X86的内存硬件
CPU的MMU(Memory-Management-Unit)单元会进行内存映射,即指令中指示的地址并不是真正的物理地址,在操作系统中会涉及三种地址,逻辑地址,线性地址和物理地址,逻辑地址通过段转换后成为线性地址,再经过页转换成为物理地址,如下位保护模式下的逻辑转线性事例:
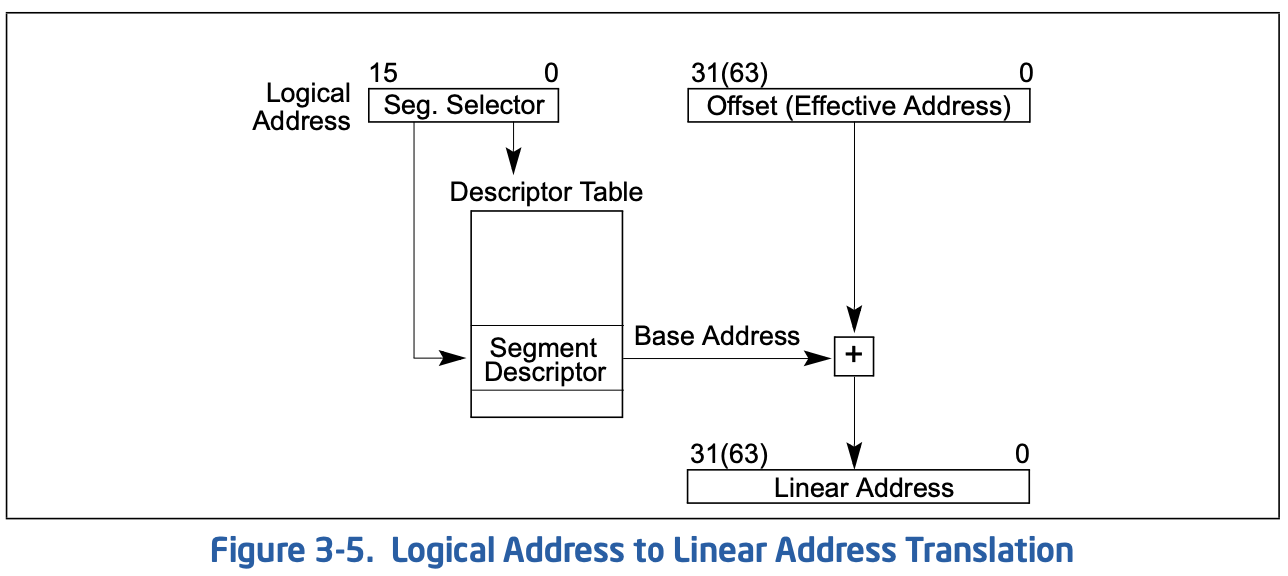
一种特殊情况是指示的地址在转换后无变化,即在未开启分页时,段基地址为0长度为地址空间长度,此时逻辑地址与物理地址相等,可看做直接访问了物理地址。
分段
段机制一直生效,在保护模式时通过段寄存器索引描述符表里的段描述,通过它翻译为线性地址,描述符表就是一个内存中的数组,里面的元素结构如下:

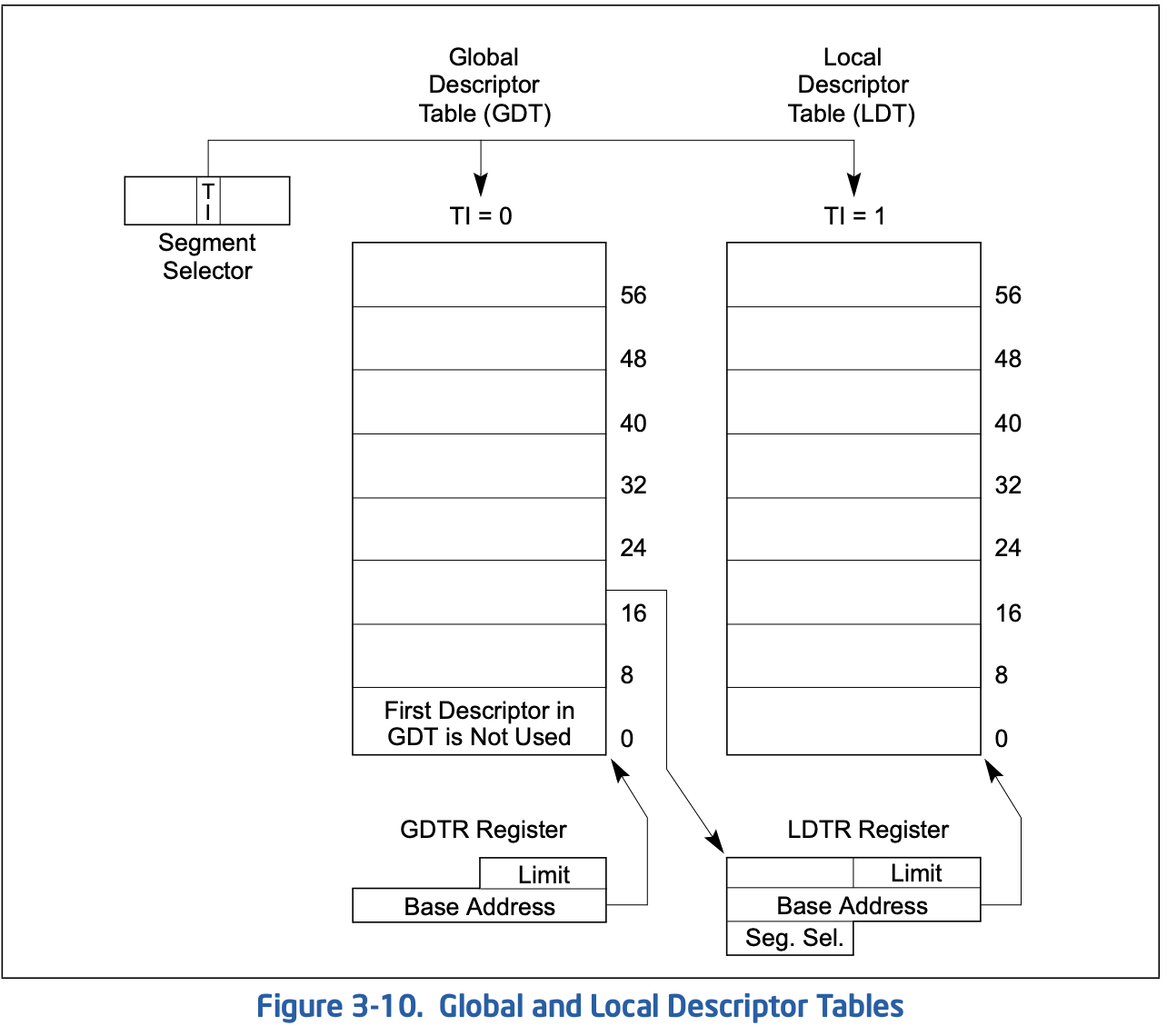
在系统里有全局描述符表GDT和局部描述符表LDT,前者必须存在且可被所有进程访问,后者可以存在0个或多个,可被共享或独占;它们分别被GDTR和LDTR指示,另外还有两个内存管理寄存器TR和IDTR,如下图:
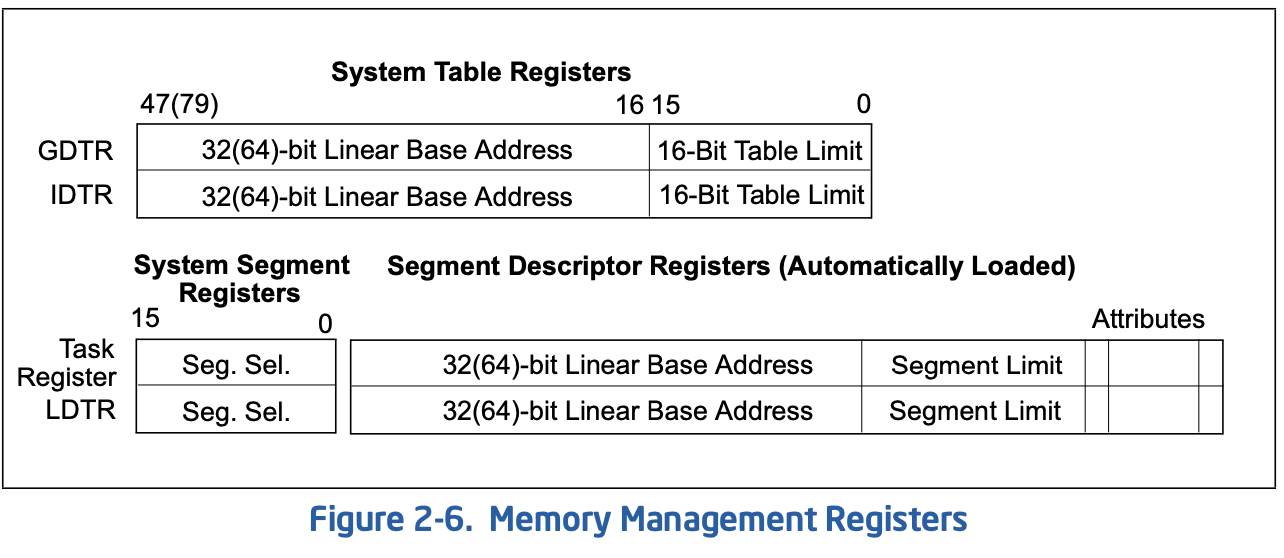
可见本地描述符寄存器GDTR与全局描述符寄存器LDTR功能域类似但是结构不同,GDTR由线性基地址与大小(字节)组成,指向全局描述符表。而本地描述符表处于全局描述符表中,是它的一项,本地描述符寄存器存储的是段选择子,线性基地址,段大小以及属性信息。任务寄存器TR也与LDTR类似,其数据来源于GDT,而中断描述符寄存器IDTR指向的中断描述符表表IDT与GDT类似,因此这两个寄存器结构一致。
X86有6个段寄存器(CS,DS,ES,SS,FS,GS),它们依然为16位(可见),并用于存储14位的段选择子,以及一位表示索引表类型,一位表示请求的特权级:

实际上段寄存器分为可见部分和不可见部分,不可见部分也叫做描述符缓存(descriptor cache)或影子寄存器(shadow register),当可见部分改变时会自动将可见部分段选择子对应的描述符加载到隐藏部分,因此不必每次都再访问内存读段描述符:

每当段选择子改变,它将重新从LDT或GDT中对应项加载段描述符信息,(待验证)段寄存器可用通用的MOV,LEA等指令修改,也可用LDS,LES等专用指令修改,但是CS比较特殊,在修改后只有发生远跳转(CALL,JUMP,IRET等)才会生效。 操作系统一般只将前四个寄存器用于段机制,另外的FS和GS一般被用作特殊用途。Linux未使用段机制,即采用flat模型,它将这四个寄存器全部指向0,故逻辑地址和线性地址一致,可认为不存在分段,因此也可以说Linux中程序使用的线性地址。
在Windows下,32位使用FS指向TIB,而GS可能指向TLS或未使用,在64位下使用使用GS指向TIB而FS用于Wow64。
在Linux下,内核使用GS指向每CPU区域;在用户空间,X64下一般GCC使用FS指向TLS。
分页
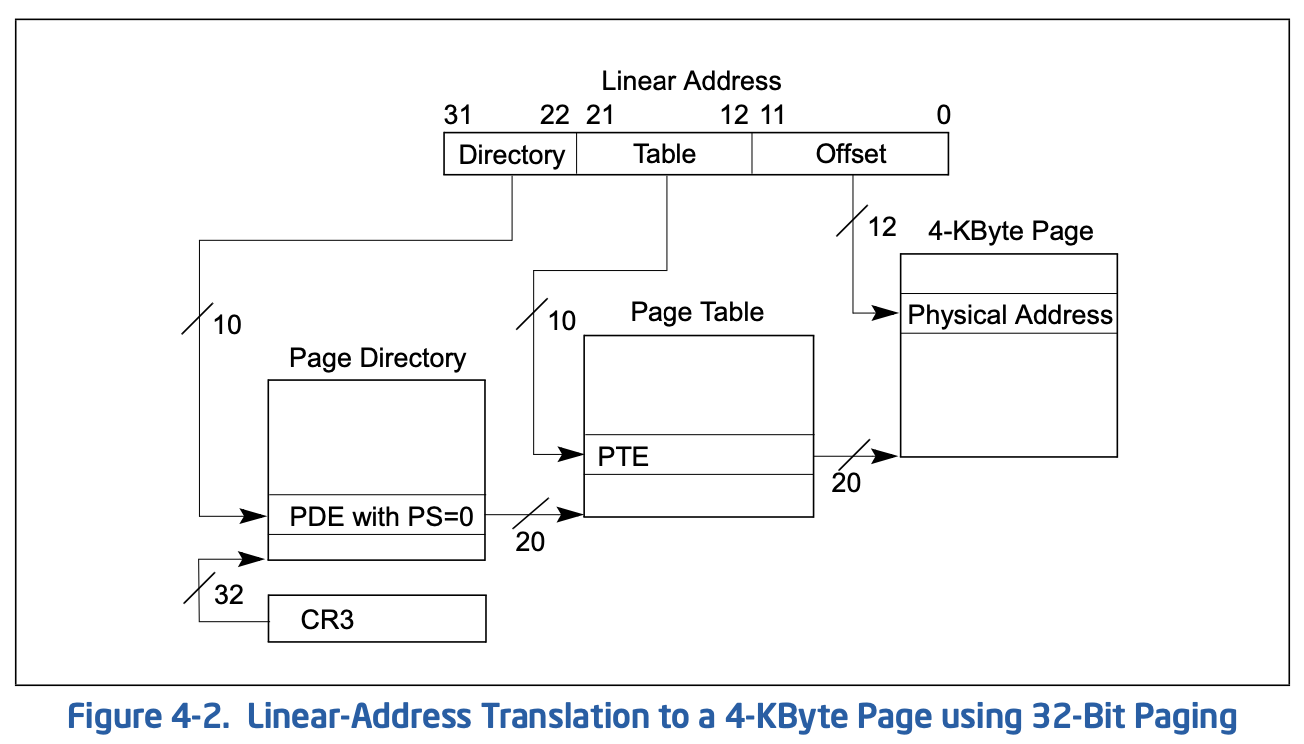
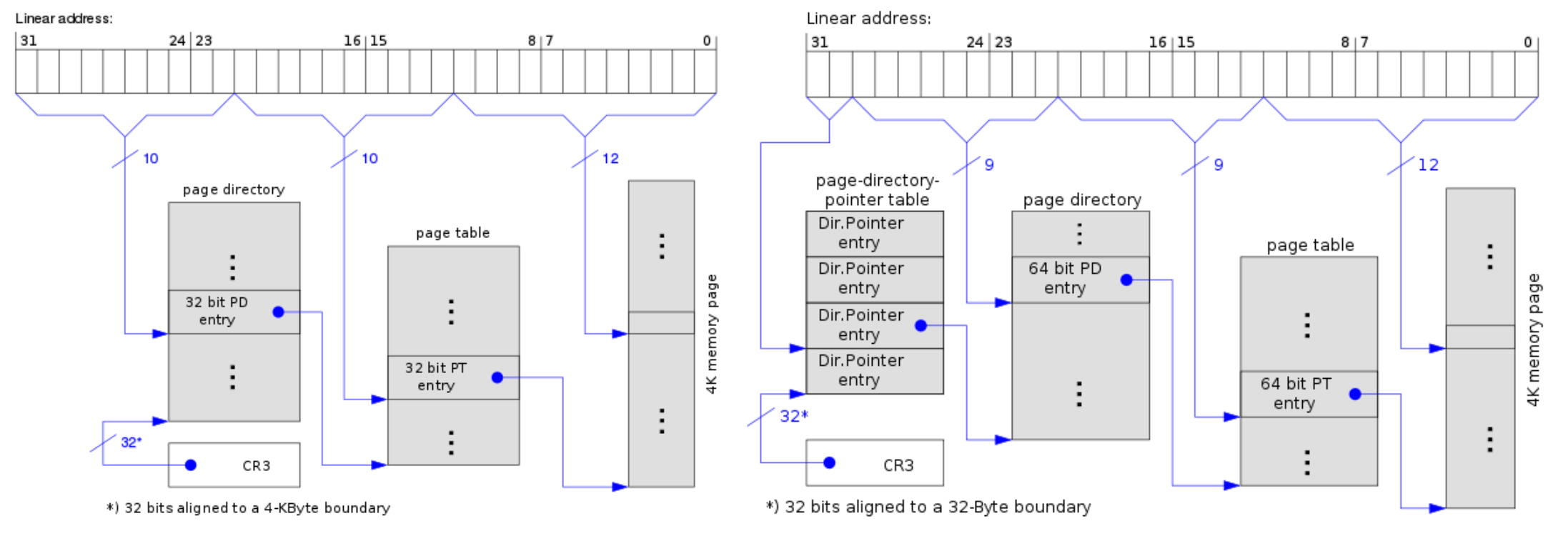
尽管操作系统里有分页,但分页实际也是由CPU支持的,32位下为两级分页,CPU会把一个线性地址分为多个部分(2或3),前10位用于表示页目录项的索引,先查询到对应的页目录项,根据其标志判断分页大小,若PS=0表示4k,则目录项中的地址为对应的页表的地址,接下来再去线性地址的中间10位查询页表中的页表项,获取页的物理地址,并使用最后的12位作为页内偏移,如下图:
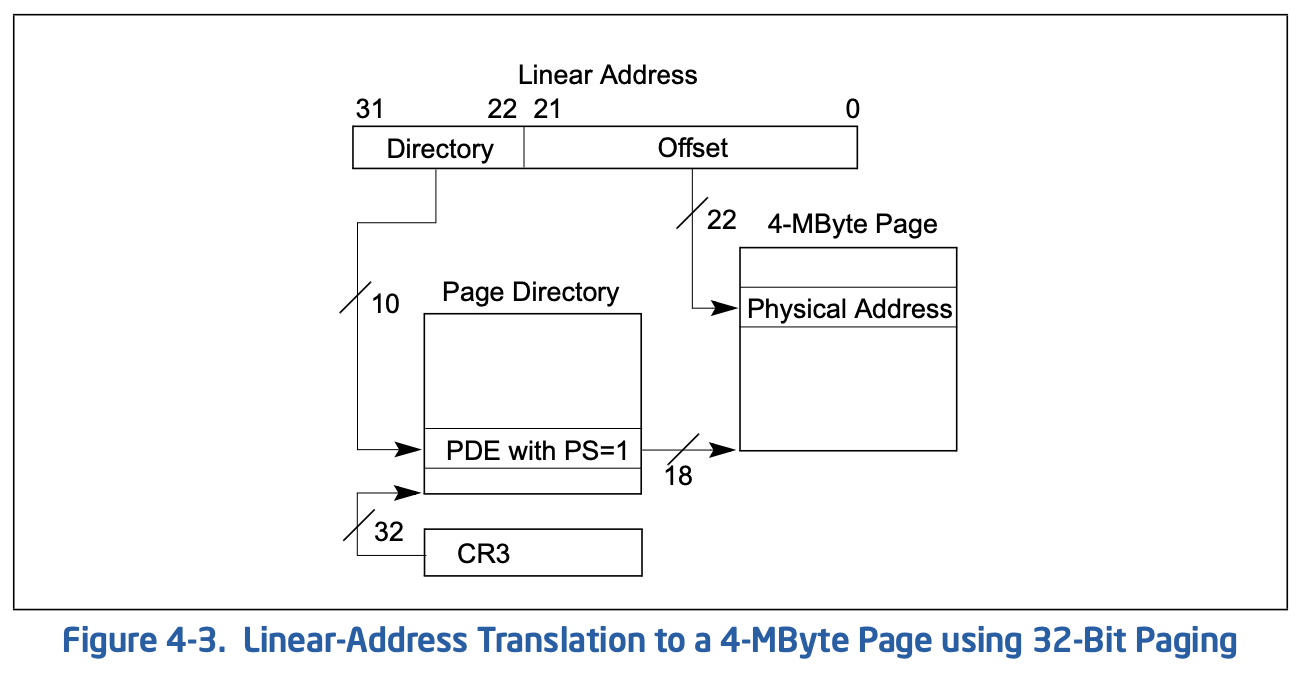
而当页目录项的PS=1时表示启用了4M的大页,此时页目录项里的地址即为页的物理地址,剩余的22位为页内偏移,如下图:
上面涉及到页目录项(PDE)与页表项(PTE)都是32位,内部使用20位用作基址,因为页表与页都是4k(或4M)对齐的,因此20足够表示,而剩余12位则可用于记录标志,其结构如下:
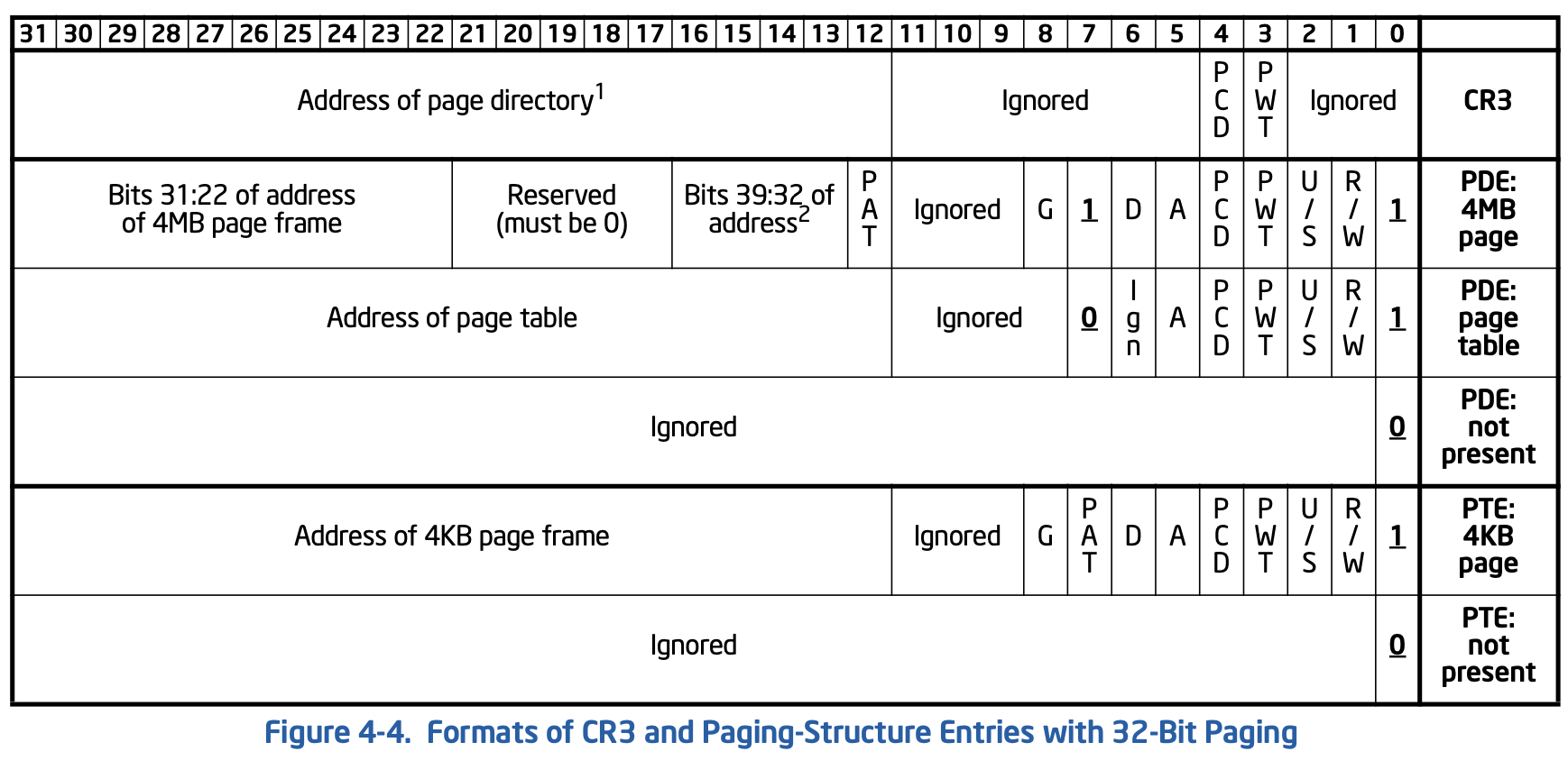
如图,它们的:0为P标志表示该项是否存在,:1为读写权限,:2为特权,:5为访问标志,:6为脏数据标志,这两个标志用来实现替换与回写,PDE的:7为PS作用如上述,:8表示是否为全局,如内核页为全局的,在切换进程时就可以不必清除该页的TLB,最后再看上图里的PWT(Page Write Through)/PCD(Page Cache Disable)/PAT(Page Attr Table),它们用于表示缓存类型,在不支持PAT时该位为0,详见后文。
它有5个控制寄存器,其中CR8只在64位下有效,其他四个如下图:

控制寄存器用于表示当前任务的CPU属性: + CR0:各种标志,PE->Protection Enable,WP->Write Protect,PG->Paging,CD->Cache Disable
-
CR2:记录页错误时的页地址
-
CR3:记录页目录的物理基址(由于是4K对齐,因此左移12位即实际地址)。
-
CR4:启用一些CPU功能
在Linux下为了统一,它使用四级页表,故一个线性地址可分为如下部分:
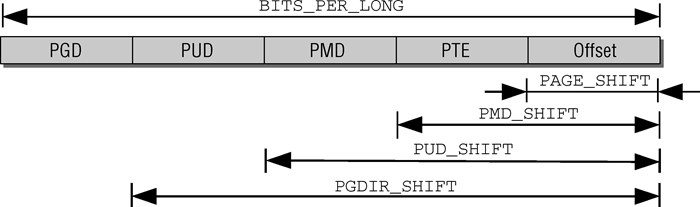
它们分别表示页全局目录PGD(Page Global Directory),页上级目录PUD(Page Upper Directory),页中间目录PMD(Page Middle Directory),页表项PTE(Page Table Entry),实际偏移Offset,此时需要四张表,PML4T(Page Map Level4 Table),PDPT(Page Directory Pointer Table),PDT(Page Directory Table),PT(Page Table)来存储页目录与页表项,但在32位下PUD与PMD只占0位,此时PDPT与PDT已经收敛到PT上了,因此满足硬件的2级页表。
PAE
注意CPU的位数指运算的宽度,与地址宽度无关,当前x64一般实现了48位地址线可支持128T内存(或57位可支持64P),而低位数的CPU也可以使用高位数的寻址空间,如16位的8086可配合段寄存器寻址20位,32位也可以使用更宽的地址线,即PAE(Physical Address Extension)技术,它将地址线由32位扩展到了36位,从而可支持最大64G物理内存,但是并没有引入其他新机制,因此实际上每个进程最大能使用的空间仍然是4G,如下分别是普通的x86 4K页与开启了PAE的4K页:
此时,它的页表结构如下:
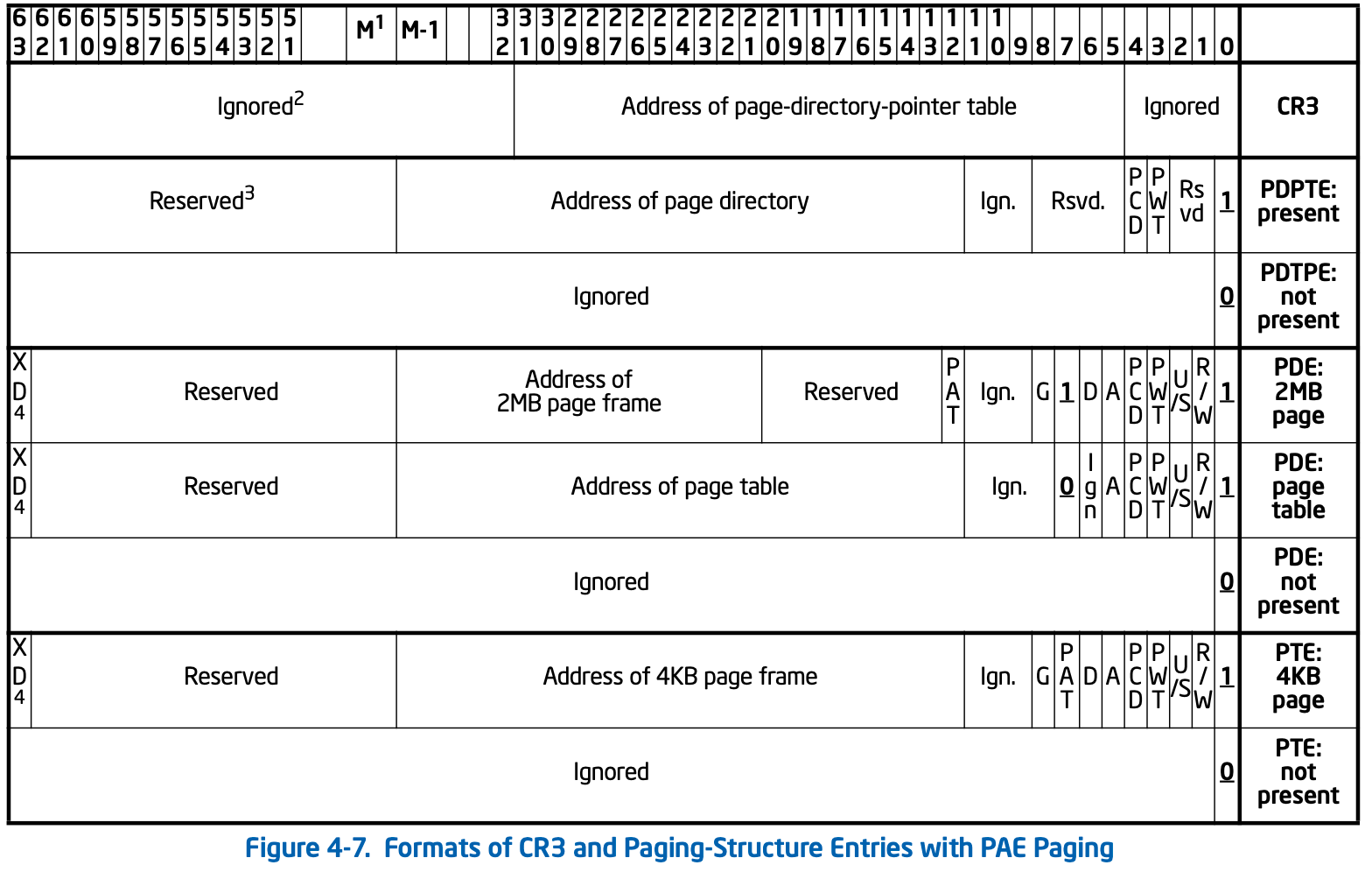
可见它们的页目录和页表长度都变为了64bit,因此能寻址更大的空间。另外注意,从PAE开始,页表项的最高位为XD(eXecute Disable,AMD叫NX),置位时表示该页不可执行。
X64与MSR
上面已经提及,X64首先扩展了地址线宽度,当前通常是48位,也变成了4级目录,因此它支持更大(1G)的大页,如下:
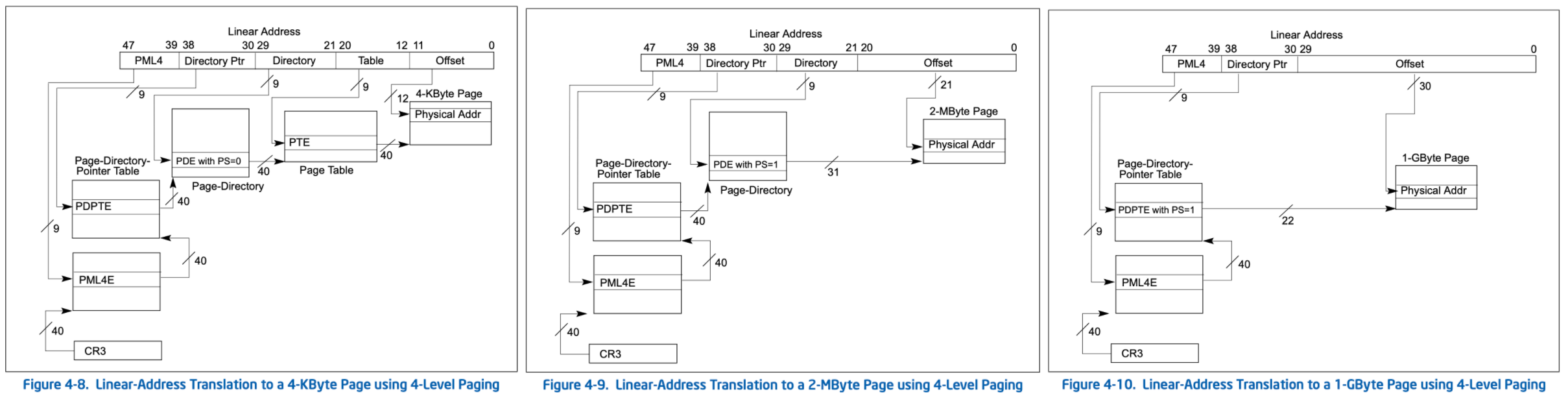
此时它的页目录相关结构如下:
另外在长模式下,CPU不再使用段机制,可以向CS/DS/SS/ES赋值,但它不会使用GDT/LDT,并认为段基址都为0,且不再检查段长度(包括GS/FS),而GS和FS仍然可用,不过此时不再使用GDT记录段描述符,而是使用MSR。
MSR(Model Specific Register)是处理器增加但当时不属于那个ISA的寄存器,它们需要用特殊指令访问,另外使用CPUID去查询是否存在相关特性与寄存器:
void cpuGetMSR(uint32_t msr, uint32_t *lo, uint32_t *hi)
{
asm volatile("rdmsr" : "=a"(*lo), "=d"(*hi) : "c"(msr));
}
void cpuSetMSR(uint32_t msr, uint32_t lo, uint32_t hi)
{
asm volatile("wrmsr" : : "a"(lo), "d"(hi), "c"(msr));
}
这些寄存器使用偏移访问,其中有些寄存器已经稳定下来成为标准了,就给他们起了个以IA32_为前缀的名字,此处关注的是如下三个寄存器:
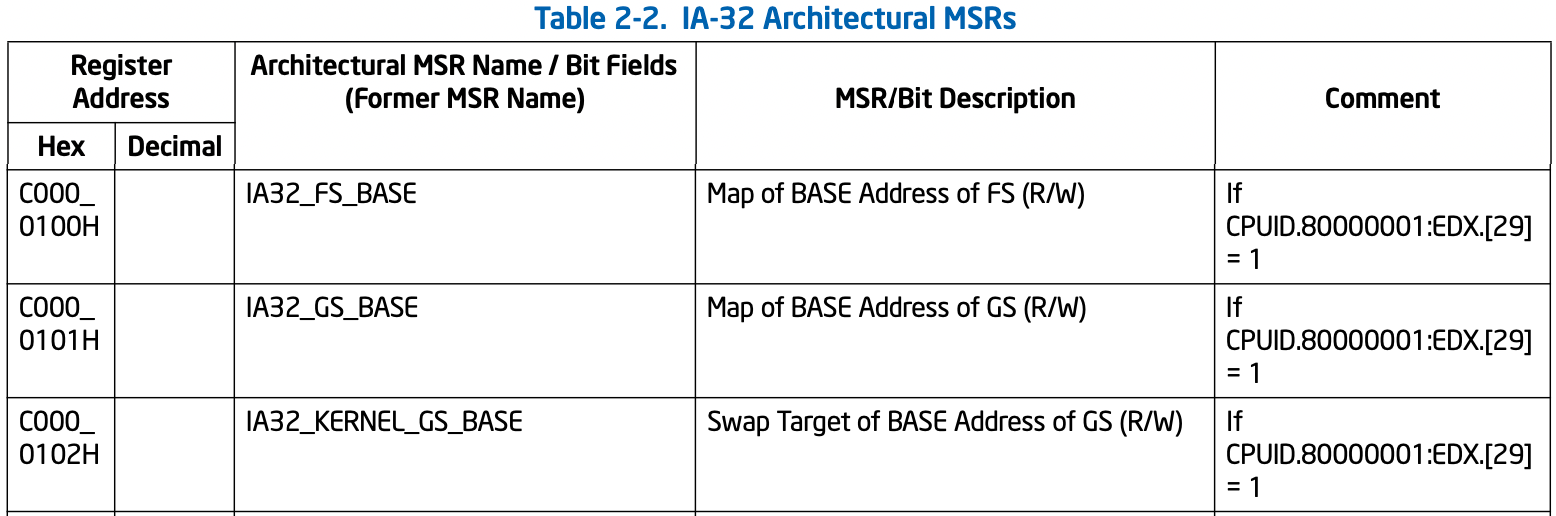
它们分别存放FS/GS/KernelGS段基址,其中KernelGS是指当程序运行于用户态时,操作系统可把内核态的GS存放于此处,在进入内核态时,就可使用SWAPGS指令将GS与KernelGS的值进行交换,从而实现快速GS切换。
CACHE
TLB
想想若是每次访存时都要经过2级或更多级查表,也就是多次内存访问才能获取到真正的页帧地址,那么效率将极低,事实上CPU会使用TLB(Translation Lookaside Buffer)缓存最近访问页桢,根据局部性原理将会显著提高效率,现在的很多性能优化也是从这点入手的:

TLB有个很重要的问题就是缓存一致性问题,这点特别复杂我也不懂,反正很明显的一点,若CR3换了那缓存的内容当然都应该失效,而修改来页的映射后也需要手动使用INVLPG指令使原缓存失效。
MTRR
另外还有个不起眼的部件叫内存类型范围寄存器用于记录内存的缓存策略,注意这主要是在多处理系统下保证效率与一致性,有如下5种缓存策略:
| Memory Type and Mnemonic | Encoding in MTRR | 说明 |
|---|---|---|
| Strong Uncacheable (UC) | 0x00 | 完全不使用缓存 |
| Write Combining (WC) | 0x01 | 写组合先将数据存入WC缓存,并在之后使用burst模式同步到内存,可能会破坏数据写顺序 |
| Write-through (WT) | 0x04 | 写直通即写操作会直接更新内存,若当前缓存有效则会将其置位无效或者同时更新缓存 |
| Write-protected (WP) | 0x05 | 写保护即读取时直接从缓存中读,但写入时会同步到内存并使缓存失效 |
| Writeback (WB) | 0x06 | 写回即先把数据存入缓存并标记为脏数据,在缓存被换出时再同步到内存 |
| Uncacheable (UC-) | Nil | 只在PAT里可用,为0x07,类似UC但可被WC覆写 |
| Reserved | Nil | 不可设置否则抛#GP |
对物理地址,缓存方式可能通过三类方式定义,固定范围,可变范围与默认值,如下:
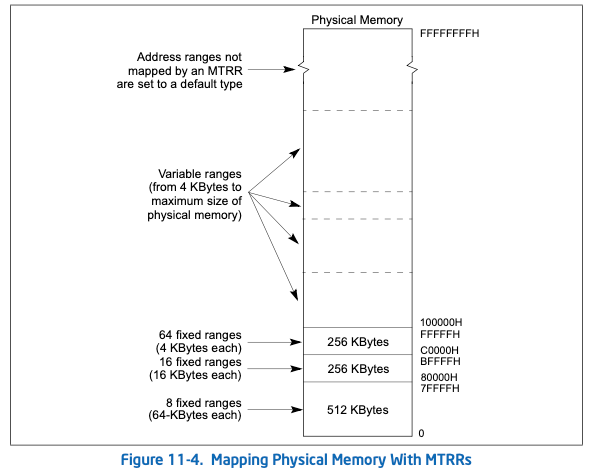
通过IA32_MTRRCAP可获取MTRR支持的类型,可变范围的数量等:

IA32_MTRR_DEF_TYPE用于启用MTRR以及设置默认的内存类型:
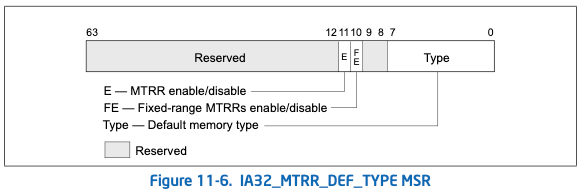
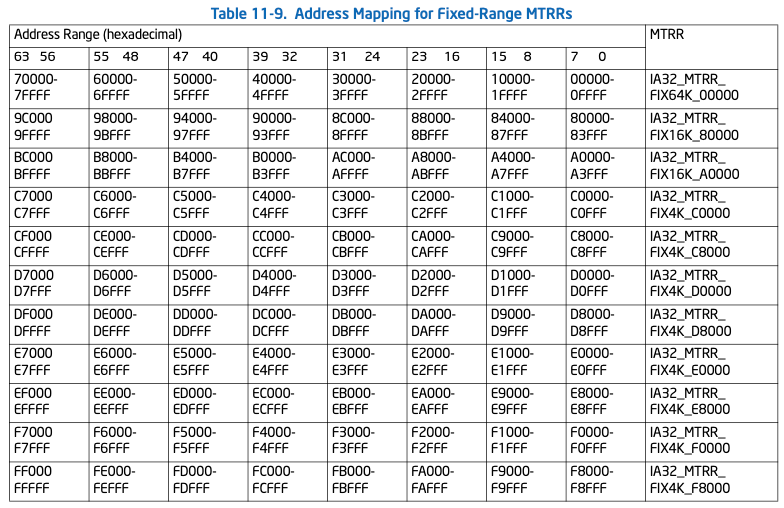
固定范围的MTTRs共有11个,但每个又分为8部分,可单独设置对应位置的类型,如下图:
可变范围的寄存器个数由IA32_MTRRCAP获取,每个范围由两个寄存器IA32_MTRR_PHYSBASEn与IA32_MTRR_PHYSMASKn来存储,用于记录基址,长度,类型与有效位,如下:

Linux下可使用/proc/mtrr查看已设置的MTRR:
root@bm:~# cat /proc/mtrr
reg00: base=0x000000000 ( 0MB), size=524288MB, count=1: write-back
reg01: base=0x0c0000000 ( 3072MB), size= 1024MB, count=1: uncachable
PAT
页属性表是一种单独的设置内存的方式,MTRR是设置物理内存范围的缓存类型(一般由BIOS实现),而PAT是设置线性地址的缓存类型(一般由操作系统实现),先在IA32_PAT里定义内存类型,上面已知用3位(8种)即可表示类型,因此64位的MSR被分为了8部分,每部分可表示某种类型,如下:
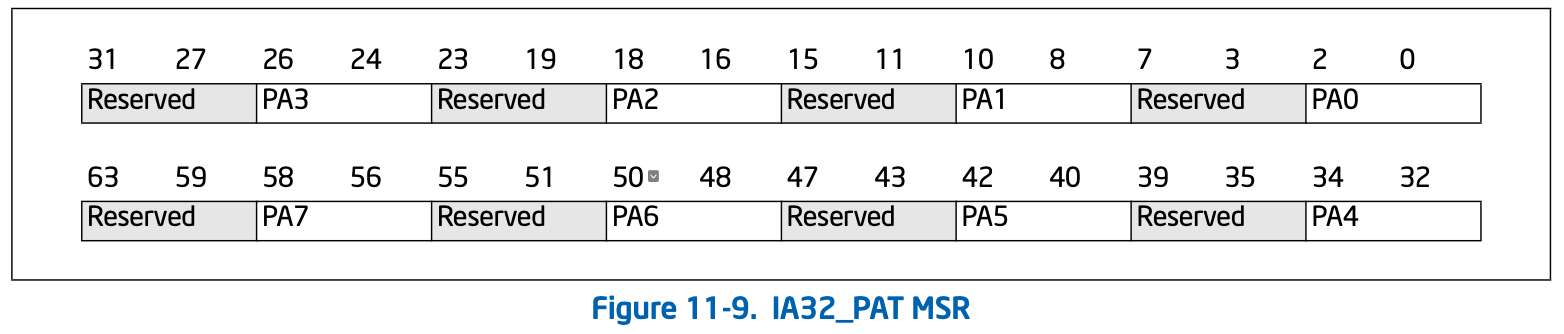
为了兼容,CPU重置后它的默认值如下:
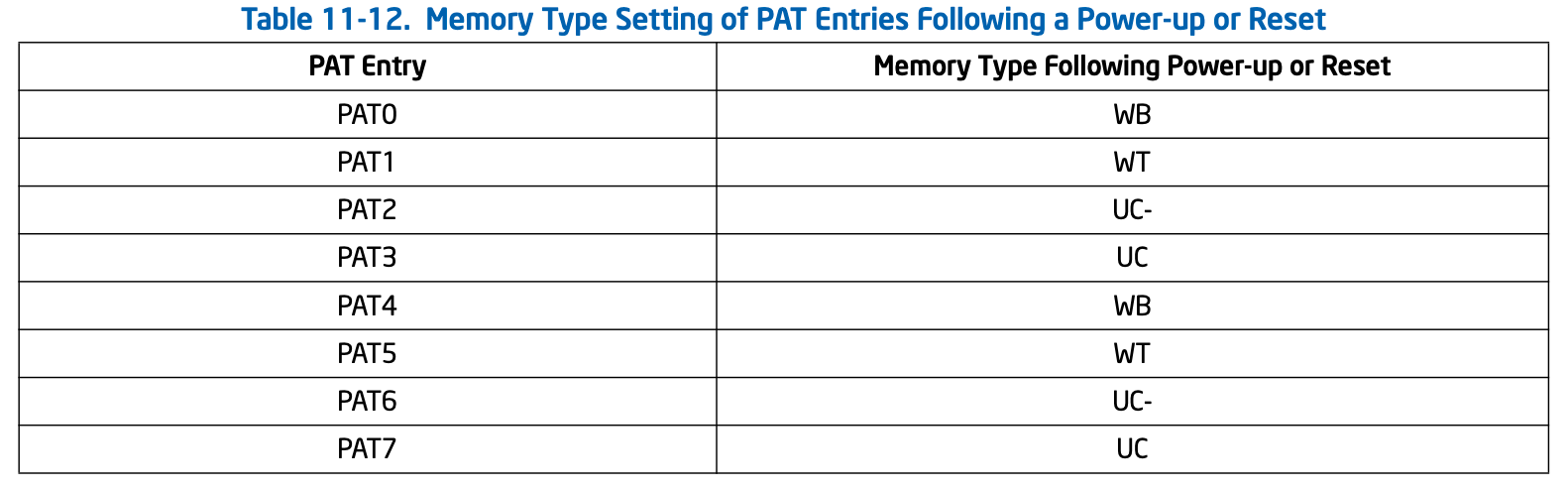
用户可对其进行改写,再回顾上文提到的PCD/PWT/PAT,页表就是通过这三位作为索引,查PAT获取实际类型的:

内存布局
Linux x86的用户程序默认使用低3G作为专属的用户空间,共享高1G的空间:
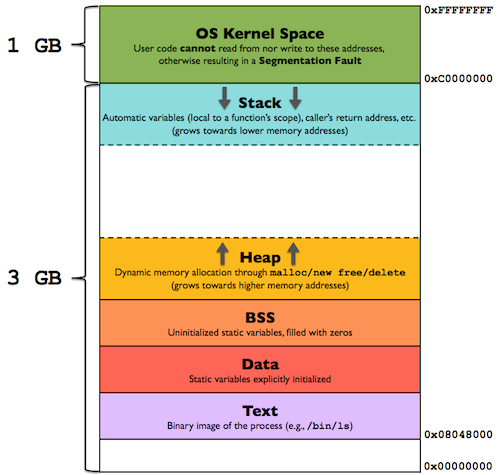
这是从虚拟地址空间的角度查看的,从物理地址空间的角度,在系统初始化时,会根据可用物理内存的大小,将一部分内存先映射到内核,即建立页表,内核之后就可以不再建立映射关系而使用它们了,不过注意不是直接使用它们,也需要通过正规的登记流程,否则可能造成严重的错误。
X86
为了避免用户态与内核态转换时切换页表,以及增加实现的复杂性,内核态与用户态会共用线性空间,在X86下该空间为4G,Linux默认使用1:3的比例分配,此时内核不会(也不能)把所有物理内存全部映射到自己的线性区域,而只会把前896M直接映射,即在系统初始化时就会对该区域建立页表,这种映射为直接映射,此时物理地址与虚拟地址可使用如下宏进行转换:
#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
剩下的物理内存此时并没有被映射到虚拟地址空间,该区域被称为高端内存,这会在必要的时候建立映射: 表:32位物理地址布局
| 名称 | 范围 |
|---|---|
| ZONE_DMA | 内存开始的16MB |
| ZONE_NORMAL | 16MB~896MB |
| ZONE_HIGHMEM | 896MB ~ 结束 |
内核可用1G线性空间,只直接映射896M是为了在灵活的使用其他区域时有线性空间可用,若实际内存不大于896M或内核线性地址空间很大(如64位)时,可全部映射,至于为什么是896M,是因为当前的实现中内核必须留128M用于其他用途,内核的虚拟地址空间划分如下:
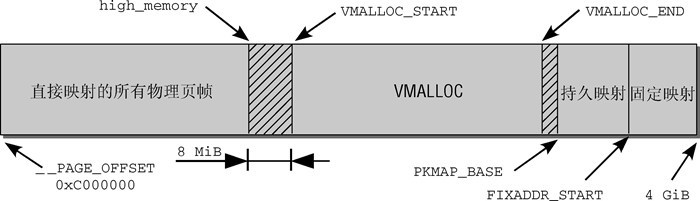
内核通常会使用连续的物理内存,这在系统刚启动时问题不大,但运行一段时间后可能存在较多碎片,此时若加载驱动等导致的大内存分配就只能依赖VMALLOC区的不连续内存分配了,其余常量定义如下:
#define VMALLOC_OFFSET (8*1024*1024)
#define VMALLOC_START (((unsigned long) high_memory + 2*VMALLOC_OFFSET-1) & ~(VMALLOC_OFFSET-1))
#ifdef CONFIG_HIGHMEM
# define VMALLOC_END (PKMAP_BASE-2*PAGE_SIZE)
#else
# define VMALLOC_END (FIXADDR_START-2*PAGE_SIZE)
#endif
#define LAST_PKMAP 1024
#define PKMAP_BASE ( (FIXADDR_BOOT_START -PAGE_SIZE*(LAST_PKMAP + 1)) & PMD_MASK )
#define __FIXADDR_TOP 0xfffff000
#define FIXADDR_TOP ((unsigned long)__FIXADDR_TOP)
#define __FIXADDR_SIZE (__end_of_permanent_fixed_addresses << PAGE_SHIFT)
#define FIXADDR_START (FIXADDR_TOP -__FIXADDR_SIZE)
X64
64位下可用线性地址已经足够,因此布局会和32位下存在区别,由于当前并没有完全实现64位地址线,而通常是采用48位,此时处理器使用了符号扩展来表示超出范围的虚拟地址与物理地址间的映射,如下图:

此时虚拟地址空间按下图组织:
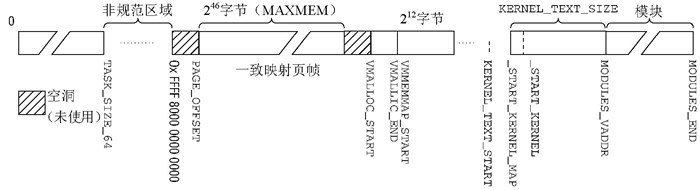 注意相比32位,它在VMALLOC后多了约1T的VMM用于稀疏内存模型,其余常量定义如下:
注意相比32位,它在VMALLOC后多了约1T的VMM用于稀疏内存模型,其余常量定义如下:
#define __AC(X,Y) (X##Y)
#define _AC(X,Y) __AC(X,Y)
#define __PAGE_OFFSET _AC(0xffff810000000000, UL)
#define PAGE_OFFSET __PAGE_OFFSET
#define MAXMEM _AC(0x3fffffffffff, UL)
#define VMALLOC_START _AC(0xffffc20000000000, UL)
#define VMALLOC_END _AC(0xffffe1ffffffffff, UL)
#define __PHYSICAL_START CONFIG_PHYSICAL_START
#define __KERNEL_ALIGN 0x200000
#define __START_KERNEL (__START_KERNEL_map + __PHYSICAL_START)
#define __START_KERNEL_map _AC(0xffffffff80000000, UL)
#define KERNEL_TEXT_SIZE (40*1024*1024)
#define KERNEL_TEXT_START _AC(0xffffffff80000000, UL)
#define MODULES_VADDR _AC(0xffffffff88000000, UL)
#define MODULES_END _AC(0xfffffffffff00000, UL)
#define MODULES_LEN (MODULES_END -MODULES_VADDR) // 1920M
内存管理系统
Linux的内存子系统挺复杂的,详细分析清楚要很多篇幅,这里只概述一下,它的层级如下:
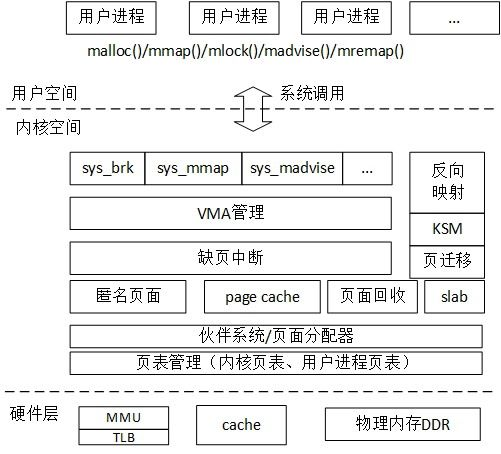
在底层为了统一UMA与NUMA,Linux将内存按节点,域,页帧方式组织管理物理页,它们分别使用pg_data_t/zone/page结构体来表示,其关系如下:
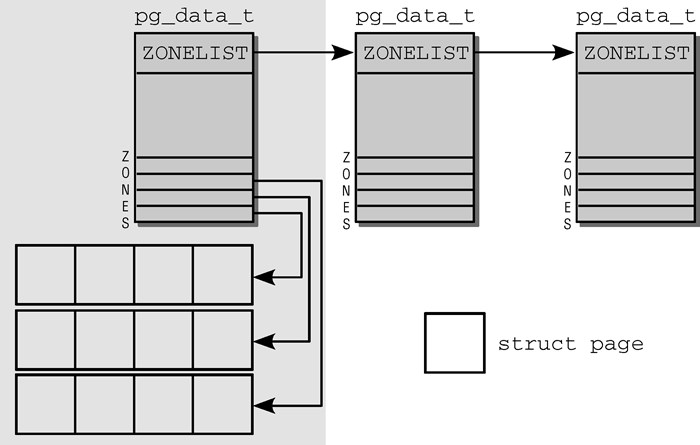
所有page实例存放在名为mem_map的全局数组里,可把UMA看作NUMA的特例,此时只有一个节点,所有页由它管理,它们会被分为多个域,如上表可见,可以有DMA域,Normal域与HighMem域等,它们的珍贵程度依次减弱,因此在分配时需要根据域找到最合适的页进行分配。
start_kernel ->
setup_arch 体系结构相关的初始化自举分配器,此处只关注IA
machine_specific_memory_setup 通过E820获取内存区信息
parse_early_param 解析内核启动参数,获取mem相关的设置
setup_memory 确定每个节点的可用内存页,初始化bootmem/memblock,分配内存区
setup_bootmem_allocator
init_bootmem
register_bootmem_low_pages 释放潜在可用的内存页
reserve_bootmem 用于分配一些内存页
paging_init 初始化内核页表(存入swpper_pg_dir)并启用分页,判断并启用PAE,EDP等
pagetable_init 初始化直接映射,固定映射,判断并启用PSE,PGE
kernel_physical_mapping_init
permanent_kmaps_init
load_cr3
__flush_all_tlb
kmap_init 使用kmap_pte保存高端内存到内核空间的页表项,kmem_vstart保存第一个固定映射的地址
zone_sizes_init 以页帧为单位存储了不同内存区的边界
add_active_range
free_area_init_nodes
setup_per_cpu_areas 初始化per_cpu区域,即为每个核复制该段
huild_all_zonelists 创建节点与内存域
mem_init 停用bootmem/memblock并迁移到伙伴系统
kmem_cache_init 初始化内核内部用于小块内存区(如slab)的内存分配器
vmalloc_init
setup_per_cpu_pageset 为pageset数组的第一个数组元素分配内存
BOOTMEM
在内核启动之初,内存子系统还未初始化时的内存分配器,它采用最先适配的方式管理内存,它只管理非高端内存,常见用接口如下:
// 如下函数用于分配指定大小的内存,默认按CACHE对齐,可指定按PAGE对齐,也可指定分配的区域
#define alloc_bootmem(x) __alloc_bootmem((x), SMP_CACHE_BYTES, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_low(x) __alloc_bootmem((x), SMP_CACHE_BYTES, 0)
#define alloc_bootmem_pages(x) __alloc_bootmem((x), PAGE_SIZE, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_low_pages(x) __alloc_bootmem((x), PAGE_SIZE, 0)
// 实际调用该函数分配内存
void * __init __alloc_bootmem(unsigned long size, unsigned long align, unsigned long goal)
在伙伴系统初始化完成后,它需要将控制权交给伙伴系统,方法就是调用伙伴系统的释放函数回收内存,另外init区域的内存也会返还给伙伴系统。
MEMBLOCK
这是BOOTMEM的后继,其结构如下:

BUDDYSYSTEM
直接映射
伙伴系统把连续页按长度组织,如下图:
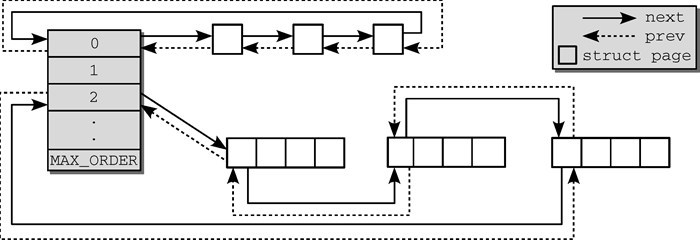 常用如下函数,这里分配的物理地址都是连续的:
常用如下函数,这里分配的物理地址都是连续的:
// 从当前节点分配一页,返回page的地址,mask含义见后文
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
// 从当前节点分配2的order次方个连续页,返回第一个page的地址
#define alloc_pages(gfp_mask, order) alloc_pages_node(numa_node_id(), gfp_mask, order)
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
// 分配一页,返回页的线性地址
#define __get_free_page(gfp_mask) __get_free_pages((gfp_mask),0)
// 从DMA区分配2的order次方个连续页,返回页的首地址
#define __get_dma_pages(gfp_mask, order) __get_free_pages((gfp_mask) | GFP_DMA,(order))
// 它们最终调用如下函数
fastcall unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
// 它们最终都是调用如下函数分配的内存
struct page * fastcall __alloc_pages(gfp_t gfp_mask, unsigned int order, struct zonelist *zonelist)
// 释放内存
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr),0)
void free_pages(unsigned long addr, unsigned int order)
static inline void __free_one_page (struct page *page, struct zone *zone, unsigned int order);
mask的含义如下:
 解释为:
解释为:
// 限制分配的位置
#define __GFP_DMA ((__force gfp_t)0x01u)
#define __GFP_HIGHMEM ((__force gfp_t)0x02u)
#define __GFP_DMA32 ((__force gfp_t)0x04u)
...
#define __GFP_MOVABLE ((__force gfp_t)0x100000u) /* 页是可移动的 */
// 限制分配器行为
#define __GFP_WAIT ((__force gfp_t)0x10u) /* 可以等待和重调度,分配期间切换任务 */
#define __GFP_HIGH ((__force gfp_t)0x20u) /* 应该访问紧急分配池,在失败就会死的场景使用它 */
#define __GFP_IO ((__force gfp_t)0x40u) /* 可以分配期间可以启动物理IO,即该期间可以换出页 */
#define __GFP_FS ((__force gfp_t)0x80u) /* 可以调用底层文件系统 */
#define __GFP_COLD ((__force gfp_t)0x100u) /* 需要没有被缓存的冷页 */
#define __GFP_NOWARN ((__force gfp_t)0x200u) /* 分配失败时警告 */
#define __GFP_REPEAT ((__force gfp_t)0x400u) /* 尝试重新分配直到到达阈值 */
#define __GFP_NOFAIL ((__force gfp_t)0x800u) /* 一直分配直到成功 */
#define __GFP_NORETRY ((__force gfp_t)0x1000u) /* 不重试,可能失败 */
#define __GFP_NO_GROW ((__force gfp_t)0x2000u) /* slab内部使用 */
#define __GFP_COMP ((__force gfp_t)0x4000u) /* 增加复合页元数据 */
#define __GFP_ZERO ((__force gfp_t)0x8000u) /* 成功则返回填充字节0的页 */
#define __GFP_NOMEMALLOC ((__force gfp_t)0x10000u) /* 不使用紧急分配链表 */
#define __GFP_HARDWALL ((__force gfp_t)0x20000u) /* 只允许在进程允许运行的CPU所关联的结点分配内存 */
#define __GFP_THISNODE ((__force gfp_t)0x40000u) /* 没有备用结点,没有策略 */
#define __GFP_RECLAIMABLE ((__force gfp_t)0x80000u) /* 页是可回收的 */
#define __GFP_MOVABLE ((__force gfp_t)0x100000u) /* 页是可移动的 */
// 一些简写
#define GFP_ATOMIC (__GFP_HIGH)
#define GFP_NOIO (__GFP_WAIT)
#define GFP_NOFS (__GFP_WAIT | __GFP_IO)
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL | __GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL | __GFP_HIGHMEM | __GFP_MOVABLE)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
动态映射
上面已经提到,若连续的物理页不够时,将使用vmalloc区域建立映射,它将连续的线性地址映射到任意物理地址,常见的函数如下:
// 分配指定大小的线性区
void *vmalloc(unsigned long size);
//
void __vunmap(void *addr, int deallocate_pages);
此时可能会需要将页帧转换为线性地址,由于不再属于直接映射,因此不能直接使用线性加减获取,而必须使用其他方式,其实现如下:
// 若page属于普通区则线性计算即可,否则需要查询page_address_htable获取
void * page_address( struct page * page)
{
unsigned long flags;
void * ret;
struct page_address_slot * pas;
if ( ! PageHighMem( page) )
return lowmem_page_address( page) ;
pas = page_slot( page) ;
ret = NULL ;
spin_lock_irqsave( & pas- > lock, flags) ;
if ( ! list_empty( & pas- > lh) ) {
struct page_address_map * pam;
list_for_each_entry( pam, & pas- > lh, list ) {
if ( pam- > page = = page) {
ret = pam- > virtual ;
goto done;
}
}
}
done:
spin_unlock_irqrestore( & pas- > lock, flags) ;
return ret;
}
// 所有页都会有如下结构存放页帧到虚拟地址间的关系
struct page_address_map {
struct page *page;
void *virtual;
struct list_head list;
};
持久映射
若要将高端页帧长期映射到内核地址空间,应使用持久映射区:
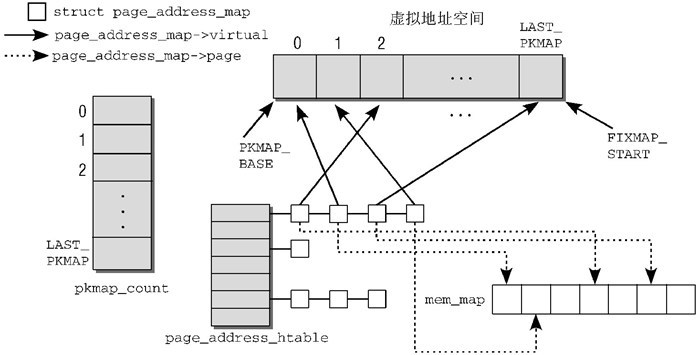
所谓映射就是输入页帧号,返回虚拟地址:
// 为页创建映射,若页属于普通内存则直接返回地址,若为高端内存则需要在持久映射区寻找可用地址并建立映射
static inline void *kmap(struct page *page);
固定映射
在最顶端有一片区域用于建立固定映射,也用于临时映射,此时每CPU会占用一片地址区,此时可使用如下函数:
// 该函数会确保映射成功
void *kmap_atomic(struct page *page, enum km_type type);
Slab
同类的还有slob/slub,它们都是基于伙伴系统的内存分配,它的作用类似于libc里的内存库,上面已知伙伴系统一次只能分配一整个页面,slab就是将其再划分为小块内存以满足程序实际需要,并且通过缓存加速分配。
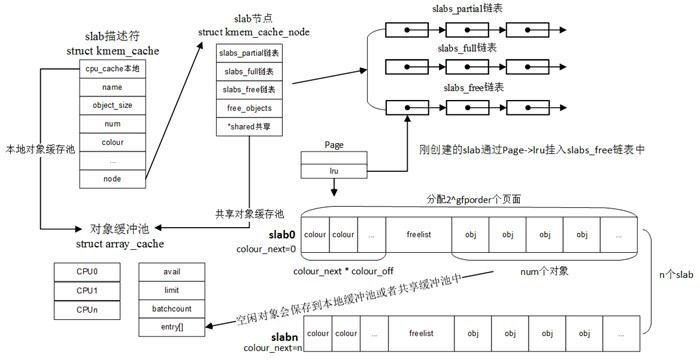 其常见的函数如下:
其常见的函数如下:
void *kmalloc(size_t size, gfp_t flags);
void kfree(const void *objp);
void *kzalloc(size_t size, gfp_t flags);
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *));
void kmem_cache_destroy(struct kmem_cache *cachep);
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
void *kmem_cache_zalloc(struct kmem_cache *cachep, gfp_t flags);
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
抛开每CPU缓存,它可分为三级,它最下层为对象,一个对象就是最小内存分配单元,分配后用于存储特定结构的数据,比如struct dentry/struct inode等,其上层是slab,它是一组从伙伴系统分配的物理连续的内存地址,被分为一个或多个对象,kmem_cache在最上层,它管理着多个slab,所以它也管理着一组相同大小的对象,内核中有多个kmem_cache,它们都拥有属于自己的名字,每个用于特定对象的内存分配,比如task_struct_cachep管理task_struct对象,例外是kmalloc-xx管理着用于通用内存分配的对象,即在使用kmalloc等函数分配时,会从这里分配,而其他都是调用kmem_cache_alloc来指定cache的。
Task VMA
Linux进程和线程(轻量级进程,包括内核线程)一致,都使用task_struct表示其结构,其上的内存描述mm_struct* mm及active_mm用记录任务的虚拟内存区域,由于这里面的区段都是表示线性地址空间的区段,书上也把它叫做线性区,其每个区段用vm_area_struct结构表示,该结构由链表与红黑树连接方便遍历与查改:
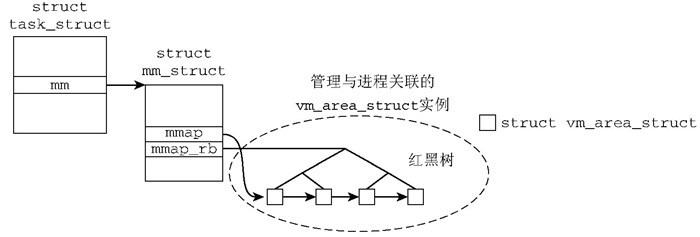
这里细节仍然很多之后可能会介绍,此处只说明相关函数:
// 查找最邻近addr的线性区,它根据区域的vm_end字段来查找,最终addr可能不属于找到的区段,此时表示addr所在区域未映射
struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr)
// 查找与给定地址区间重叠的线性区,存在时start_addr可能不在线性区,但end_addr一定要大于线性区起始地址
static inline
struct vm_area_struct * find_vma_intersection(struct mm_struct * mm,
unsigned long start_addr,
unsigned long end_addr)
// 查找空闲的线性区,该区域没有和已存在的线性区重叠
unsigned long
get_unmapped_area(struct file *file, unsigned long addr,
unsigned long len, unsigned long pgoff, unsigned long flags)
// 将线性区插入mm
int insert_vm_struct(struct mm_struct *mm, struct vm_area_struct *vma)
虚拟连续的内存分配使用如下函数:
void *vmalloc(unsigned long size);
void vfree(const void *addr);
void *vzalloc(unsigned long size);
void *vmap(struct page **pages, unsigned int count, unsigned long flags, pgprot_t prot);
注意虚拟地址和进程相关,所以由每进程维护一个结构记录即可。
每CPU分配器
这是一个特殊的区域,当使用DEFINE_PER_CPU时,将会把变量放入名为".data..percpu"的节区:
#define DEFINE_PER_CPU(type, name) DEFINE_PER_CPU_SECTION(type, name, "")
类似TLS,系统启动时会根据逻辑CPU数对其进行复制,从而让每个CPU都有个对应的副本,于是访问该区域就不必加锁,访问可通过per_cpu宏进行:
#define per_cpu(var, cpu) (*per_cpu_ptr(&(var), cpu))
它的内存视图如下:
c0 c1 c2
------------------- ------------------- ------------
| u0 | u1 | u2 | u3 | | u0 | u1 | u2 | u3 | | u0 | u1 | u
------------------- ...... ------------------- .... ------------
既然叫分配器,除了静态分配,每CPU当然还可以动态分配,其使用__alloc_percpu实现:
void __percpu *__alloc_percpu(size_t size, size_t align)
因此每个区域布局如下:
*
* <Static | [Reserved] | Dynamic>
*
参考
- Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C & 3D): System Programming Guide
- 深入理解LINUX内核(第三版) -- BOVET&CESATI[著];陈丽君 张琼声 张宏伟[译]
- 深入理解Linux内核架构 -- Mauerer[著];郭旭[译]
- 奔跑吧Linux内核 -- 张天飞[著]
- linux内核源码分析 -- JeanLeo
- 理解Linux内存管理 -- CHENG Jian
- Linux内存都去哪了:(1)分析memblock在启动过程中对内存的影响 -- arnoldlu
- Linux内存管理 -- LoyenWang
- Linux 内核揭秘 -- 0xAX
- 【我所認知的BIOS】-->MTRR (MEMORY TYPE RANGE REGISTERS) -- 小王haha