本文打算放一些实例,之后慢慢补充,尽量每种类型的扔一个上来...
沙盒逃逸
此处放两个例子吧:
🌰壹
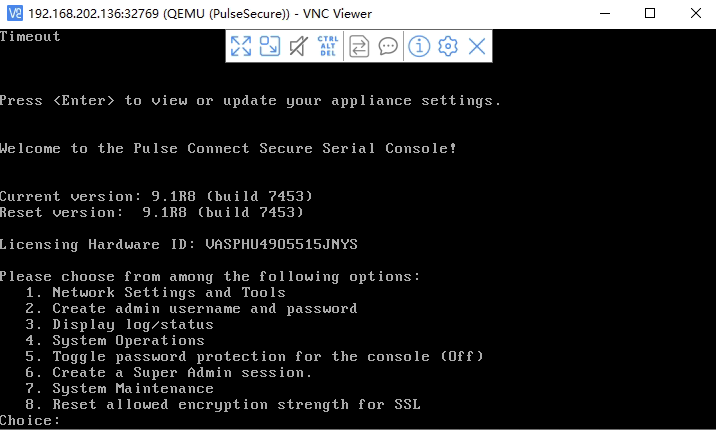
这是某设备,开机后只有一个沙盒shell,因此需要先越狱:
 首先关机将磁盘挂载出来,使用如下命令:
首先关机将磁盘挂载出来,使用如下命令:
# 加载nbd模块
modprobe nbd
# 映射文件,注:此处为新建的文件
qemu-nbd -c /dev/nbd0 /opt/unetlab/tmp/0/c43d9d9f-d79b-4d72-b603-de8eaed816b5/1/virtioa.qcow2
# 若使用ls /dev/nbd0看不到分区,可使用如下命令刷新
#partx -a /dev/nbd0
之后可见有如下分区:
root@eve-ng:/opt/unetlab/addons/qemu# fdisk -l /dev/nbd0
Disk /dev/nbd0: 40 GiB, 42949672960 bytes, 83886080 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x185e607a
Device Boot Start End Sectors Size Id Type
/dev/nbd0p1 1 66527 66527 32.5M 83 Linux
/dev/nbd0p2 66528 133055 66528 32.5M 83 Linux
/dev/nbd0p3 133056 199583 66528 32.5M 83 Linux
/dev/nbd0p4 199584 83885759 83686176 39.9G 85 Linux extended
/dev/nbd0p5 199585 6491519 6291935 3G 83 Linux
/dev/nbd0p6 6491521 14881103 8389583 4G 83 Linux
/dev/nbd0p7 14881105 32356799 17475695 8.3G 83 Linux
/dev/nbd0p8 32356801 40746383 8389583 4G 83 Linux
/dev/nbd0p9 40746385 58222079 17475695 8.3G 83 Linux
/dev/nbd0p10 58222081 66414095 8192015 3.9G 82 Linux swap / Solaris
/dev/nbd0p11 66414097 83885759 17471663 8.3G 83 Linux
其中前三个分区大小一致,猜测为启动分区及备份,其他为主要工作分区,查看分区类型:
root@eve-ng:/tmp# blkid
/dev/mapper/eve--ng--vg-root: UUID="9164c943-55e6-45c6-88a0-2dea4ca1a815" TYPE="ext4"
/dev/mapper/eve--ng--vg-swap_1: UUID="626a6157-4ae7-4138-978a-7de2ad9f5b52" TYPE="swap"
/dev/nbd0p1: UUID="39f25811-f73a-4634-a659-d2b9dab96ec8" TYPE="ext2" PARTUUID="185e607a-01"
/dev/nbd0p2: UUID="834bbeb9-028d-4f5d-97c1-43a8c9718d45" TYPE="ext2" PARTUUID="185e607a-02"
/dev/nbd0p3: UUID="45f2e82c-0613-4e68-abeb-577dfb155191" TYPE="ext2" PARTUUID="185e607a-03"
/dev/nbd0p5: UUID="wSy3Dh-1cNX-D5hf-sKTD-lOxp-LSBt-da1axE" TYPE="LVM2_member" PARTUUID="185e607a-05"
/dev/nbd0p6: UUID="iAFqTI-hLrP-v1Nb-48ap-65jA-6xln-EmsqiO" TYPE="LVM2_member" PARTUUID="185e607a-06"
/dev/nbd0p7: UUID="W1Ix6I-i2LH-SWM1-uE2z-iDs3-v3FB-jjxRH5" TYPE="LVM2_member" PARTUUID="185e607a-07"
/dev/nbd0p10: UUID="Glnag3-g1aM-ai9x-m1Bc-id7E-nbf8-7grZay" TYPE="LVM2_member" PARTUUID="185e607a-0a"
/dev/nbd0: PTUUID="185e607a" PTTYPE="dos"
/dev/nbd0p8: PARTUUID="185e607a-08"
/dev/nbd0p9: PARTUUID="185e607a-09"
/dev/nbd0p11: PARTUUID="185e607a-0b"
可知前几个分区可挂载,先挂载后查看内容:
root@eve-ng:/tmp# mkdir /tmp/nbd0p1 /tmp/nbd0p2 /tmp/nbd0p3
root@eve-ng:/tmp# mount /dev/nbd0p1 /tmp/nbd0p1/
root@eve-ng:/tmp/nbd0p1# ls
boot.b coreboot.img grub kernel log_coreboot lost+found map VERSION
root@eve-ng:/tmp/nbd0p1# file kernel
kernel: Linux kernel x86 boot executable bzImage, version 2.6.32-00025-g841d072-dirty (slt_ec_builder@lxc-linux64-0005-sc, RO-rootFS, swap_dev 0x3, Normal VGA
root@eve-ng:/tmp/nbd0p2# cat lilo.4
...
image=/tmp/boot/kernel
label=current
read-only
initrd=/tmp/boot/coreboot.img
append="console=ttyS0,115200n8 console=tty0 vm_hv_type=KVM system=A "
...
挂载lvm卷:
pvscan --cache /dev/nbd0p* && vgscan && lvscan && vgchange -ay
查看类型为cryto_LUKS:
root@eve-ng:/tmp/nbd0p2# blkid
....
/dev/mapper/groupA-home: UUID="522714dc-1044-43df-9a38-cec1d69e1eb6" TYPE="crypto_LUKS"
/dev/mapper/groupA-runtime: UUID="65247d13-1f39-44e5-9046-b793413a7b56" TYPE="crypto_LUKS"
/dev/mapper/groupZ-home: UUID="5622f1a9-b80b-4a9e-8fe5-46546215f457" TYPE="crypto_LUKS"
/dev/mapper/groupS-swap: UUID="ef3a5470-06b2-4dce-a0d9-3dc98cf26a49" TYPE="crypto_LUKS"
luks可以看我旧博客的内容,此处首先编辑eveng里的ps,添加监视器参数-monitor telnet::9000,server,之后启动ps并使用nc连接监视器,执行如下命令dump内存:
(qemu) dump-guest-memory mem.dump
dump-guest-memory mem.dump
使用findaes获取内存中所有的aes密钥:
❯ .\findaes.exe C:\Users\betamao\Desktop\mem.dump
Searching C:\Users\betamao\Desktop\mem.dump
Found AES-256 key schedule at offset 0x425caeac:
6d 68 c8 ee 96 2d cd a1 32 16 0b 3d 7a 32 01 ac b7 82 a0 ef 16 fb 57 8a 36 38 3e b9 d6 9d 9f d7
Found AES-256 key schedule at offset 0x425cafd4:
00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f
.....
通过密钥对比获取到三个主密钥:
/dev/mapper/groupA-home => b47eb4242d36a3b20f7759a80824d8ebde05609a5bc0c24f6de4048b7077677d
/dev/mapper/groupZ-home => 未获得
/dev/mapper/groupA-runtime => 9cfa99bbb06c44d779a72a03468429b54d322f19007972da579a715de59d6e19
解密磁盘,可以看到根文件系统了:
root@eve-ng:~# cryptsetup luksAddKey /dev/mapper/groupA-home --master-key-file <(echo 'b47eb4242d36a3b20f7759a80824d8ebde05609a5bc0c24f6de4048b7077677d' | xxd -r -p)
Enter new passphrase for key slot: toor
Verify passphrase: toor
root@eve-ng:~# cryptsetup luksAddKey /dev/mapper/groupA-runtime --master-key-file <(echo '9cfa99bbb06c44d779a72a03468429b54d322f19007972da579a715de59d6e19' | xxd -r -p)
Enter new passphrase for key slot: toor
Verify passphrase: toor
root@eve-ng:~# cryptsetup luksOpen /dev/mapper/groupA-home gah
Enter passphrase for /dev/mapper/groupA-home:
root@eve-ng:~# cryptsetup luksOpen /dev/mapper/groupA-runtime gaz
Enter passphrase for /dev/mapper/groupA-runtime:
root@eve-ng:~# mkdir /tmp/gah /tmp/gaz
root@eve-ng:~# mount /dev/mapper/gah /tmp/gah
root@eve-ng:~# mount /dev/mapper/gaz /tmp/gaz
root@eve-ng:~# cd /tmp/gah/root/
root@eve-ng:/tmp/gah/root# ls
2.6.32.358-x86_64 boot data etc lib mnt opt proc sbin tmp va webserver
bin cgroups dev home lib64 modules pkg runtime sys usr var
若能直接利用漏洞进入,也能通过如下方式dump出密钥:
[Sif-YY]$ dmsetup table --target crypt --showkey
sda8_crypt: 0 15618048 crypt aes-xts-plain64 ae35655cd789d40f1c959b79cb7846a07d956d17c6e41e48bd5b847c38316c5177ce228c2f3ea699a65a3d74dd14951c3fe776ddc31fc249dfaf40a917bf224f 0 8:8 4096
sda2_crypt: 0 19527680 crypt aes-xts-plain64 d5b57bb704dfc8f3f55100e2c26413bb39fe5a54fdb9ed3eab5398d0080adef5cbb122ae3b5c2431a36468c72f41ea444b4a086849cd457f11f2fe6dec86b935 0 8:2 4096
sda6_crypt: 0 19525632 crypt aes-xts-plain64 0316ebb8a814460401753fcd875921bcafb4b542e0ac16e0c9d9102b5bd6b66130d1216500053b83dcec3cf0f052fe6c5142d3e7832514eabb3a93c36ad38ab0 0 8:6 4096
解密磁盘后,分析/sbin/init程序发现最终会启动/home/bin/dsconfig.pl,于是将其替换为/bin/bash,另外/home/boot.pl中会调用/home/bin/check_integrity.sh对所有文件进行完整性校验,由于无私钥最简单的办法是让其返回恒0:
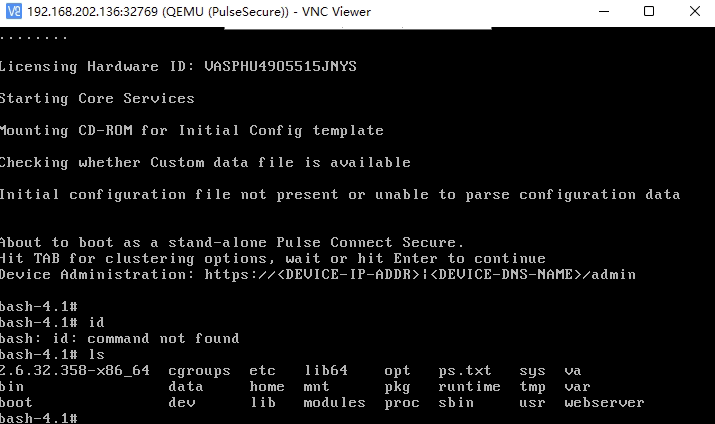
🌰贰
启动后是沙盒shell:
 先试试挂载磁盘,它由两块磁盘,一块大小80G实际只使用了几M猜测为数据/日志盘,先分析另一块,使用fdisk可见有两个分区:
先试试挂载磁盘,它由两块磁盘,一块大小80G实际只使用了几M猜测为数据/日志盘,先分析另一块,使用fdisk可见有两个分区:
root@bm:/tmp/# fdisk -l /dev/sdb
Disk /dev/sdb: 2 GiB, 2147483648 bytes, 4194304 sectors
Disk model: VMware Virtual S
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x00000000
Device Boot Start End Sectors Size Id Type
/dev/sdb1 * 2048 526335 524288 256M 83 Linux
/dev/sdb2 526336 4194303 3667968 1.8G 83 Linux
将它们都挂在出来,查看sdb1的内容:
root@bm:/tmp/sdb1# ls -lah
total 63M
drwxr-xr-x 9 root root 4.0K Jul 23 07:13 .
drwxrwxrwt 14 root root 4.0K Jul 27 01:10 ..
drwxr-xr-x 2 root root 4.0K Jul 14 22:10 bin
-rw-r--r-- 1 root root 1 Jul 14 22:10 boot.msg
drwxr-xr-x 2 root root 4.0K Jul 14 22:10 cmdb
drwxr-xr-x 2 root root 4.0K Jul 26 09:02 config
-rw-r--r-- 1 root root 0 Jul 23 11:14 dhcp6s_db.bak
-rw-r--r-- 1 root root 0 Jul 23 11:14 dhcpddb.bak
-rw-r--r-- 1 root root 0 Jul 23 11:14 dhcp_ipmac.dat.bak
drwxr-xr-x 14 root root 4.0K Jul 26 16:58 etc
-rw-r--r-- 1 root root 169 Jul 23 11:14 extlinux.conf
-rw-r--r-- 1 root root 53 Jul 14 22:10 filechecksum
-rw-r--r-- 1 root root 4.0M Jul 14 22:10 flatkc
-rw-r--r-- 1 root root 256 Jul 14 22:10 flatkc.chk
-r--r--r-- 1 root root 120K Jul 14 22:10 ldlinux.c32
-r--r--r-- 1 root root 68K Jul 14 22:10 ldlinux.sys
drwxr-xr-x 2 root root 4.0K Jul 23 11:14 lib
drwx------ 2 root root 4.0K Jul 23 11:14 log
drwx------ 2 root root 16K Jul 14 22:10 lost+found
-rw-r--r-- 1 root root 58M Jul 14 22:10 rootfs.gz
-rw-r--r-- 1 root root 256 Jul 14 22:10 rootfs.gz.chk
带.chk的是对应文件的校验和,看大小是256字节,共1024位没看出是什么算法生成的:
root@bm:/tmp/sdb1# ls -lah flatkc.chk
-rw-r--r-- 1 root root 256 Jul 14 22:10 flatkc.chk
ldlinux是syslinux loader的内容:
root@bm:/tmp/sdb1# file ldlinux.sys
ldlinux.sys: SYSLINUX loader (version 6.04)
root@bm:/tmp/sdb1# file ldlinux.c32
ldlinux.c32: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked, stripped
root@bm:/tmp/sdb1# cat extlinux.conf
DISPLAY boot.msg
TIMEOUT 10
TOTALTIMEOUT 9000
DEFAULT flatkc ro panic=5 endbase=0xA0000 console=ttyS0,9600 root=/dev/ram0 ramdisk_size=65536 initrd=/rootfs.gz maxcpus=1
flatkt是kernel:
root@bm:/tmp/sdb1# file flatkc
flatkc: Linux kernel x86 boot executable bzImage, version 3.2.16 (root@build) #2 SMP Wed Jul 14 21:06:17 UTC 2021, RO-rootFS, swap_dev 0x3, Normal VGA
然后另起一台linux挂在磁盘,两个分区,看了看核心应该在rootfs里面,解压后发现没啥线索,只能继续接呀它里面的压缩包。这里面的压缩包无法直接解压鬼知道是不是做了什么修改,那就用它自带的工具解压吧,执行chroot . sbin/xz -d bin.tar.xz
然后打开康康,嚯,很多命令都指向了一个55M的init程序,除此啥都木有呜呜呜,先自己编个busybox,嗯整静态链接的,细节不多讲:
cp -P * /tmp/rootfs/sbin
对initrd进行重打包的脚本:
MOUNT_DIR1=/tmp/fortigate-vm-sdb1
#MOUNT_DIR2=/tmp/fortigate-vm-sdb2
ROOTFS_DIR=/tmp/rootfs
ROOTFS_FILE="$MOUNT_DIR1"/rootfs.gz
FILECKSUM_FILE="$MOUNT_DIR1"/filechecksum
unpack(){
if [ ! -d "$MOUNT_DIR1" ]; then
mkdir "$MOUNT_DIR1"
fi
#if [ ! -d "$MOUNT_DIR2" ]; then
# mkdir "$MOUNT_DIR2"
#fi
if ! (mount | grep "$MOUNT_DIR1" > /dev/null);then
mount /dev/sdb1 "$MOUNT_DIR1"
fi
rm -rf "$ROOTFS_DIR"
mkdir "$ROOTFS_DIR"
cd "$ROOTFS_DIR" || exit
gzip -cd "$ROOTFS_FILE" | cpio -imd --quiet
chroot . sbin/xz -d bin.tar.xz
chroot . sbin/ftar -xf bin.tar
return 0
}
pack(){
cd "$ROOTFS_DIR" || exit
chroot . sbin/ftar -cf bin.tar bin/
chroot . sbin/xz -z bin.tar
rm "$ROOTFS_DIR"/bin/*
find . | cpio --quiet -H newc -o | gzip -9 -n > "$ROOTFS_FILE"
crc32=$(gzip -1 -c <"$ROOTFS_FILE" | tail -c8 | hexdump -n4 -e '"%x"')
echo -e "/rootfs.gz,CRC32,0x${crc32}\n/flatkc,CRC32,0xffffffff" > "$FILECKSUM_FILE"
}
option="$1"
case "$option" in
pack) pack ;;
unpack) unpack ;;
*) echo "$0 pack|unpack" && exit 1 ;;
esac
重打包发现启动不了,经分析存在签名校验,因此直接把它pass掉:
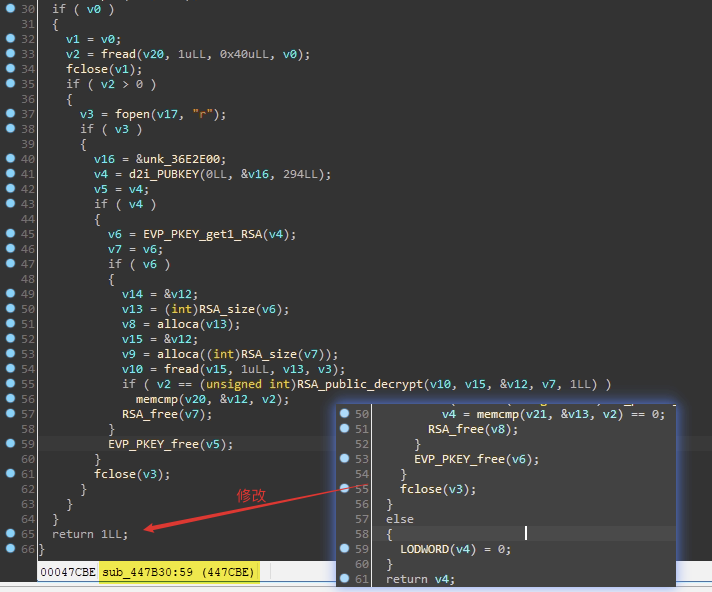 首先找一个点去打补丁,找了会儿感觉这个关机的点不错,通过这个字符串定位到函数:
首先找一个点去打补丁,找了会儿感觉这个关机的点不错,通过这个字符串定位到函数:
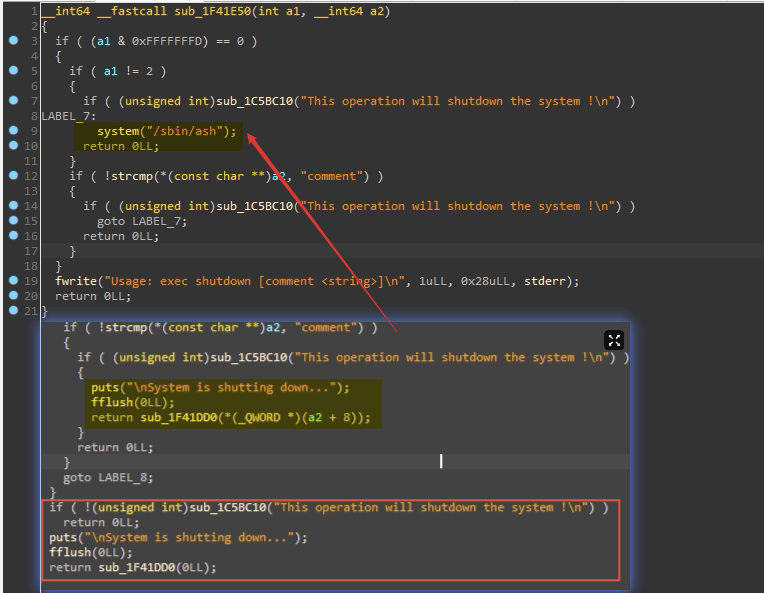
 把原来的输出改为执行busybox的sh,并去掉关机操作:
把原来的输出改为执行busybox的sh,并去掉关机操作:
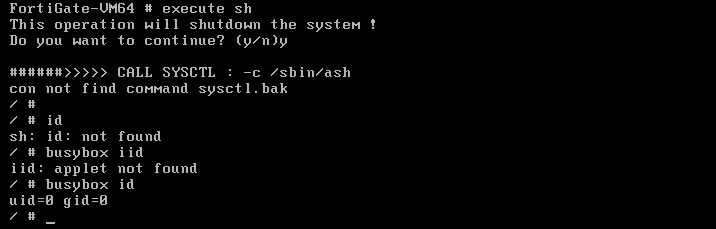
 插电!开机!执行失败:
插电!开机!执行失败:
 根据这个字符串发现是sysctl文件,这就很奇怪咯,沉着分析,冷静思索,不管了直接把它替换了,应该影响不大!插电!开机!成功获取shell:
根据这个字符串发现是sysctl文件,这就很奇怪咯,沉着分析,冷静思索,不管了直接把它替换了,应该影响不大!插电!开机!成功获取shell:
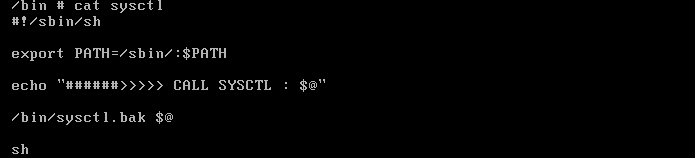
授权破解
这里选两个典型的例子进行演示:
🌰壹
这个例子不需要写注册机,某设备试用版授权无法正常使用某功能,为了分析该功能只能破授权,通过分析里面的二进制文件发现和授权有关的部分出现了很多flexlm,还有很多lm相关的文件,搜索发现它用的是某三方授权方案:

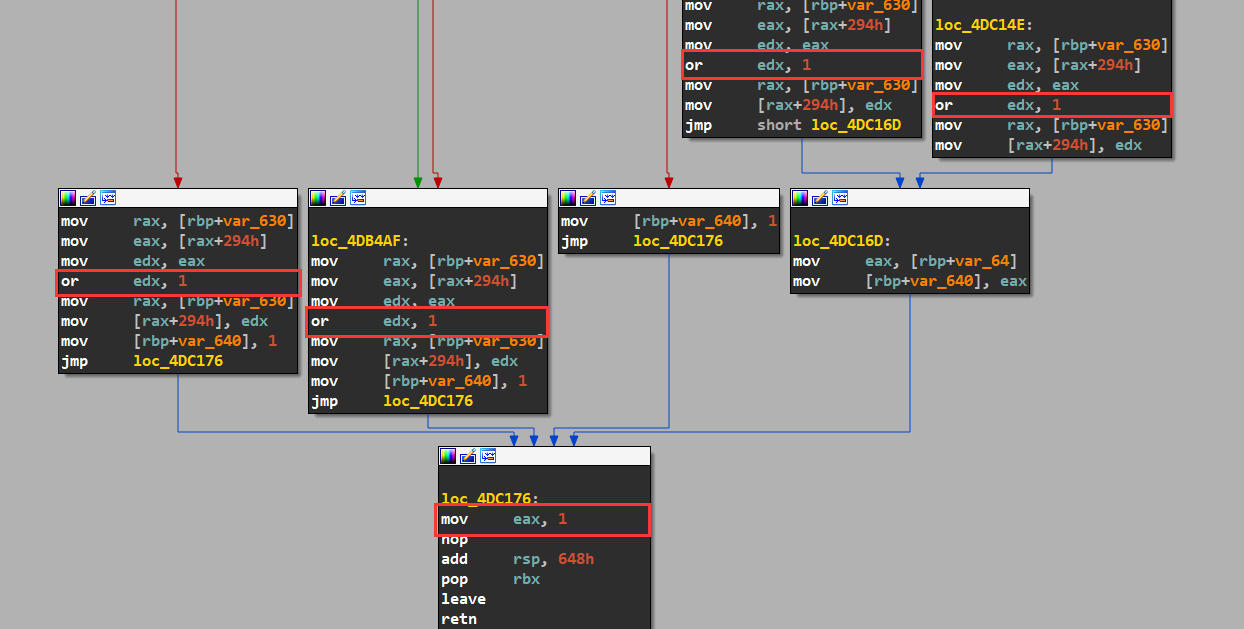
 再搜索发现该方案已经被分析很深了(神奇的是一家做授权的公司在早起产品中竟然没用公钥机制,导致可以不打补丁直接写注册机),那么此处就不必再深入研究它的实现细节了,根据yangmyron的分析,先找到它的damon文件,直接给它来个补丁,使用SIGN%s=进行字符串搜索定位到关键函数,将其返回值改为1,以及最后的或改为1::
再搜索发现该方案已经被分析很深了(神奇的是一家做授权的公司在早起产品中竟然没用公钥机制,导致可以不打补丁直接写注册机),那么此处就不必再深入研究它的实现细节了,根据yangmyron的分析,先找到它的damon文件,直接给它来个补丁,使用SIGN%s=进行字符串搜索定位到关键函数,将其返回值改为1,以及最后的或改为1::
 再看nslicense里解析为具体的feature,根据它的需要编lic文件内容,如
再看nslicense里解析为具体的feature,根据它的需要编lic文件内容,如
SERVER this_host fa163ec85d89
VENDOR CITRIX
USE_SERVER
INCREMENT CNS_SEE_SERVER CITRIX 2021.0602 permanent 1 \
VENDOR_STRING=;LT=Retail;GP=720;CL=SSE;SA=1;ODP=0 \
ISSUED=10-jan-2021 NOTICE="sangfor...." \
SN=LA-0123456789-25002:FID__788fcbbf_c5858b8918f_6dfe \
START=14-jan-2016 SIGN="0514 8058 0055 3CB8 7F18 70D1 A5CF \
CBD5 9A05 352C 15AE F733 F297 5144 7C57 137B 41EF 7101 C134 \
B7C5 3989 99D5 0499 26D2 EF7C 55E8 FE25 5555 01CF E346"
...
由于根文件系统为内存文件系统,重启后改动失效,因此将修改后的文件放入/var目录,并在每次启动时做替换,将/etc/rc.conf文件复制到/nsconfig目录下,在它里面写CITRIX替换指令:
rm -rf /netscaler/CITRIX
cp /var/CITRIX /netscaler
chmod a+x /netscaler/CITRIX
插电!开机!轻轻松松:
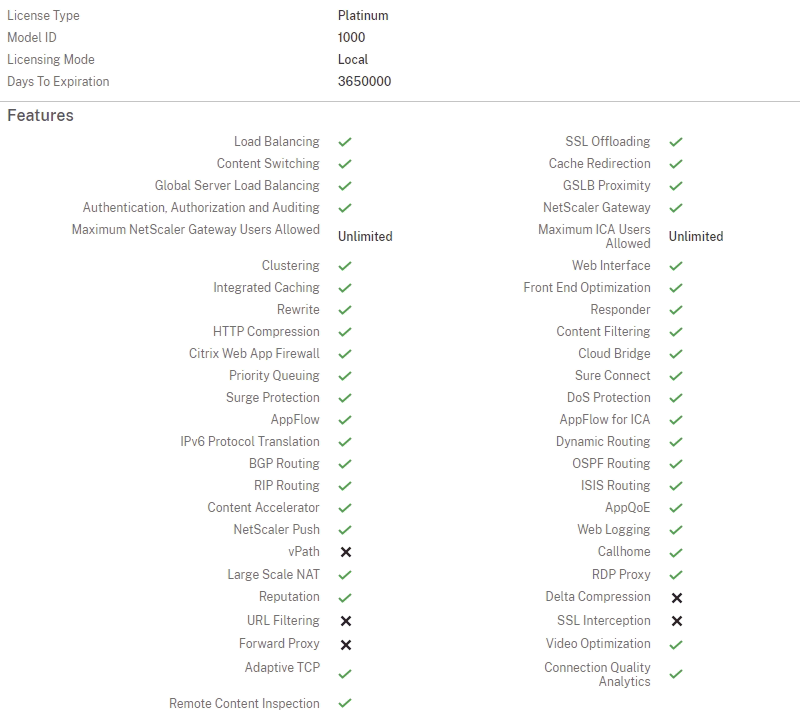
🌰贰
这是一个写注册机的例子,同样某设备试用版授权无法正常使用某功能,于是只能破授权了,IDA打开,搜license字符串,找到一个可疑点:

点进去分析,在sub_22D47E0函数里,看到它首先读取了vm.lic文件,之后对一个0xA8大小的结构体qword_D2C2C00进行了初始化,之后sub_22D7460做的事应该是解析文件内容并将解析后的内容置于qword_D2C2C00里:
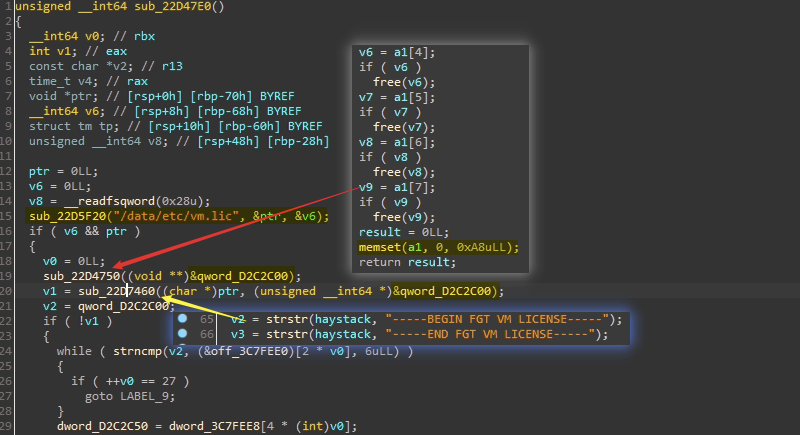 进一步分析sub_22D7460,由于直接用了openssl库,所以逻辑很容易分析,首先获取证书部分并base64解码:
进一步分析sub_22D7460,由于直接用了openssl库,所以逻辑很容易分析,首先获取证书部分并base64解码:
 之后使用RSA解密头部,获取AES密钥:
之后使用RSA解密头部,获取AES密钥:
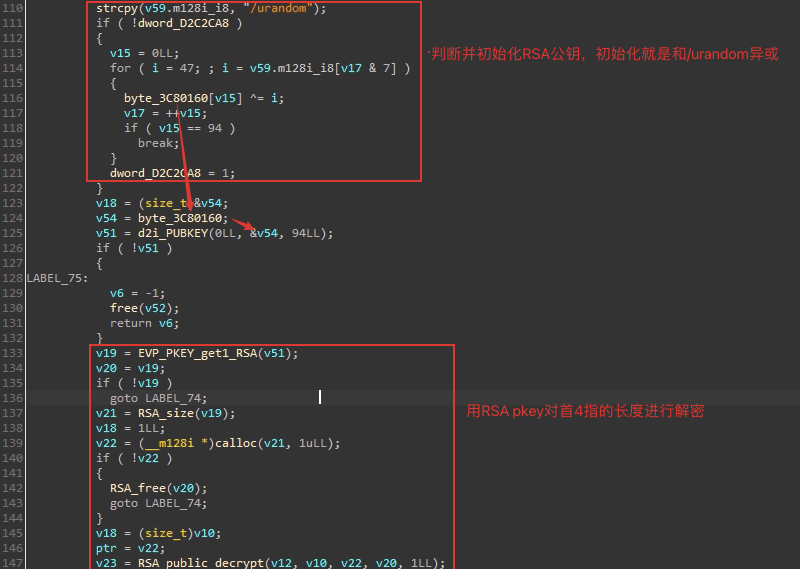 如果RSA解密失败,它会直接将头部作为AES密钥,之后会使用此密钥解密后续数据:
如果RSA解密失败,它会直接将头部作为AES密钥,之后会使用此密钥解密后续数据:
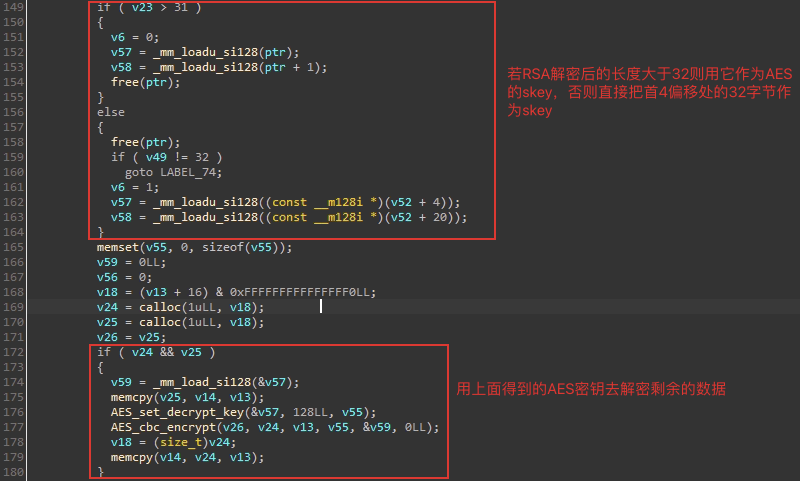 解密后,循环解析并设置结构体:
解密后,循环解析并设置结构体:
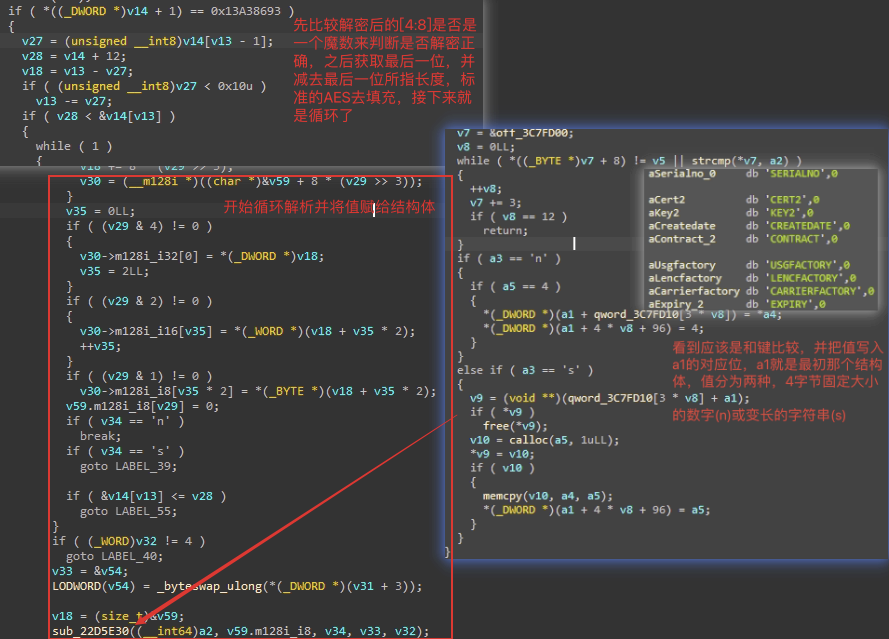 这样就能分析出结构体如下:
这样就能分析出结构体如下:
struct lic{ // 0xa8
void* SERIALNO; // 0x00 FGVMEV
void* CERT; // 0x08
void* KEY; // 0x10
void* CERT2; // 0x18
void* KEY2; // 0x20
void* CREATEDATE; // 0x28 "%a %b %e %H:%M:%S %Y"
void* UUID; // 0x30
void* CONTRACT; // 0x38
int USGFACTORY; // 0x40
int LENCFACTORY; // 0x44
int CARRIERFACTORY; // 0x48
int EXPIRY; // 0x4c
int Model; // 0x50
char pad1[0x04]; // 0x54
__int64 createtime; // 0x58
int sSERIALNO; // 0x60
int sCERT;
int sKEY;
int sCERT2;
int sKEY2;
int sCREATEDATE;
int sUUID;
int sCONTRACT;
int sUSGFACTORY;
int sLENCFACTORY;
int sCARRIERFACTORY;
int sEXPIRY;
char pad2[0x10]; // 0x90
__int8 valid; // 0xa0
char pad3[0x07]; // 0xa8
}
把结构体分析完之后就可以很好的进行交叉引用来获取所有对证书的使用点,并分析系统是怎么使用这些域的,这样就能知道怎么为这些域赋值,之后又是一通分析,不细述,只有一个点需要注意,它的代码有点奇怪导致ida无法正确识别函数:
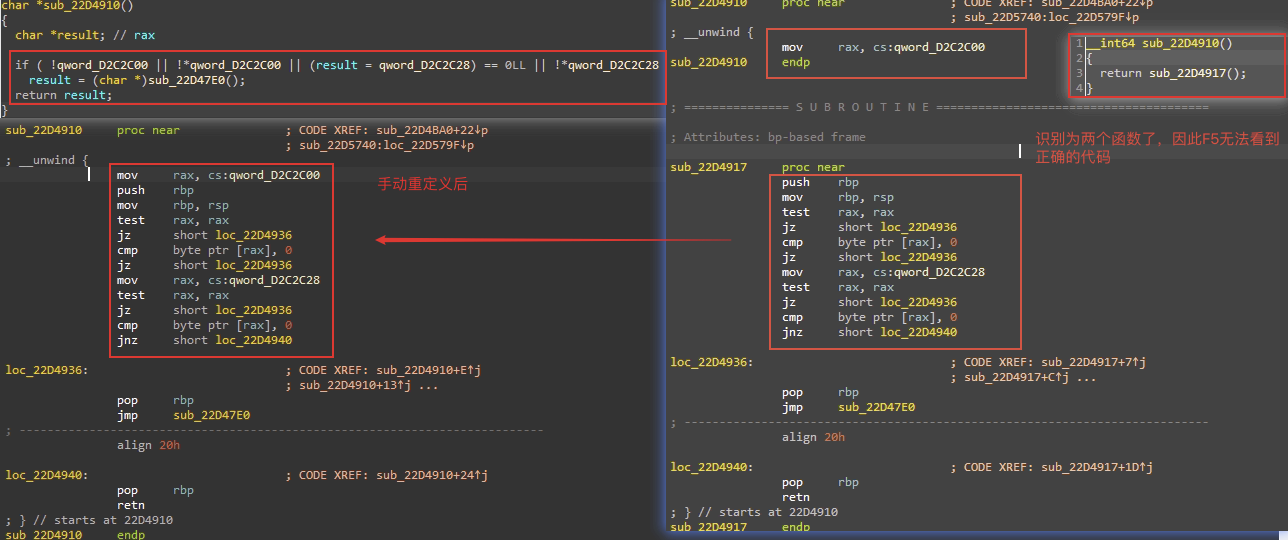 最终根据上述过程,可写出如下代码:
最终根据上述过程,可写出如下代码:
import base64
import struct
def serialize(dic: dict):
buf = b''
def serialize_key(s: str):
s = s.encode() + b'\0'
return struct.pack('<B', len(s)) + s
def serialize_val(obj):
if isinstance(obj, int):
return b'n' + struct.pack('<HI', 4, obj)
elif isinstance(obj, str):
obj = obj.encode() + b'\0'
return b's' + struct.pack('<H', len(obj)) + obj
else:
raise Exception('???')
for key, val in dic.items():
buf += serialize_key(key)
buf += serialize_val(val)
return buf
AES_BLOCK = 16
MAGIC = 0x13A38693
LINE_SIZE = 64
AES_KEY = b'\0' * 32
def gen_lic():
lic_str = {
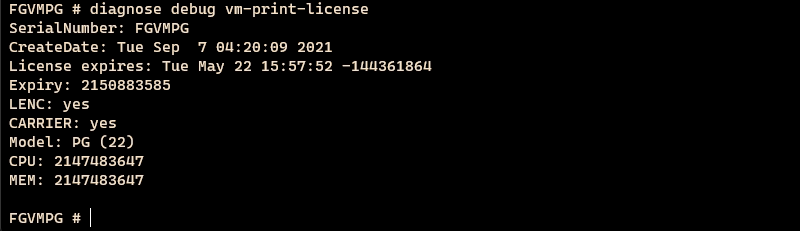
"SERIALNO": "FGVMPG",
# "CERT": "",
# "KEY": "",
# "CERT2": "",
# "KEY2": "",
"CREATEDATE": "1631013609", # 20210907 Sun Jan 1 17:21:54 2021
# "UUID": "", # 32字节,可以没有
# "CONTRACT": "",
"USGFACTORY": 16,
"LENCFACTORY": 16,
"CARRIERFACTORY": 16,
"EXPIRY": 60 * 60 * 24 * 365, # 一年
}
buf = serialize(lic_str)
buf = struct.pack('<III', 0, MAGIC, 0) + buf
pad_chr = AES_BLOCK - (len(buf) % AES_BLOCK)
buf += bytes(chr(pad_chr) * pad_chr, 'latin1')
# 若未打补丁,需要对buf进行aes加密aes.enc(key=AES_KEY,iv=AES_KEY[:16],buf)
lic = struct.pack('<I', len(AES_KEY)) + AES_KEY + struct.pack('<I', len(buf)) + buf
header = b'-----BEGIN FGT VM LICENSE-----'
foot = b'-----END FGT VM LICENSE-----'
data = base64.b64encode(lic)
lines = [header, ]
for i in range(0, len(data), LINE_SIZE):
lines.append(data[i:i + LINE_SIZE])
lines.append(foot)
content = b'\r\n'.join(lines)
with open('Fortigate.lic', 'wb') as f:
f.write(content)
if __name__ == '__main__':
gen_lic()
从上面分析,甚至不用打补丁就能写KeyGen,不过python Crypto AES和Openssl那种调法似乎不兼容,所以还是直接打个补丁吧!
 然后,破解成功!
然后,破解成功!