慢慢完善,其实内部产品和外部的有很多相似处,外部缺乏资料和源码更复杂一点,所以本文主要以外部产品为目标,内部过程如下,详细的见下文:

一、分析环境搭建
获取固件
这里的固件指磁盘镜像,一般设备就是一个linux系统,我们需要先将它的磁盘镜像一遍并使用模拟环境重新运行它,这样一方面方便分析,另一方面防止破坏原始设备,通常可通过如下方式获取设备或镜像:
- 若是内部代码审计的话,当然是开发直接提供镜像咯!否则看下面
- 设备供应商官网提供虚拟机或固件下载,如Cisco(Sinfor以前以前也提供后来被打了就下架了)
- 论坛、网盘等提供虚拟机或固件下载,如emulatedlab也提供各类镜像下载
- 购入设备,从咸鱼等二手市场上购入二手设备要便宜些
- 租借设备
对于后两种方式,获取的是硬件设备(如服务器或小硬件盒子),因此需要额外的步骤提取固件:
- 如果可以操作系统命令行(SSH、串口、调试口等),可通过 dd 命令拷贝磁盘。如果设备的磁盘太大而已使用空间很小,则可以使用tar命令去仅拷贝存在的文件,但是这种方式需要很细致,不要破坏文件的属性,也不要漏过一些特殊文件,否则可能出现不好排查的问题。
- 可拆机物理设备,拆取存储介质然后挂载磁盘
- 不可拆机物理设备,黑盒挖掘RCE漏洞获取操作系统命令行权限,再通过 dd 命令拷贝磁盘,此时一般有管理员权限,因此能挖掘所有的接口,一般系统设置(如网络设置),导入导出操作等容易出现问题,优先挖这些接口
- 如果不能拆又挖不到洞可咋整?做安全的思想不能僵化要敢于打破规则,嗯意思就是悄悄地拆,此时需要对抗的就是易碎贴了,什么热风枪吹风机,或者淘宝仿制易碎贴啥的,开动自己的小
奶脑瓜。
⚠️ 使用事项(以下两条是用钱换来的):
收到设备录好开箱视频,收好所有零件和包装,返还设备同
谨慎的对设备做写操作,尽量在内存文件系统上操作,谨慎的将dd命令的目标指定为设备的磁盘
运行固件
提取出固件后,为便于调试,添加硬件以及防止损坏设备,一般会使用虚拟机来运行固件,一般情况下可使用vmware workstation,virtualbox,parallels desktop等,它们的优点是使用方便速度快,但是不支持模拟其他架构,支持硬件较少,可配置性较弱,另外还有写使用类虚拟化导致启动失败,因此使用这些虚拟机无法成功运行固件时,一般会使用qemu。另外将提取出来的固件使用qemu来模拟运行,有时需要使用提取出来的文件重新制作文件系统,编译满足此系统运行的内核等。
注:在启动出错时,可考虑是否配置的硬件不足,如CPU/内存/磁盘空间不满足需求...
Qemu
由于主要用qemu,此处简单记录几点Qemu常见的使用技巧:
1.调试:一般直接使用-s和-S进行调试,前者是-gdb tcp::1234参数的别名,表示启动gdb stub监听1234端口,后者表示在CPU重置后即暂停,暂停在第一条指令处,可用于调试BIOS或BootLoader等。调试BootLoader一般在开始时在0x7c00处设置断点,在一般情况下BIOS将BootLoader加载到0x7c00开始的内存处然后跳转,并且一般情况下为16位程序,需要在gdb中设置set architecture i8086,之后若CPU切换了模式gdb未正确识别,可再次attach。
注:若gdb无法下断,可能是因为使用了硬件加速,去掉即可。
2.监控虚拟机:使用monitor进行客户机监控,如使用-monitor telnet::9000,server能在9000端口启动monitor,这会使qemu在启动时暂停,使用nc连接后客户机可继续执行,而nc终端可执行各种监视任务。也可以使用-vnc :60 -monitor stdio在当前交互启动monitor,使用vnc连接5960端口获取虚拟机的屏幕。
注:vnc这里指定的:60不是指端口,而是vnc的编号,如这里实际监听的端口要加5900...
3.dump虚拟机内存:使用monitor可直接操作geust,如dump内存可使用dump-guest-memory mem.dump。
4.加速:很多镜像必须使用加速运行才不会失败,一般来说都是使用kvm加速,它是Linux下的一个内核模块,有amd和intel的实现,它需要CPU支持虚拟化并在BIOS里将其开启,若linux安装在vmware等虚拟机内,需要在VMM里将其打开,如vmware如下:
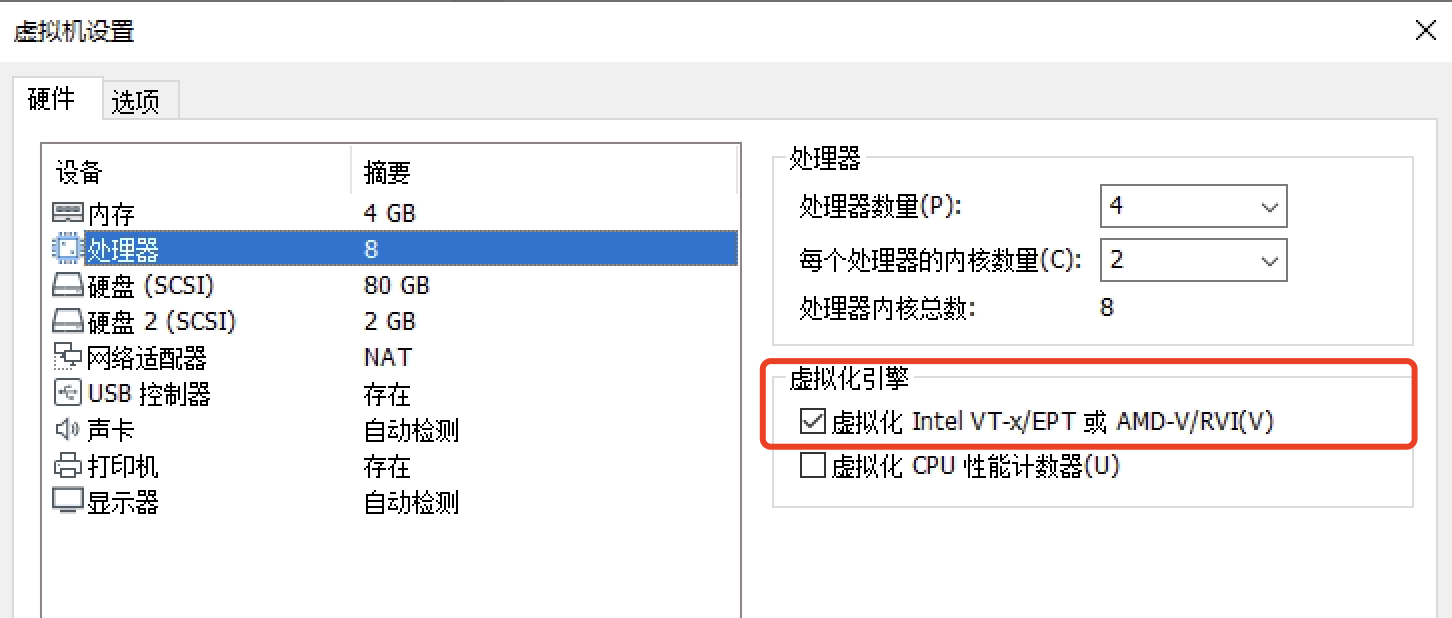 开启后进入Linux,使用
开启后进入Linux,使用lsmod查看系统是否已加载kvm,如下已加载amd版:
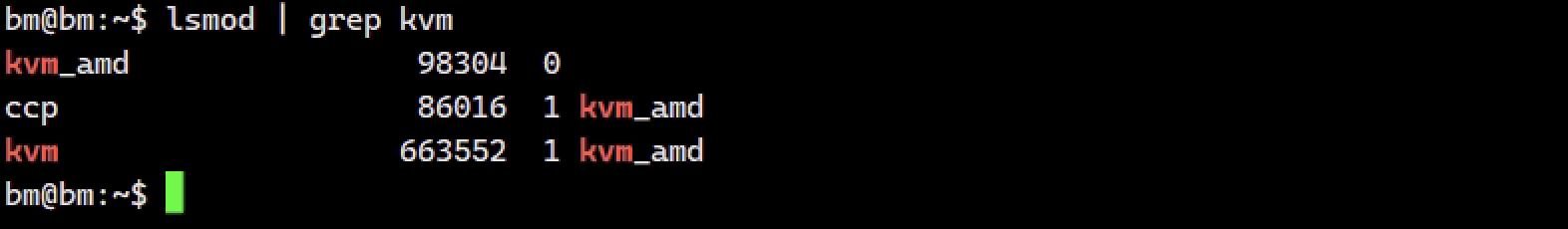 若未加载可尝试使用
若未加载可尝试使用modprobe加载,若出错可能在编译kernel时未编译该模块,需要重新编译。而想要在windows上直接加速,且为intel处理器,可尝试使用haxm驱动,强调下它的git仓库release了多个文件,别下错了。
5.网络:
a.user模式 user模式最简单,由于实际环境下vpn只会开放443端口,因此我们只需要将443端口映射出来,另外为了管理方便还映射了22与8080端口,需要注意qemu的user模式跨网段ping会失效,不应使用它验证网络连通性,它的默认网关是10.0.2.2,一般把它本身配置为10.0.2.15,如:
qemu-system-i386 -nographic -drive format=raw,file=tos -m 8G -smp cpus=2,cores=2 -accel hax \
-netdev user,id=n0,hostfwd=::10022-:22,hostfwd=::10443-:443,hostfwd=::18080-:8080,hostfwd=::13946-:13946 \
-device e1000e,netdev=n0
-nic user
b.tap模式 tap模式使用网桥,windows下的操作步骤如下:
1.下载openvpn,安装后会出现新的tap网卡,将其重命名为eth0
2.修改配置如下:
qemu-system-i386 -nographic -drive format=raw,file=tos -m 8G -smp cpus=2,cores=2 -accel hax \
-netdev tap,id=n0,ifname=eth0 \
-device e1000e,netdev=n0
3.同时选中上网网卡与tap网卡,右键桥接,之后即可在内部使用上网网卡的配置了,可参考1和2。至于linux,它自带tap/tun,直接创建就好了,如:
#!/bin/bash
IFACE='ens33' # 物理接口名
IP='192.168.202.133/24' # 物理接口原地址
TAP='tap0' # 新建的tap接口名,可不变
BR='br0' # 新建的虚拟网桥名,可不变
ip link add ${BR} type bridge # 新建虚拟网桥
ip link set ${IFACE} master ${BR} # 将物理接口桥接到网桥上
ip tuntap add ${TAP} mode tap # 新建tap设备
ip link set ${TAP} up # 启动tap设备
sleep 0.5
ip link set ${TAP} master ${BR} # 将tap设备桥接到网桥上
ip addr del ${IP} dev ${IFACE} # 删除原接口的IP地址
# 也可直接 ip addr flush ${IFACE} 删除所有IP
ip addr add ${IP} dev ${BR} # 将原接口的IP地址给网桥的隐藏接口
ip link set ${BR} up # 开启网桥
EVENG
它其实也是用的Qemu,只是有的时候比较方便,使用方式如下:
- 首先从镜像论坛下载虚拟机镜像
- 从官网下载社区版并导入vmware,再添加一张网卡
- 初始化过程中配好IP与账户,默认console账户为
root/eve,webui账户为admin/eve之后访问ssh,将下载的镜像解压后连同文件夹上传到/opt/unetlab/addons/qemu,如此处将pcs解压:
root@eve-ng:/opt/unetlab/addons/qemu# tree
.
`-- pulse-PCS-v-9.1r8.0-b7453-VT
`-- virtioa.qcow2
1 directory, 1 file
- 再使用ifconfig与brctl查看网卡可见有9个网桥与两张网卡,其中网卡会与网桥一一对应:
root@eve-ng:/opt/unetlab/addons/qemu# brctl show
bridge name bridge id STP enabled interfaces
pnet0 8000.000c2908f770 no eth0
pnet1 8000.000c2908f77a no eth1
pnet2 8000.000000000000 no
pnet3 8000.000000000000 no
pnet4 8000.000000000000 no
pnet5 8000.000000000000 no
pnet6 8000.000000000000 no
pnet7 8000.000000000000 no
pnet8 8000.000000000000 no
pnet9 8000.000000000000 no
- 访问webui,新建实验,在空白处右键新建node,会发现pulse secure已经可识别,选中并添加:
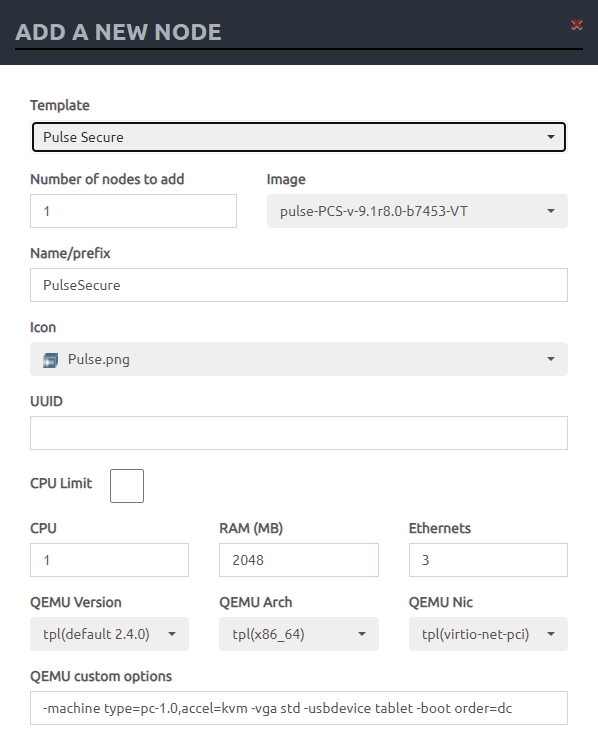
- 同样右键新建network,选择cload1,即pnet1网络,接着光标指向新建的ps,在关机时它会有一个🔌标志,将其连到cload,它会出现三张网卡选中internal后开机如下:
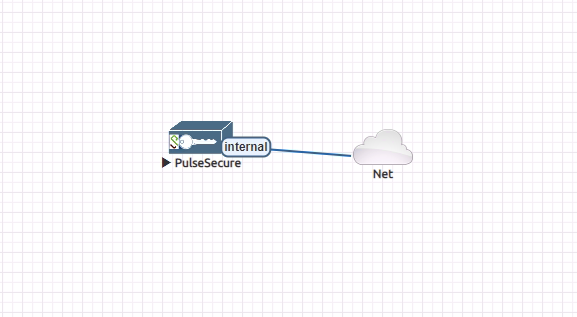
- 此时光标移至ps在左下角可见其vnc连接地址,使用vnc客户端连接,可对其进行配置,由于之前的步骤已将虚拟机新加的网卡与ps的第一张网卡桥接了,因此配上同网段的IP即可通讯,如新加网卡网段为192.168.202.0/24,则在ps初始化时配置该网段未使用IP即可,配置完后进入如下界面:
其他工具
在挖掘网络设备时一般使用QEMU的系统级仿真,因为这些设备环境比较复杂,像嵌入式设备可使用emux,firmadyne,qiling去做,以后遇到再说...
沙盒破解
此处的沙盒和系统安全里的那个隔离沙盒不太一样,一般设备不会为用户提供全功能的shell(如bash),相反它们只会提供一个功能有限的shell,我们把它叫做沙盒,拥有设备最高权限的管理员也只能执行它所允许的操作,对设备进行各种运维配置(如配置网络,修改用户信息,修改策略等),如下图为某设备的沙盒shell:
 这些功能一般不能满足设备分析的需求,如无法使用ps,netstat等命令,无法任意传输文件或进行dbg,因此首先需要破解该沙盒,从而获取一个功能较完整的shell(越狱),在破解前需要先了解下设备是怎么实现这种功能的。首先把它的磁盘挂载到自己的系统(如Ubuntu),看看它的分区,此时几种情况:
这些功能一般不能满足设备分析的需求,如无法使用ps,netstat等命令,无法任意传输文件或进行dbg,因此首先需要破解该沙盒,从而获取一个功能较完整的shell(越狱),在破解前需要先了解下设备是怎么实现这种功能的。首先把它的磁盘挂载到自己的系统(如Ubuntu),看看它的分区,此时几种情况:
- 可以看到所有分区:分区是正常的分区,里面的文件就不一定是正常的文件了,仔细分析它的文件。
- 只能看到部分分区:分区没文件系统或分区被加密了,需要进一步分析。
一般会遇到从Bootloader开始,各过程做定制化,做加密,所以需要先破解这些障碍,这里有个前提,系统能正常工作,不管它做了什么保护只要系统能正常工作它就必须代码里实现这些操作,此时一般有两条路: 1.老实人之正向分析:熟悉启动过程跟着分析就好了,这个过程单独写了《Linux启动过程之XXX》可以参考下。
2.小聪明之找各种小技巧:就是找各种关键点,此时binwalk将是你的好盆友,通过binwalk一般都能获取很多重要信息,再通过直接改文件,内存取证,直接改内存等方式获取shell。
其实能够调试就可以直接获取shell,想想调试时可以直接修改内存当然能执行任意代码了,之前想偏了认为上帝视角获取的是客户机的物理内存,需要手动找页表做反向映射,后来看这篇文章才想通其实上帝视角的调试器能够也实际获取的是逻辑地址,因为在中断时可以获取虚拟机的所有寄存器,于是通过段寄存器(平坦模型也不需要)与CR3即可获取到当前正在运行的任务/例程的逻辑地址空间,当知道调试器当前获取的是当前被中断的任务的空间,当然可以为所欲为而不必担心地址转换或修改其他任务的内存,不过还有个问题是上帝视角的调试器对内存的修改不会触发OS的写时复制机制,而Linux下fork机制会共享很多数据,此时若直接修改共享内存页将影响到整个系统范围,因此若要修改数据最好修改任务私有的内存,这包括运行过一段时间(已经发生过CoW)的数据区,栈区,堆区,而指令一般不必修改,寄存器可以任意修改。还有个问题是被中断的进程最好是用户态的,尽管内核态也可以调用系统调用,但内核态出现问题会直接使崩溃,判断的方法时看PC的值,高地址就是在内核态。
注意不要看到不是标准shell就觉得要越狱,有些设备直接提供了命令可以进入到系统的shell。
搭建调试环境
当固件能成功运行并获取到root shell时,首先需要关注它的运行时环境:
- 基于什么系统与发行版:unix(freebsd, netbsd等),linux(ubuntu, centos, suse等),这将直接决定后续调试的复杂度。
- 内核版本号:低版本容易存在已知漏洞(如提权),且默认支持的缓解措施较少(如aslr),但是由于ABI兼容性问题编译软件较麻烦,高版本恰好相反。
- 是否自定义内核,内核模块是否静态编译进内核:若内核被修改过,如分析程序发现一些不存在于标准里的系统调用,发现一些奇怪的内核模块,则内核被定制过,这部分可能需要分析,另外将该固件里的程序提取到其他同(高)版本的内核里可能无法正常运行。
- 文件系统与分区挂载:观察磁盘有哪些分区,已挂载和未挂载的文件系统,是否使用了特殊文件系统,如rootfs是否是内存文件系统,是否使用了sysfs,procfs,tmpfs,cgroup,udev等,它们各自会提供特殊的功能。
调试时,需要充分利用系统与应用提供的各种机制:
- 使用ps, netstat等工具查看进程信息,充分利用/proc等目录的信息。
- 使用strace, ltrace,tcpdump等动态追踪或抓包工具可整体了解程序运行机制,从而快速定位到关键点。
- 研究程序的日志机制,调试日志可能通过编译预处理去除,也可能编译在程序中,通过特定配置,指定参数,指定信号激活,详细的调试日志方便分析程序流程。
- 选择合适的调试器,如ida的调试器,gdb与合适的插件,frida动态插桩等。
一般来说ida调试服务端适合与ida反编译工具配合使用,但是它依赖高版本的libc,libc++库,因此在旧内和尚一般需要先编译高版本的libc。gdb适用范围更广,包括非x86架构,非linux系统,一般是自己编译上带python扩展的版本再配合一些插件(gef,peda,pwndbg)使用。frida可作为strace的增强,能快速的对任意函数hook,但环境要求更多。 一般情况下,设备的环境里只会存在设备运行所必需的工具,因此很多分析所需工具(如nc, gdb, libc)需要自己安装。
- 当设备环境是发行版(如ubuntu 16.04)时,可尝试直接配置软件源进行软件安装,当发行版太旧已停止维护也可尝试查找archive源。
- 当设备环境是裸核或不存在包管理工具时,需要安装一台基于(或低于)该内核版本的发行版系统,在该系统上编译所需的软件并上传到设备环境里,这里最好使用静态编译(-static, --enable-static, --disable-dynamic),否则依赖的动态库(可用ldd查看)也需要被上传,为防止冲突可使用LD_LIBRARY_PATH环境变量指定库路径。
关于如何构建交叉编译工具链,我移到了单独的文章,鸡鸡找找吧!
授权破解
破解授权不是我们的目的,我们不是为了销售盗版而是为了挖掘它的安全漏洞,因此破解是不得已而为之的事,在设备运行后,我们需要首先尝试使用我们感兴趣的功能,如它的VPN功能是否能正常使用,若只有数量限制速率限制等,或者能够试用一段时间,那么就可以跳过这一步。但是有时一些设备的特定或全部功能是需要购买授权才能使用的,此时为了漏洞挖掘覆盖的全面性,我们必须要破解它授权;
- 分析授权逻辑,尝试直接打补丁(爆破)绕过授权验证。这种方式优点是简单粗暴,缺点是若未找到最佳的补丁点可能导致未完全破解进而程序功能异常。
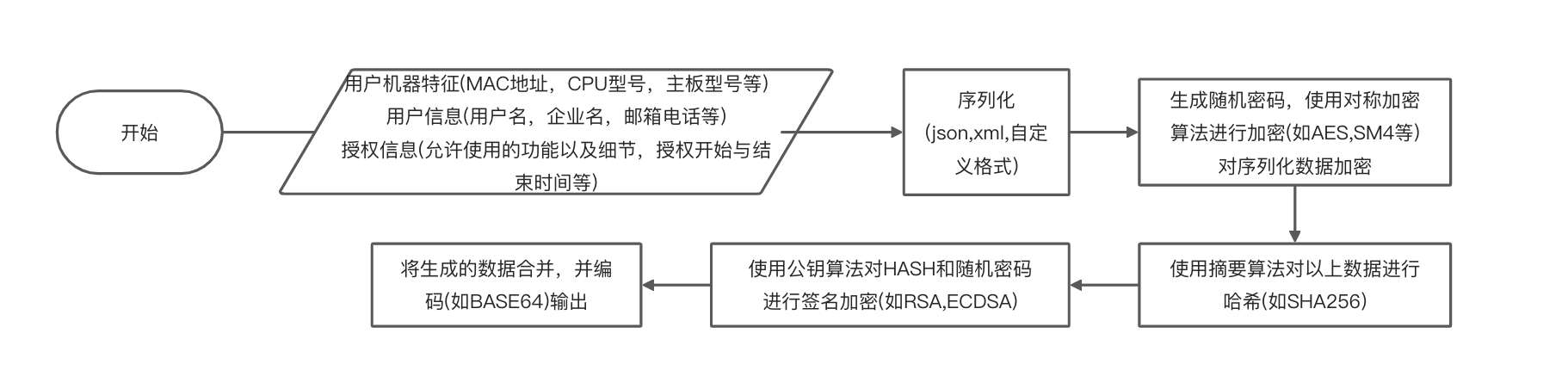
- 逆向授权程序,伪造授权文件破解授权。通过分析授权逻辑编写注册机是最好的方式,若程序未正确使用公钥密码,可实现不打补丁直接生成合法的证书,否则一般是替换程序的公钥为自己生成的,或直接打补丁跳过公钥签名验证环节,然后自己生成符合格式的证书并自签名。这里若存在合法的证书则可以轻易伪造证书,否则需要仔细分析证书验证环节逆向出合法的证书格式。 授权函有多种形式,如单注册码或带授权信息的证书,以后者为例,一个典型的证书生成过程如下:
代码保护破解
有些厂商会对脚本语言写的代码做一些保护,这就要具体问题具体分析了,因为这不是重点因此不要过多分析:
- 有破解方法:如PHP使用了ioncube这些,有工具的上工具,没工具的给钱让别人破。
- 没破解方法:评估下有没有必要咯,首先肯定下保护越多别人挖的概率越小,因此有漏洞的可能越大,只是要评估投入产出比。没破解方法,如果是它自己实现的算法那一般都可以破解,分析扩展库或解释器就行,如果是商业方案的话就看情况了。
二、漏洞挖掘
文档阅读
在正式分析前,如果有文档要先看文档,特别是内部的产品,一般都能要到仔细的文档,如产品使用手册,功能模块实现手册,各种流程图,开发手册等,通过这些文档就基本能知道这个设备是干什么的,有哪些服务,分别实现了哪些功能,每个功能怎么实现的,数据流逻辑是什么等等:
 而对于外部产品,一般就只能获取到使用手册,有时会有部分技术架构信息,一定要先熟悉这些信息,有了这些信息会避免很多逆向工作,如:
而对于外部产品,一般就只能获取到使用手册,有时会有部分技术架构信息,一定要先熟悉这些信息,有了这些信息会避免很多逆向工作,如:
服务分析
熟悉文档后,就可以分析服务了,登陆到获取这些服务信息,先外后内,如先查看哪些服务监听着所有网卡,iptables规则如何,最终获取外界可访问的服务,再分析服务对应的进程(进程对应文件/启动参数/配置文件)
查看防火墙
一般都是iptables,这里简单记录下解析方式,首先使用sudo iptables -L -nv查看规则策略(v个数越多越详细),iptables默认5条链组成两条路径:PREROUTING->INPUT->本机使用->OUTPUT->POSTROUTING和PREROUTING->FORWARD->POSTROUTING,一般只关注第一条路径,按路径开始查看,首先是它后面的括号里表示都不匹配时的默认策略,接下来就是一条条规则挨个匹配,匹配上则执行对应操作:
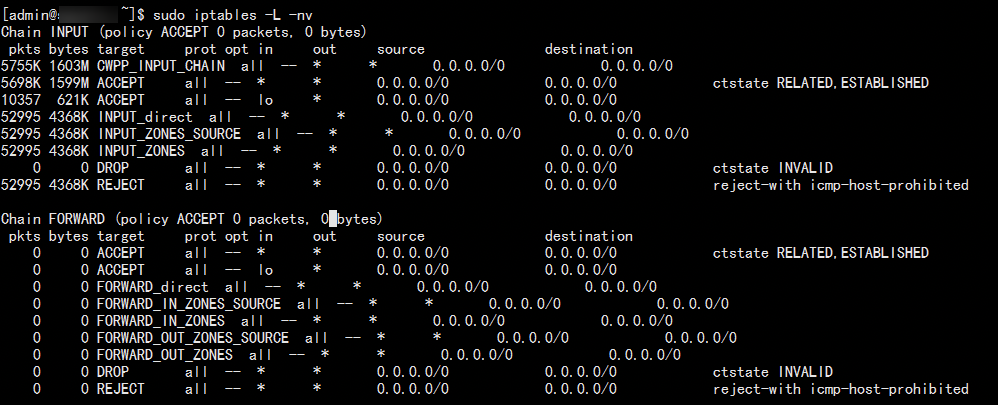
规则在右侧,最右侧会显示扩展规则,使用-m添加,如上图使用了conntrack规则,含义如下:
--ctstate
NEW 匹配新创建的了连接
RELATED 匹配相关联的连接,如默认只开21端口,但在传数据时新开50000端口,它们是相关的就匹配上了
ESTABLISHED 匹配建立好的连接
INVALID 匹配无效连接
再看动作,它其实叫目标(TARGET)也很准确:
ACCEPT: 直接放行,不再继续匹配
DROP: 直接静默丢弃
REJECT: 直接拒绝,当指定了reject-with时,会返回特定的数据包,如上图输入链拒绝时会返回icmp-host-prohibited包
QUEUE: 讲数据包交给用户态某程序继续处理,用于开发用户态防火墙,一般不会见到
RETURN: 返回到上一条链继续向下处理(类似函数的返回,到调用处的下一条规则继续匹配),若已经是默认链了则返回到默认策略
SUB_CHAIN: 跳转到子链处理
在最后还可以用nmap扫下全端口验证一下...
查看监听的端口
一般都可以直接用netstat,也有一些其他的方法:
netstat -pantu | grep LISTEN
sockstat -l # socket信息
这里做的是把暴露的端口和进程对应起来,再利用进程号获取启动参数(可执行文件路径,使用的配置),一般就使用如下命令对服务有个大致了解:
ps aux # 获取进程信息
pstree # 获取进程关系
lsmod # 有哪些内核模块
lspci # 主要查看网卡驱动有没有问题
有了初步了解后,就需要具体分析业务流程:
- 使用了什么技术栈:如使用什么语言,之前的设备perl/c/lua/php/cpp/shell比较多,现在也出现了nodejs/go/python了。
- 关键逻辑怎么实现:如VPN功能,使用apache扩展?nginx扩展?完全自己实现?用户态或内核态实现?
- 数据流是怎样的:一个请求会经哪些服务,路由怎样的?
- ...
逆向分析
对于内部产品的审计,一般是不需要做逆向分析的,因为通常能拿到源码,所以只有在一些特殊的场景需要逆向,如确认编译选项,或某些位置在编译后更清晰等。而在外部产品中一般是避免不了逆向的,但是此时一定要牢记使命,我们是为了挖掘漏洞,因此不要陷入分析功能的巨量工作中,要秉持够用原则,只对关键的感兴趣的点进行分析,只需大致了解它的逻辑,而且用好三分逆向七分蒙不要过度逆向,下面介绍一些分析时的小技巧。
善用程序属性
确认一些程序属性,如静态链接还是动态链接,是否存在符号与调试信息等。动态链接的程序需要去各种so文件里交叉分析很麻烦,但是它的导出函数一般是保留的,因此可以识别函数名,可以编写脚本辅助识别各导入函数的定义位置(以前写了搞丢了,有时间再补上)。而静态链接就不必在多个文件中穿插着分析了,但是它可以把符号去的很彻底,因此可以研究下系统中是否存在它的动态链接版本,再由动态库的符号信息为静态库命名。 之后还可以先查找可用信息,全局查找哪些文件未去除符号,可使用如下脚本扫描:
find . -name '*' | xargs file |grep -i elf |grep no
善用调试信息
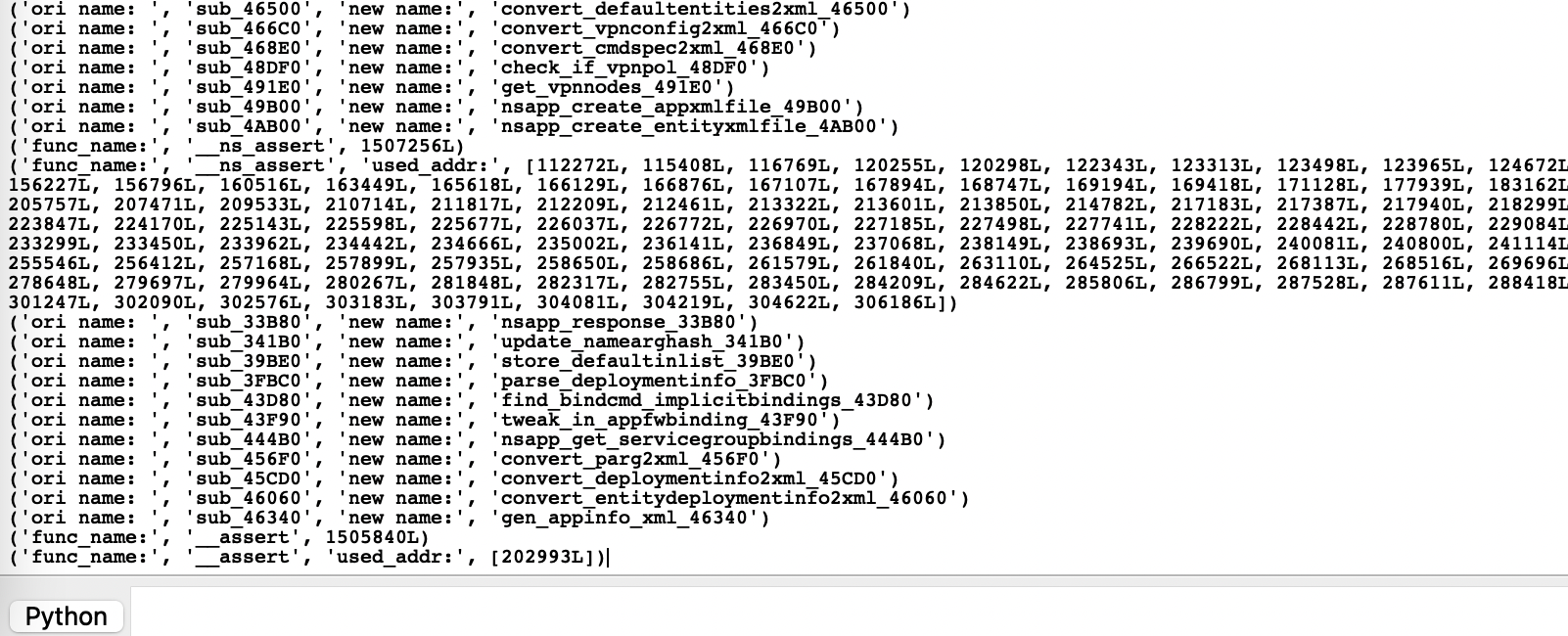
研究它的日志与调试机制,包括很多格式化串。很多程序会把很多日志代码编译进去,这些日志代码将有助于理解程序的功能,有的日志甚至包含函数名称等信息,可以帮助识别函数,一些格式化串也有同样的功能,识别出这些函数特征后,就可以编写一个脚本自动识别出一些函数名。对于那些可以以调试模式启动的程序,可以看看如何进入调试模式(添加启动参数,创建特定文件,发送特定信号等),调试模式可以输出很多详尽的信息,或者去掉一些有利于分析的限制。如下是对某设备进行分析时,识别出的几种调试符号,于是编写脚本可识别出很多函数名:
from idaapi import *
from ida_helper import *
import re
func_map = {
'__ns_assert': 0,
'_nsexception_mark': 3,
'__assert': 0,
'dprintf_pipe': 3,
}
def get_one(arr, start, end):
for one in arr:
if start <= one <= end:
return one
plt_seg = get_segments_info()['.plt']
for func_name, arg_id in func_map.items():
code_addr = name_to_addr(func_name)
print('func_name:', func_name, code_addr)
if not code_addr:
continue
func_ref_addr = get_one(get_xrefs(code_addr), plt_seg['start_ea'], plt_seg['end_ea'])
func_ref_addr = func_ref_addr or code_addr
all_used_addr = get_xrefs(func_ref_addr)
print('func_name:', func_name, 'used_addr:', all_used_addr)
for used_addr in all_used_addr:
try:
arg_val = get_call_arguments(used_addr)[arg_id]
new_func_name = GetString(arg_val)
if not re.match(r'^\w+$',new_func_name):
print('invalid func name', new_func_name)
continue
func = get_func(used_addr)
ori_func_name = get_ea_name(func.start_ea)
if ori_func_name.startswith('sub_'):
new_func_name = ori_func_name.replace('sub', new_func_name)
print('ori name: ', ori_func_name, 'new name:', new_func_name)
set_name(func.start_ea, new_func_name)
except Exception as e:
print(e)%
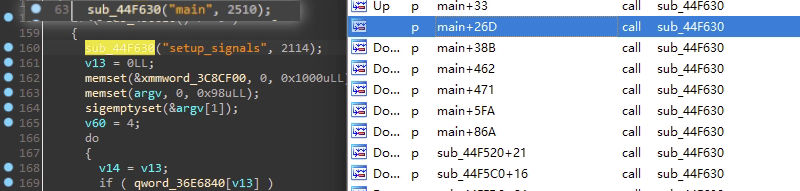
 一般一个带函数名的日志函数在一个函数里被调用多次时,它的函数名字符串是相同的,都是表示当前函数的函数名,但是有时会遇到在同一个函数里调用多次,但函数名字符串不相同,可能会比较迷惑,这一般是一些函数被内联了,此时只能再深入分析看该函数应该选用哪个函数名,例如下图分析到sub_44F630第一个参数可能是当前函数的函数名,但是发现main中调用了好几次该函数,第一个参数却不一定是main,则很可能是其他函数被内联劲main函数了:
一般一个带函数名的日志函数在一个函数里被调用多次时,它的函数名字符串是相同的,都是表示当前函数的函数名,但是有时会遇到在同一个函数里调用多次,但函数名字符串不相同,可能会比较迷惑,这一般是一些函数被内联了,此时只能再深入分析看该函数应该选用哪个函数名,例如下图分析到sub_44F630第一个参数可能是当前函数的函数名,但是发现main中调用了好几次该函数,第一个参数却不一定是main,则很可能是其他函数被内联劲main函数了:
分析结构体
逆向中有个很大工作是分析结构体,实际上大多数代码逻辑并不复杂,但是由于没有结构体详细定义,能看到的只有一坨无意义的变量与偏移操作,而它的域是通过结构体偏移去访问,没有定义为结构体时很多域是无法获取正确的交叉引用的,因此在评估有必要后,需要先把结构体定义分析出来:
- 对此第一步是分析其大小,如果是动态分配到可以直接从malloc等函数知道大小,否则需要去其他地方分析,例如很多结构体是数组,因此看它的循环操作偏移也可以确定其大小,还有一些会在初始时调用memset等功能初始化,也可以获取大小。
- 在识别出大小后,就需要确认它每个域的定义,首先确认各个域的大小,看对某偏移的读写操作可知大小,一般也可以知道它的作用,按作用命名即可,在条件不足以获取作用时,就先命名为xyz,之后有足够条件就可以命名了,而有些偏移还没有足够的信息(在当前函数没使用到),此时可以使用padx[0xYY]对其进行占位,之后遇到了再重定义即可。
抓包分析
在挖掘时一定要避免纯静态分析以及完整分析,要去找一些关键点入手,类似黑加白结合,此时流量信息就很重要了,对此若有日志可以先瞅瞅日志,之后一般需要把tcpdump扔目标上去抓包,之后使用wireshark分析,不过现在基本都上SSL/TLS了,所以数据都是密文,对此一般可以通过导入私钥去解密:
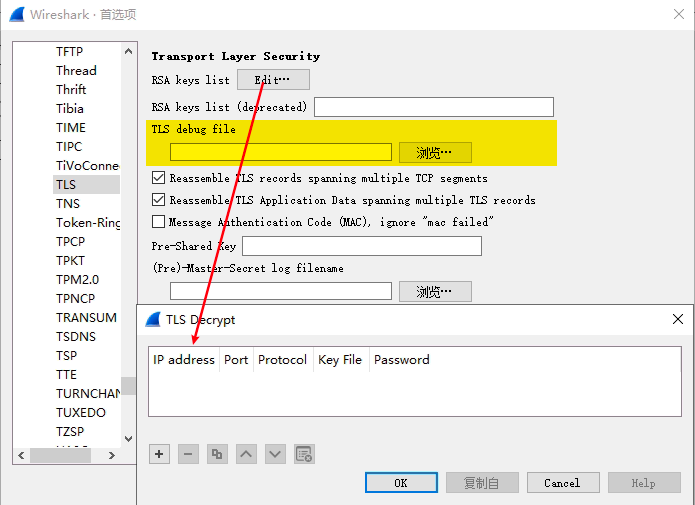
但是现在很多都会使用DH做密钥协商,它的特点就是前向安全,此时私钥也解不开,对此可以看看它自身是否支持导出会话密钥,像Chrome可以通过设置SSLKEYLOGFILE环境变量来输出密钥,或者可以打勾子去DUMP密钥。不过到此时都是只能查看而不能修改,但在做测试时需要修改数据,因此更好的办法是用中间人,此处推荐使用mitmproxy,使用它可以很方便的对数据进行查改操作,而且Python写的也很好做定制,不过它有些小问题,需要多读读它的代码:
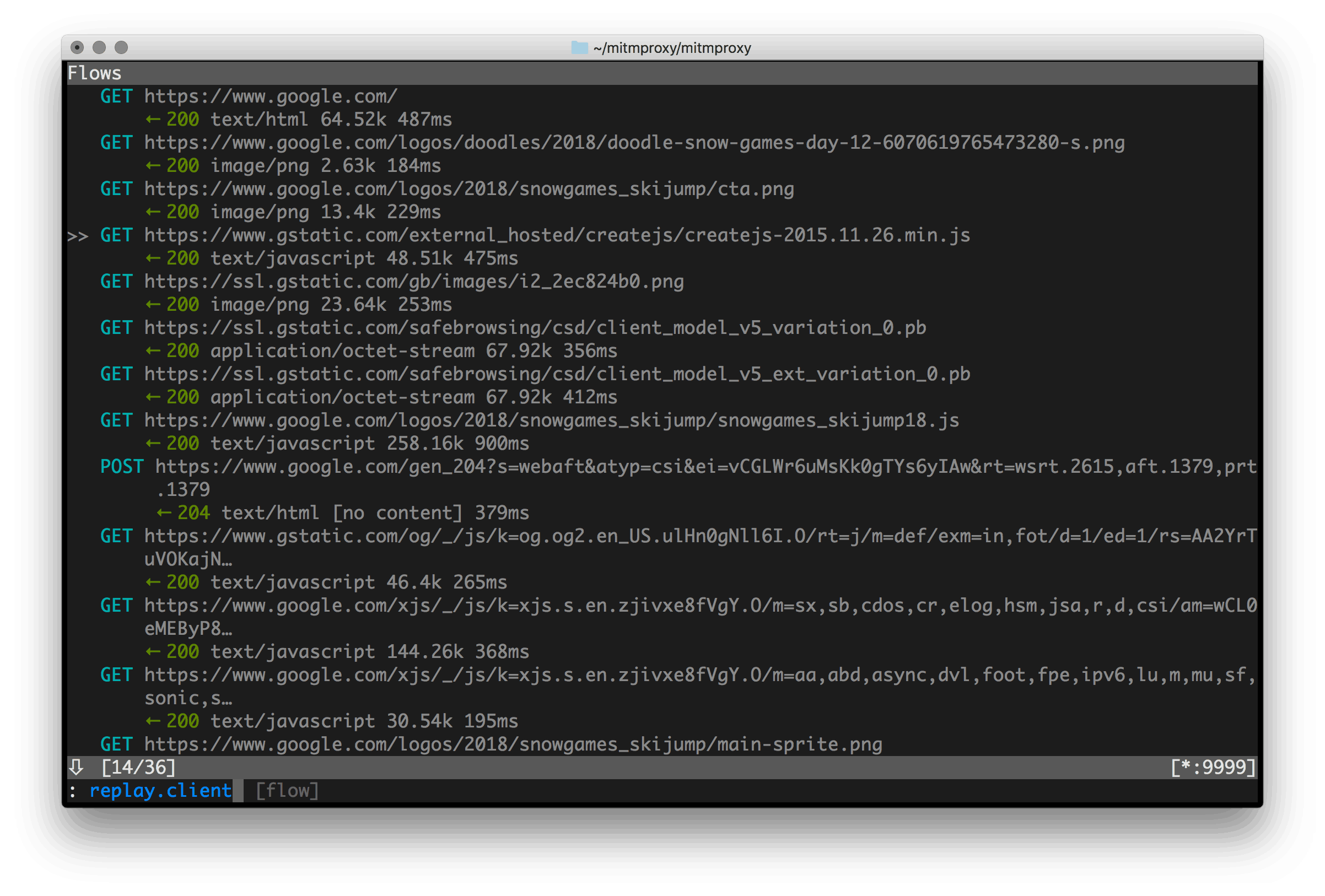
此外还可使用mitm_replay,它的思路很有意思,它将请求和响应封装为http从而可对接burpsuite等工具实现代理拦截。
漏洞挖掘
一般还是先挖掘WEB部分的漏洞,专注于用户页面(管理页面一般不会暴露在公网),web的就那套路,正向与逆向,授权前与授权后。只是设备一般使用cgi,不再是常规的php/java语言了,这里要针对特定语言挖掘。另外是后端服务,一些设备web只是作为前端,最终调用后端服务完成任务,因此接下来还是关注后端服务,此处根据服务特性挖,什么缓冲区溢出,命令注入,还有超好用的SSRF等,这部分内容过多,会单独写几篇。
三、扫尾工作
挖完洞后你有什么想法?
- 对于内部的代码审计,需要编写完整的审计报告,漏洞点,危害,修复方案,之后还需要跟踪修复情况。
- 对于外部的漏洞挖掘,那....嘿嘿嘿🤤....要么就是报给厂商献给国家,要么就是内部留着在某大型行动中发光发热。
- 不管内外,其实这个挖掘过程的收获可以反哺产品线等,比如在挖洞的过程中也会分析对方用了什么保护手法,用了什么技术架构等,这些都是可以学习滴东西。
下面就描述下发光发热要做的步骤。
脱取业务数据
脱数据不是为了做坏事!!!该操作极其危险,必须在授权下进行,这些数据可以方便进一步渗透,如获取账户密码等信息,进行撞库,拓宽攻击面。挖掘到设备漏洞后,需要尝试对设备进行漏洞利用,获取设备中存储的关键数据,如用户敏感信息,各种网络配置,获取这些数据方便红队选手的后续安全渗透测试。这些数据可能以文本形式存放在文件中,或者被加密了,可能存放在各种关系型/键值型数据库中,可能以自定义格式存放(如共享内存dump)等,由于此时已经比较熟悉设备了,所以可以写脚本快速获取这些数据。
后门技术
后门不是为了做坏事!!!在某运动中,维权好多得分,设备是一个比较复杂的系统,因为我们已经比较熟悉它所以可以根据它的特性留下一些隐秘的后门:
- 有web服务的尝试留下webshell,最好是文件不落地的内存马
- 在任务计划或者服务中留反弹shell,最好通讯内容是加密的
- 如果端口限定太死,则尝试通过iptables将带有特定标志的请求转发到设备中监听本地的shell
- 有些设备把协议栈放用户态了,如使用dpdk等,因此可以向用户态协议栈程序处植入补丁,这样是比较难以发现的。(有点rootkit概念了,但是此处只操作用户态程序)
- 对它自带的完整性检查程序做修改,在不影响他功能时,避开我们修改过的文件,如md5sum等程序,让它在计算植入了后门的程序时直接返回原始md5值
- ...点点点,由于是一个系统,可以做的点太多了,总之就是充分利用它自身功能的特性!
痕迹清理
利用漏洞的时候一般会留下痕迹,重点检测一些地方: a.访问日志,清除对应时间对应请求记录; b.错误日志,有时候由于一些版本差异或参数错误可能会导致错误,需要找到对应错误日志予以精准清理或修改伪造; c.数据库日志,有时候存在一些数据的增删查改,会在数据库某些位置留下日志,需要找到变化的数据,精准清理或修改伪造; d.设备中程序自定义的日志,需要分析漏洞利用链中会调用哪些程序,可能会留下哪些日志,这些攻击日志需要精准清理或修改伪造。
业务实现原理
这类似逆向竞品分析,我们也不知道它这样做效果怎么样,我们只知道它是怎么做的,或许还会再想想为什么这么做,例如:
- 使用的什么系统,为啥会用centos,ubuntu,裸Linux,它的好处都有啥,谁说对啦就....
划掉 - 怎么实现功能的,如SSL VPN它用的apache模块?nginx 模块?纯自己开发的框架?什么还有DPDK?好处是啥?
- 做了哪些保护?哪些实现起来简单?哪些极大阻碍了分析?这些主意很好,不过现在是我的了!
因为在挖掘过程中会做很多逆向分析,这些逆向的成果都可以输出来帮助改进产品。