drivers/virtio-pci
-rw-r--r-- 1 root root 4096 Dec 20 20:24 driver_override
drwxr-xr-x 2 root root 0 Dec 20 20:24 msi_irqs
-rw-r--r-- 1 root root 4096 Dec 20 20:21 numa_node
drwxr-xr-x 2 root root 0 Dec 20 20:24 power
--w--w---- 1 root root 4096 Dec 20 20:24 remove
--w--w---- 1 root root 4096 Dec 20 20:24 rescan
-r--r--r-- 1 root root 4096 Sep 30 16:59 resource
...
参考
- OS Dev:PCI configuration space,PCI
- 《Accessing PCI Express Configuration Registers Using Intel Chipsets》
- https://blog.naver.com/zauber99/220027202600
- 《PCI Express 体系结构导读》-- 王齐[著]