年龄大了这些笔记当时不记过一段时间就忘了,所以现在先慢慢记吧,每天记一点...
前言
当今设备基本都会提供WEB UI作为功能入口,可能会在该接口上再引导安装特定客户端,但WEB服务总是会对外开放,该服务根据设备和服务特点而变化,可能就是最基本的CGI或自己实现的服务,或嵌入式里有名的GoAhead/Boa/Appweb/lighthttpd,而功能更强大的设备通常会使用Apache Httpd或Nginx作为服务容器,nginx由于异步机制性能远优于apache,而且openresty等扩展为其添加了动态的能力,当前正逐渐取代httpd,但因历史原因apache依然在设备里占了大多数,本文主要介绍对基于Apache httpd的服务漏洞挖掘。
经常说的Apache Web服务器是指Apache httpd尽管从历史上它就该叫apache,但是现在apache项目太多了,不过本文为了方便还是用apache表示apache httpd。在网络设备中很多产品都会基于apache进行开发,当前主流的版本是2.4,历史原因让1.3依然可见于一些“有底蕴”的设备,这两个版本架构变化很大但基本处理流程类似,本文会穿介绍这两个版本。此处先简单介绍下其主要区别:
| apache 1.3 | apache2.0+ | |
|---|---|---|
| 平台抽象 | 只使用了ap_这个命名空间,没有把平台相关代码抽象 | 将这部分的提出为单独的apr,从而在上层可编写平台无关的代码 |
| 并发 | 只有原始的多进程处理 | 引入了MPM支持Prefork/Event等多种方式 |
| 钩子 | 各功能耦合高,提供的Hook点较少且固定,为了添加如SSL支持的扩展必须对其打补丁 | 提供了更多都Hook点,用户也可以自己添加Hook点 |
架构流程分析
编译与调试
在分析其他开源组件扩展,如apache模块时,可以先编译带符号版再使用ida导出符号,此时首先获取需要的版本信息,对于2.0之后的版本需要关注它如下部分:
/ # httpd -V
Server version: Apache/2.4.41 (Unix) # 主体版本
Server built: Jul 14 2021 21:07:58
Server's Module Magic Number: 20120211:88
Server loaded: APR 1.7.0, APR-UTIL 1.6.1
Compiled using: APR 1.7.0, APR-UTIL 1.6.1 # APR和APU版本
/ # httpsd -l
core.c
mod_so.c
http_core.c
prefork.c # 使用的mpm模块
mod_ssl.c
mod_reqtimeout.c
注:mpm是多处理模块,决定了并发模型,会直接影响到调试,可参见apache mpm
编译2.4
从上获知版本后,就可以下载相应版本的文件进行编译,编译方式如下:
DST_DIR=/usr/myapache
## 安装依赖,如下...etc
## apt install libexpat-dev libpcre3-dev
# 编译expat
wget https://github.com/libexpat/libexpat/releases/download/R_2_2_10/expat-2.2.10.tar.gz
tar xf expat-2.2.10.tar.gz && cd expat-2.2.10/
./configure --host=x86_64-linux31-linux-gnu CFLAGS='-g' --prefix=$DST_DIR
make && make install
# 编译pcre
wget https://sourceforge.net/projects/pcre/files/pcre/8.44/pcre-8.44.tar.gz
tar xf pcre-8.44.tar.gz && cd pcre-8.44/
./configure --host=x86_64-linux31-linux-gnu CFLAGS='-g' --prefix=$DST_DIR
make && make install
# 编译apr
wget https://dlcdn.apache.org/apr/apr-1.7.0.tar.gz
tar xf apr-1.7.0.tar.gz && cd apr-1.7.0
./configure --host=x86_64-linux31-linux-gnu CFLAGS='-g' --prefix=$DST_DIR
make && make install
# 编译apr-util
wget https://dlcdn.apache.org/apr/apr-util-1.6.1.tar.gz
tar xf apr-util-1.6.1.tar.gz && cd apr-util-1.6.1
./configure --host=x86_64-linux31-linux-gnu CFLAGS='-g' --prefix=$DST_DIR --with-apr=$DST_DIR --with-expat=$DST_DIR
make && make install
# 编译httpd,注由于上面的prefork是默认的所以此处未指定,否则需要指定对应的mpm模块
wget https://archive.apache.org/dist/httpd/httpd-2.4.41.tar.gz
tar xf httpd-2.4.41.tar.gz && cd httpd-2.4.41
./configure --host=x86_64-linux31-linux-gnu CFLAGS='-g' --with-apr=$DST_DIR --with-apr-util=$DST_DIR --prefix=$DST_DIR --with-pcre=$DST_DIR --enable-static-support
make && make install
编译1.3
apache1与apache2结构差别较大,它没有单独的APR,可使用如下方式编译:
# 选择需要的版本:https://archive.apache.org/dist/httpd/ ,如1.3.27
wget https://archive.apache.org/dist/httpd/apache_1.3.27.tar.gz
tar xf apache_1.3.27.tar.gz
cd apache_1.3.27/src
cp Configuration.tmpl Configuration
# 编辑Configuration,在CFLAGS下添加-g,其他按需修改
./Configure
make
可能出现报ap_os_is_path_absolute重复定义的错误,没研究原因,修改os/unix/os-inline.c如下:
static INLINE int ap_os_is_path_absolute(const char *file)
{
return file[0] == '/';
}
再修改os/unix/os.h,将其include进去,蟒就是了!若需要编译mod_ssl模块,方法如下:
# 下载对应版本的mod_ssl,在Apache1上需要通过打补丁的方式hook,因此版本需对应
wget http://www.modssl.org/source/OBSOLETE/mod_ssl-2.8.13-1.3.27.tar.gz
# 安装依赖,需注意openssl需要1.0以下,否则需要做很多修改
apt install libgdbm-compat-dev libssl-dev
# 打补丁
tar xf mod_ssl-2.8.13-1.3.27.tar.gz && cd mod_ssl-2.8.13-1.3.27/
./configure --with-apache=/root/apache_1.3.27
# 修改上面的那个Configuration,添加如下内容
SSL_BASE=SYSTEM
Rule SSL_COMPAT=yes
Rule SSL_SDBM=default
Rule SSL_EXPERIMENTAL=no
Rule SSL_CONSERVATIVE=no
Rule SSL_VENDOR=no
Rule EAPI=yes
AddModule modules/ssl/mod_ssl.o
# 重新生成Makefile
./Configure
# 修改module/ssl/Makefile
# 将LIB=libssl.$(LIBEXT)改为libssl.a
# 重新编译
make
注:apache早期还有apache-ssl这个模块提供ssl功能,该模块可通过archive获取!
编译完成后,可制作类库与指纹,这是分析的第一步!!制作方法此处详见《IDA Pro使用技巧》:
附:在apple silicon上使用clion调试时,使用makefile方式打开,编译出错可见文档进行修复。
调试
使用--enable-debugger-mode激活调试,它主要是添加-g和-O0选项,生成的二进制可用gdb直接调试,启动时指定-X参数可单线程便于调试,但有源码还是ide里更方便,以clion为例直接创建一个Makefile Application调试配置即可。
APR
从2.0开始为了可移植性,Apache开发了一套中间层APR(Apache Portable Runtime)来屏蔽底层的差异,它提供了一些常用的数据结构,进程/内存/文件等操作API,另外提供了APU,它是在APR基础上开发的一些实用工具接口,而Apache HTTPD就是基于它们开发的,所以在逆向httpd相关二进制文件时,一定要先弄清楚apr里的一些内容。
pool
首先是资源池,比如C语言本身不提供内存的垃圾收集,需要用户自己管理分配与释放,这很容易造成内存泄漏或DoubleFree等问题,还有有些其它的资源如文件句柄等也需要使用完释放,APR使用资源池作为资源管理基础,一个pool可以创建subpool,在一个过程中所有资源通过该subpool申请,被subpool管理,在过程结束时销毁subpool就可以统一收回subpool上分配的所有资源。在apache中会有大量函数会以pool作为参数,知道这回事就行:
void* apr_palloc(apr_pool_t *p, apr_size_t size);
char* apr_psprintf(apr_pool_t *p,const char *fmt, ...);
char* apr_pstrcat(apr_pool_t *p, ...);
data structure
比较常见的就是array/table/hashtable/ring。
bucket与brigade
这个结构特别重要,它贯穿过滤器的始终,简单的说过滤器很可能需要对一个字符串进行大量的替换/插入/删除等操作,对此最直观的实现方式就是在每次操作前先算出操作后所需内存,申请一片新空间后进行内存拷贝操作,但这无疑是低效的。bucket就是用于解决,最常见的bucket是内存型bucket,它在开始时是原始的内存数据,要对数据进行操作时它会从操作的那个点处开始分裂成两个部分,形成链表,之后随着操作次数的增多这个链表上的块也会慢慢变多,apache把这里的一组bucket叫做brigade并用相应的数据结构进行管理,实际上这里的链表就是个ring。除了最直观的内存型bucket外还有很多其他类型的bucket,如输入过滤器的最原始输入其实是socket,于是可以把它封装成socket型bucket,但由于它们都会实现同样的函数,因此使用时直接使用bucket这一个抽象而不必关注其具体是什么类型。 除了可存储内容的bucket外还有的bucket仅用于存储元数据,如Flush型bucket表示过滤器在读到此bucket时就可以先把数据传递给下一个过滤器,而EOS型bucket表示已经读到最后一个bucket,过滤器将不必再继续向后读。
Module
apache支持通过模块扩展其功能,模块可以被静态链接到apache主体,也可以作为动态链接库在程序启动时按需加载,apache核心提供了一些Hook点与Filter点,模块可以通过这些点修改核心的行为,也可以实现一个handler为请求生成响应数据,在编写模块时需要导出一个module结构,它里面会记录很多模块信息,我们在分析一个模块时也以它作为入口点,在1.3上它的结构如下:
typedef struct module_struct {
int version; /* API版本,用于指示与core的兼容性 */
int minor_version; /* API的小版本,仅用于表示一些feature,在初始化时会忽略它 */
int module_index; /* 模块索引,在加载后会被初始化,用于索引配置 */
const char *name; /* 模块的文件名,在分析时通过该名称可猜测模块作用,特别是静态链接时 */
void *dynamic_load_handle; /* 模块的句柄,如dlopen的返回值 */
struct module_struct *next; /* 链接到下一个模块,初始化后有效,所有模块会以链表形式组合在一起 */
unsigned long magic; /* 模块的魔数,通过它可以将模块分为不同类,并在之后按分类调用 */
void (*init) (server_rec *, pool *); /* 初始化代码,在配置解析后被执行 */
void *(*create_dir_config) (pool *p, char *dir); /* 创建每目录配置 */
void *(*merge_dir_config) (pool *p, void *base_conf, void *new_conf); /* 合并每目录配置 */
void *(*create_server_config) (pool *p, server_rec *s); /* 创建每服务配置 */
void *(*merge_server_config) (pool *p, void *base_conf, void *new_conf); /* 合并每服务配置 */
const command_rec *cmds; /* 指令列表,里面指示了支持的指令,指令说明,解析函数 */
const handler_rec *handlers; /* 生成器列表,里面指示了声明的生成器名称与对应的执行函数 */
int (*translate_handler) (request_rec *); /* 转换URI到文件名 */
int (*ap_check_user_id) (request_rec *); /* 从http请求里获取用户ID并检查 */
int (*auth_checker) (request_rec *); /* 检查授权 */
int (*access_checker) (request_rec *); /* 通过主机地址等进行一些基本检查 */
int (*type_checker) (request_rec *); /* 探测请求的MINE并设置content-type等,也可能会设置handler,如mod_mime就是在此处实现SetHandler的 */
int (*fixer_upper) (request_rec *); /* 请求被处理前的最后步骤,想做的其他事都可以在这里完成 */
int (*logger) (request_rec *); /* 记录事务 */
int (*header_parser) (request_rec *); /* 解析请求头 */
void (*child_init) (server_rec *, pool *); /* 在新进程(不含轻量级进程)创建后执行 */
void (*child_exit) (server_rec *, pool *);
int (*post_read_request) (request_rec *); /* 在普通请求和内部重定向请求(不包含子请求)被读取后执行 */
#ifdef APACHE_SSL
/* 剩下的部分是原始结构没有的,若提供的钩子不能满足需求就可以扩展该结构新增钩子与回调点 */
void (*setup_connection)(conn_rec *); /* apache-ssl的钩子,用于在连接建立时封装 */
void (*add_common_vars)(request_rec *);
#endif
} module;
在2.0之后它的结构如下:
struct module_struct {
int version;
int minor_version;
int module_index;
const char *name;
void *dynamic_load_handle;
struct module_struct *next;
unsigned long magic;
void (*rewrite_args) (process_rec *process); /* 这是个特殊的hook,用于mpm重写命令行参数,它会在很早前被调用,若以单独放这里 */
void *(*create_dir_config) (apr_pool_t *p, char *dir);
void *(*merge_dir_config) (apr_pool_t *p, void *base_conf, void *new_conf);
void *(*create_server_config) (apr_pool_t *p, server_rec *s);
void *(*merge_server_config) (apr_pool_t *p, void *base_conf,
void *new_conf);
const command_rec *cmds;
void (*register_hooks) (apr_pool_t *p); // 主要的钩子和过滤器都由它注册
int flags;
};
如上可见,2.0相对于1.3module里包含的信息,其实是函数指针变少了,实际上1.3里的所有Hook点都需要在这个module里指定实现的函数指针,因此若需要新增Hook点也需要对该结构打补丁,在其尾部追加域,而在2.0之后的版本中可见它只剩一个函数register_hooks了,若要实现Hook等功能只需要在该函数内实现! magic搜索 可使用apxs编译模块,它能在源码树外生成模板与编译脚本辅助编译过程,
定位静态链接模块
静态模块隐藏在整个二进制文件中,不能直接通过导出符号定位,但也有很多方法可以获取:
- 可通过版本号/模块文件名/魔数等关键常量定位到module结构
- 定位核心模块的module结构,再由它的交叉引用获取prelinked_modules/preloaded_modules数组,这个数组里会有所有静态链入的modules信息(注:prelinked表示静态链接且默认激活,preloaded表示静态链接,但需要使用AddModule指令激活,不过在2.0之后它们一致)
- 可通过
ap_setup_prelinked_modules去获取链接的列表,该函数会在main的前面被调用
HOOK
apache在core里面埋了很多hook点,用户可以自己实现对应点的钩子函数,并把它挂钩上去,此处1.3和2.0存在较大差别,1.3是遍历module这个结构,查看函数是否非空,非空则执行,而2.0之后需要手动挂钩;在用户新增自己的hook点时,1.3是直接改代码和module机构,而在2.0后需要用它提供的宏进行一系列的声明,但目前为止我还没遇到这种情况,因此暂时只关注使用已有的hook点。
hook in 1.3
如mod_proxy,它在1.3里通过此方法注册:
// 在module里注册了三个钩子函数
module MODULE_VAR_EXPORT proxy_module =
{
STANDARD_MODULE_STUFF, /* 填充前几位的宏,标准模块直接调用它,非标准模块,如对该结构进行了扩充需要修改magic时可直接填充 */
.....
proxy_trans, /* translate_handler */
NULL, /* check_user_id */
NULL, /* check auth */
NULL, /* check access */
NULL, /* type_checker */
proxy_fixup, /* pre-run fixups */
NULL, /* logger */
NULL, /* header parser */
NULL, /* child_init */
NULL, /* child_exit */
proxy_detect /* post read-request */
};
注册后,在core里被调用:
// 在core的process_request_internal里会调用ap_translate_name/ap_run_fixups等钩子函数
static void process_request_internal(request_rec *r)
{
...
if ((access_status = ap_translate_name(r))) {
decl_die(access_status, "translate", r);
return;
}
...
if ((access_status = ap_run_fixups(r)) != 0) {
ap_die(access_status, r);
return;
}
...
}
再看它调用时的实现,这类函数的实现类似,如ap_run_fixups,一般都调用run_method,第二个参数指定钩子函数在模块中的偏移:
API_EXPORT(int) ap_run_fixups(request_rec *r)
{
return run_method(r, offsets_into_method_ptrs.fixer_upper, 1);
}
如下,它会遍历所有模块,若模块对应偏移处非空,则说明实现了钩子,则调用它
static int run_method(request_rec *r, int offset, int run_all)
{
int i;
for (i = offset; method_ptrs[i]; ++i) {
handler_func mod_handler = method_ptrs[i];
if (mod_handler) {
int result;
result = (*mod_handler) (r);
if (result != DECLINED && (!run_all || result != OK))
return result;
}
}
return run_all ? OK : DECLINED;
}
hook in 2.0+
依然以mod_proxy为例,在2.4下它的注册方式如下:
AP_DECLARE_MODULE(proxy) =
{
STANDARD20_MODULE_STUFF,
...
register_hooks
};
这里主要看register_hooks,它再mod_proxy里的实现如下:
static void register_hooks(apr_pool_t *p)
{
static const char * const aszSucc[] = { "mod_rewrite.c", NULL};
static const char *const aszPred[] = { "mpm_winnt.c", "mod_proxy_balancer.c",
"mod_proxy_hcheck.c", NULL};
/* handler */
ap_hook_handler(proxy_handler, NULL, NULL, APR_HOOK_FIRST);
/* filename-to-URI translation */
ap_hook_translate_name(proxy_trans, aszSucc, NULL, APR_HOOK_FIRST);
/* walk <Proxy > entries and suppress default TRACE behavior */
ap_hook_map_to_storage(proxy_map_location, NULL,NULL, APR_HOOK_FIRST);
/* fixups */
ap_hook_fixups(proxy_fixup, NULL, aszSucc, APR_HOOK_FIRST);
...
}
这里它注册了很多的钩子,由于新增hook时用了宏,在2.0后钩子的注册函数和运行函数有了清晰的前缀,如下:
ap_hook_<hookname> // 用于注册(挂钩)勾子
ap_run_<hookname> // 用于调用勾子
回到register_hooks,可见它的注册方式更加灵活,不仅注册了实现函数,还能定义它的前置执行模块和后置执行模块,并且能定义执行顺序,这里有定义了5个顺序,用户可以自定义更精细的顺序:
#define APR_HOOK_REALLY_FIRST (-10)
#define APR_HOOK_FIRST 0
#define APR_HOOK_MIDDLE 10
#define APR_HOOK_LAST 20
#define APR_HOOK_REALLY_LAST 30
注:可以直接通过调试的方法判断hook的执行顺序。
注册时,会把它添加到一个一个链表里,这个链表也是在定义钩子时宏定义的,如ap_hook_fixups:
void ap_hook_fixups(ap_HOOK_fixups_t *pf_0, const char *const *aszPre, const char *const *aszSucc, int nOrder)
{
ap_LINK_fixups_t_0 *pHook;
if ( !hooks_3.link_fixups )
{
hooks_3.link_fixups = (apr_array_header_t_0 *)apr_array_make(apr_hook_global_pool, 1LL, 40LL);
apr_hook_sort_register();
}
pHook = (ap_LINK_fixups_t_0 *)apr_array_push(hooks_3.link_fixups);
pHook->pFunc = pf_0;
pHook->aszPredecessors = aszPre;
pHook->aszSuccessors = aszSucc;
pHook->nOrder = nOrder;
pHook->szName = (const char *)apr_hook_debug_current;
if ( apr_hook_debug_enabled )
apr_hook_debug_show();
}
注册后,它的调用也是朴实无华:
int __cdecl ap_run_fixups(request_rec_0 *r)
{
char *pHook; // [rsp+10h] [rbp-10h]
int rv; // [rsp+18h] [rbp-8h]
int n; // [rsp+1Ch] [rbp-4h]
rv = 0;
if ( !hooks_3.link_fixups )
return rv;
pHook = hooks_3.link_fixups->elts;
for ( n = 0; n < hooks_3.link_fixups->nelts; ++n )
{
rv = (*(__int64 (__fastcall **)(request_rec_0 *))&pHook[40 * n])(r);
if ( rv )
{
if ( rv != -1 )
break;
}
rv = 0;
}
return rv;
}
注意从ap_run_fixups可以看出只要某个hook实现返回了非-1的值则终止,其实还有其他执行方式,如下:
#define OK 0 /** 该模块已经成功处理 */
#define DECLINED -1 /** 不能处理,由其他模块继续处理 */
#define DONE -2 /** 该hook已经做完了,不必再继续执行其他hook */
// 无论如何执行所有hook
#define AP_IMPLEMENT_HOOK_VOID(name,args_decl,args_use) ...
// 执行所有hook,若过程中出现错误则停止(ret!=ok&&ret!=decline)
#define AP_IMPLEMENT_HOOK_RUN_ALL(ret,name,args_decl,args_use,ok,decline) ...
// 执行到第一个成功或发生错误时停止(ret!=decline)
#define AP_IMPLEMENT_HOOK_RUN_FIRST(ret,name,args_decl,args_use,decline) ...
因此需要看ap_run_HOOK确认它的类型。
技巧
hook是重点分析的位置,若是动态加载的模块直接打开就能看到module信息,若是静态链接的模块则需要先定位到它的位置,从而获取钩子信息,有符号通过符号ap_run/ap_hook前缀能找到注册与调用信息,由于注册点容易定位,因此无符号通过动态调试时在钩子里打断点获取调用位置,在2.0后也可以通过链表的交叉引用获取调用点。
注:调试时首先看看apache工作模式,并且把它的并发调为1(或使用-X以调试模式启动)便于调试。
Filter
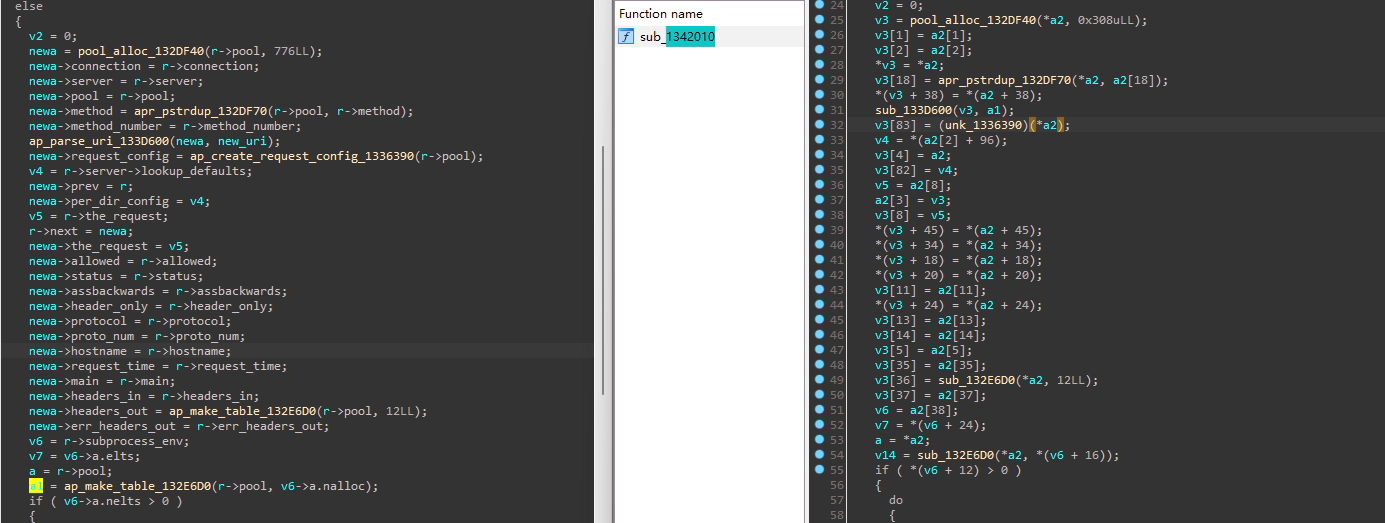
Filter是2.0后才有的,相对于Hook,Filter出现的相对少一点,过滤器就注意两点,一个bucket与brigade作用与filter的作用流程,前者已经提了这里说说后者,apache核心有两条过滤去链,分别链接输入过滤器与输出过滤器:
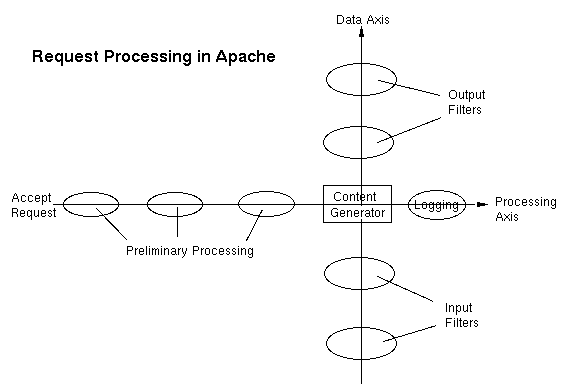
上图可见过滤器是以内容生成器为中心的,它的另一端连接服务输出(如网络),过滤器链表示多个过滤器连着依次被调用,输出过滤器链的方向是从内容生成器到输出端这毫无疑问,而输入过滤器链也是从内容生成器开始到输入端,从动作上前者是push而后者是pull!在读取输入时,在ap_read_request中会创建一个空的brigade并传递给最后一个输入过滤器,接着从输入过滤器读取数据时,输入过滤器会将brigade再次传给上一个过滤器,并读取与修改数据,直到最接近请求的那个输入过滤器(当前是CORE_IN),它直接从流里读数据,以ap_rgetline_core为例,它用于读取一行数据:
AP_DECLARE(apr_status_t) ap_rgetline_core(char **s, apr_size_t n,
apr_size_t *read, request_rec *r,
int flags, apr_bucket_brigade *bb)
{
do {
// 让下一个过滤器填充bb
apr_brigade_cleanup(bb);
rv = ap_get_brigade(r->proto_input_filters, bb, AP_MODE_GETLINE,
APR_BLOCK_READ, 0);
// 遍历brigade里的每一个bucket并处理
for (e = APR_BRIGADE_FIRST(bb); e != APR_BRIGADE_SENTINEL(bb); e = APR_BUCKET_NEXT(e))
{
if (APR_BUCKET_IS_EOS(e)) { saw_eos = 1; break; } // 若是EOS则不再继续了
rv = apr_bucket_read(e, &str, &len, APR_BLOCK_READ); // 从bucket读数据
// 处理数据
...
}
} while (!saw_eol);
}
AP_DECLARE(apr_status_t) ap_get_brigade(...)
{
// 从下一个过滤器中获取数据
return next->frec->filter_func.in_func(next, bb, mode, block, readbytes);
}
过滤器根据作用的阶段可分为三类:
这点了解即可,对我们分析来说,只需知道过滤器的使用分两步:注册过滤器(可省略)与添加过滤器,注册只会发生一次,用于按名字把过滤器注册到全局的树结构中,添加过滤器用于将过滤器与特定的请求或连接相关联,此时它才会在一次请求或连接中生效,注意添加时它会按照它的类型插入恰当的位置:
// 注册输入/输出过滤器
AP_DECLARE(ap_filter_rec_t *) ap_register_input_filter(const char *name, ap_in_filter_func filter_func, ap_init_filter_func filter_init, ap_filter_type ftype);
AP_DECLARE(ap_filter_rec_t *) ap_register_output_filter(const char *name, ap_out_filter_func filter_func, ap_init_filter_func filter_init, ap_filter_type ftype);
AP_DECLARE(ap_filter_rec_t *) ap_register_output_filter_protocol(const char *name, ap_out_filter_func filter_func, ap_init_filter_func filter_init, ap_filter_type ftype, unsigned int proto_flags);
// 依据名称添加输入/输出过滤器
AP_DECLARE(ap_filter_t *) ap_add_input_filter(const char *name, void *ctx, request_rec *r, conn_rec *c);
AP_DECLARE(ap_filter_t *) ap_add_output_filter(const char *name, void *ctx, request_rec *r, conn_rec *c);
// 直接添加输入/输出过滤器
AP_DECLARE(ap_filter_t *) ap_add_input_filter_handle(ap_filter_rec_t *f, void *ctx, request_rec *r, conn_rec *c);
AP_DECLARE(ap_filter_t *) ap_add_output_filter_handle(ap_filter_rec_t *f, void *ctx, request_rec *r, conn_rec *c);
因此若遇到在某处添加了过滤器,就能定位到它的实现,上面已经提到输入过滤器的主要逻辑,再提下输出过滤器,它的逻辑为:
AP_CORE_DECLARE_NONSTD(apr_status_t) ap_content_length_filter(ap_filter_t *f, apr_bucket_brigade *b)
{
// 获取ctx,一般过滤器都会有这步,因为一个请求/连接中可能会多次调用输入/数次,此时可通过ctx记录一些状态
if (!f->ctx) {
// 表明是第一次调用
f->ctx = ctx = apr_palloc(r->pool, sizeof(*ctx));
ctx->data_sent = 0;
ctx->tmpbb = apr_brigade_create(r->pool, r->connection->bucket_alloc);
}
// 开始处理数据
e = APR_BRIGADE_FIRST(b);
while (e != APR_BRIGADE_SENTINEL(b)) {
// 各种处理操作,这里面可能也会调用ap_pass_brigade将部分数据传给下个过滤器,也可能先直接返回
}
// 将数据传给下一个过滤器
return ap_pass_brigade(f->next, b);
}
除此之外2.0后的mod_filter模块还引入了智能过滤器的概念,可以更灵活的执行过滤器操作,不过我是真没遇到过就不细说了,了解即可:
Handler
handler用于生成响应,其功能很直观,直接分析即可。
Config
从module结构体里可见有四个与配置相关的函数,一般模块的配置很简单,直接配合cmds就可以看懂,可能在hook/filter等处会使用到模块的config,它有dir和server两种config都是在初始化时就被解析并存入全局空间,使用模块id索引:
core_server_config *conf = r->server->module_config[core_module.module_index];
core_dir_config *conf = r->per_dir_config[core_module.module_index];
若确实需要分析它的结构可从create函数和cmds里的函数分析。
Core
一般只需要分析模块就好了,但是有时这些厂商会对apche进行深度定制,这时就需要分析它的core了。
三大结构体
apache有三个重要的结构体:conn_rec/request_rec/server_rec。它收到连接请求后会封装成conn_rec,从连接里读取数据可得到记录一个http请求的request_rec,http请求处理时将会根据host等信息选定server_rec,server_rec其实就是一个配置信息,连接和请求会根据收到的信息选择合适的server_rec从而获取正确的配置,其中一个conn_rec中可以读到多个request_rec,但它们都是短生命周期的,这里主要关注request_rec,它特别大,且不同版本可能有较大变化,这里只列出最常用的域,这部分变化较小:
struct request_rec {
apr_pool_t *pool; /** 请求的资源池,该请求里所有资源申请都应通过它完成,请求结束资源自动释放 */
conn_rec *connection; /** 请求的连接 */
server_rec *server; /** 请求对应的服务 */
request_rec *prev; /** 当该请求是内部重定向请求时,指向上一个请求 */
request_rec *main; /** 当这是子请求时,指向主请求 */
char *the_request; /** 请求的第一行 */
int proxyreq; /* 代理标志,如mod_proxy会在post_read里识别是否是代理请求,并设置该标志 */
int header_only; /** 这是个HEAD请求,只返回头部不返回body */
int proto_num; /** Protocol version number of protocol; 1.1 = 1001 */
char *protocol; /** Protocol string, as given to us, or HTTP/0.9 */
const char *hostname; /** 由Host头或URI设置 */
const char *status_line; /** Status line, if set by script */
int status; /** Status line */
int method_number; /** M_GET, M_POST, etc. */
const char *method; /** Request method (eg. GET, HEAD, POST, etc.) */
apr_int64_t allowed; /* 允许的请求,位向量 */
ap_method_list_t *allowed_methods; /** List of allowed methods */
apr_table_t *headers_in; /** 请求头 */
apr_table_t *headers_out; /** 响应头 */
apr_table_t *err_headers_out; /** 响应头,但是在出错或内部重定向时也可用 */
apr_table_t *subprocess_env; /** 子过程使用的环境变量 */
apr_table_t *notes; /** 一个表,叫笔记,各模块间可通过它传递数据 */
const char *content_type;
const char *handler; /* handler名称,最终会由该名称对应的handler生成响应 */
char *user; /** 若有认证,则存储用户名和认证类型 */
char *ap_auth_type;
char *unparsed_uri; /** 未执行任何解析的URI */
char *uri; /** URI的路径部分,若没有路径则为"/" */
char *filename; /** 这个响应对应的本地文件的文件名 */
char *canonical_filename; /* 真正在文件系统上的文件名,比如短文件名可访问,但实际文件名是长的 */
char *path_info; /** 从请求里提取的 PATH_INFO */
char *args; /** 从请求里提取的 QUERY_ARGS */
int eos_sent; /** A flag to determine if the eos bucket has been sent yet */
struct ap_conf_vector_t *per_dir_config; /** Options set in config files, etc. */
struct ap_conf_vector_t *request_config; /** Notes on *this* request */
struct ap_filter_t *output_filters; /** 该请求使用的输入输出过滤器 */
struct ap_filter_t *input_filters;
struct ap_filter_t *proto_output_filters; /** 协议级的输入输出过滤器 */
struct ap_filter_t *proto_input_filters;
apr_uri_t parsed_uri; /** 解析后的URI信息 */
apr_finfo_t finfo; /** 若请求的是文件且存在,此处为文件信息 */
};
其他概念
1.内部重定向:它是相对于外部重定向的,后者表示返回的响应头中含Location字段,使客户端重新请求指定的地址,而内部重定向表示在处理请求过程中,直接构造一个新的request_rec结构,重新走请求处理流程,在效果上尽管没有用户参与,但和用户直接发出的新请求处理流程一致。
2.子请求:在内部生成的请求,即创建一个新的request_rec,在内部执行请求。
3.记分板:主进程和工作进程间交换信息的一块共享内存,直接忽略它。
1.3的整体流程
1.3的流程特别简单,从main开始,它先做各种初始化,之后进入子进程:
int REALMAIN(int argc, char *argv[])
{
// 第一部分,各种初始化,解析配置,加载模块,监听端口等
common_init(); // 一些公共的初始化,如信号处理,资源池初始化
...
ap_cpystrn(ap_server_root, HTTPD_ROOT, sizeof(ap_server_root)); // 设置配置路径
ap_cpystrn(ap_server_confname, SERVER_CONFIG_FILE, sizeof(ap_server_confname));
ap_setup_prelinked_modules(); // 初始化静态链接的模块,将其加入运行时的链表
while ((c = getopt(argc, argv, "D:C:c:xXd:Ff:vVlLR:StTh")) != -1) {
switch (c) { // 处理命令行参数
case 'c':
new = (char **)ap_push_array(ap_server_post_read_config);
*new = ap_pstrdup(pcommands, optarg);
break;
...
}
}
ap_suexec_enabled = init_suexec();
server_conf = ap_read_config(pconf, ptrans, ap_server_confname);
if (ap_standalone) {}else {
ap_set_version();
ap_init_modules(pconf, server_conf);
ap_open_logs(server_conf, plog);
ap_init_modules(pconf, server_conf); // 此处模块被初始化了两次,因为解析配置后需要再次初始化信息
set_group_privs();
if (!geteuid() && setuid(ap_user_id) == -1) {}
server_conf->port = ntohs(((struct sockaddr_in *) &sa_server)->sin_port);
// 第二部分,建立连接并处理数据
conn = new_connection(ptrans, server_conf, cio,
(struct sockaddr_in *) &sa_client,
(struct sockaddr_in *) &sa_server, -1); // 封装连接
#ifdef APACHE_SSL
ap_setup_connection(conn); // 若是ssl需要对连接做额外的操作
#endif
while ((r = ap_read_request(conn)) != NULL) { // 从连接里获取一个请求,⚠️这里只读了请求头
ap_process_request(r); // 处理请求
if (!conn->keepalive || conn->aborted)break; // 若是keepalive型连接,循环读取并处理
}
}
}
如上可见除去一些初始化,就尾部那几个函数最重要,在分析时一般也是先定位这几个函数再继续。new_connection它的实现特别简单,就是新建并初始化conn_rec结构,而ap_read_request做的也很简单,从conn里读取数据并解析为request_rec结构,唯一要注意的是它内部有ap_run_post_read_request,若有模块实现了post_read_request会在此被执行。主要流程还是要跟入ap_process_request,其实现如下:
API_EXPORT(void) ap_process_request(request_rec *r)
{
...
process_request_internal(r);
}
static void process_request_internal(request_rec *r)
{
if (r->proxyreq == NOT_PROXY && r->parsed_uri.path) {
access_status = ap_unescape_url(r->parsed_uri.path); // url解码操作,如果是代理请求或请求结构的parsed_uri.path没有赋值则不处理
}
ap_getparents(r->uri); /* 该函数用于正规化path,即去掉../和./ */
if ((access_status = location_walk(r))) { } // 设置Location层级的配置
if ((access_status = ap_translate_name(r))) { } // 对URI进行转换,如alias/rewrite可在此处进行
...
if ((access_status = directory_walk(r))) { } // 设置Directory层级的配置
if ((access_status = file_walk(r))) { } // 设置File层级的配置
if ((access_status = location_walk(r))) { } // 再次调用,因为前面的转换可能会修改uri
if ((access_status = ap_header_parse(r))) { } // 解析头部,并可设置环境变量等
switch (ap_satisfies(r)) {
case SATISFY_ALL:
case SATISFY_NOSPEC:
if ((access_status = ap_check_access(r)) != 0) { } // 如检查IP/访问频率等
if (ap_some_auth_required(r)) {
// 检查用户是否存在,密码是否正确等
if (((access_status = ap_check_user_id(r)) != 0) || !ap_auth_type(r)) { }
// 检查用户是否有权限访问
if (((access_status = ap_check_auth(r)) != 0) || !ap_auth_type(r)) { }
}
break;
}
if (! (r->proxyreq != NOT_PROXY && r->parsed_uri.scheme != NULL && strcmp(r->parsed_uri.scheme, "http") == 0) ) {
if ((access_status = ap_find_types(r)) != 0) { } // 执行type_checker钩子,设置mime
}
if ((access_status = ap_run_fixups(r)) != 0) { } // 执行fixups钩子,最后其他的设置都可以扔这里哦
if ((access_status = ap_invoke_handler(r)) != 0) { } // 调用handler
ap_finalize_request_protocol(r);
}
整个过程如上,so easy!
2.4的整体流程
2.4的相对会复杂一些,整体上多了个MPM,细节上多了很多hook,但一般只需要从连接开始分析,它到连接的路径为main->ap_run_mpm->server_main_loop->startup_children->make_child->child_main->start_threads->worker_thread->process_socket->ap_run_process_connection,(注意此处省略了很多hook),通过ap_hook_process_connection可获取所有注册的hook,一般只有http模块会实现:
static int ap_process_http_connection(conn_rec *c)
{
// http的process_connection会根据mpm类型调用异步/同步处理函数
if (async_mpm && !c->clogging_input_filters) { }
else {
return ap_process_http_sync_connection(c); // 这里选择同步来分析
}
}
static int ap_process_http_sync_connection(conn_rec *c)
{
while ((r = ap_read_request(c)) != NULL) { // 从连接里读取一个请求
if (r->status == HTTP_OK) { ap_process_request(r); } // 处理单个请求
if (c->keepalive != AP_CONN_KEEPALIVE || c->aborted) break; // 若不是keepalive型的连接,则退出,否则循环读取连接
}
}
AP_DECLARE(void) ap_process_request(request_rec *r) -> void ap_process_async_request(request_rec *r)
{
access_status = ap_run_quick_handler(r, 0); /* Not a look-up request */
if (access_status == DECLINED) {
access_status = ap_process_request_internal(r); /* 处理request */
if (access_status == OK) {
access_status = ap_invoke_handler(r); /* 调用handler */
}
}
}
由上可见到三个重要的函数,下面分别分析。
ap_read_request
读一个请求,注意这里只读了请求头,之后根据解析的头部再读取请求体并处理或丢弃,此时若是未正确处理可能会造成类似请求走私的漏洞:
request_rec *ap_read_request(conn_rec *conn)
{
// 创建并初始化request,重点关注如下
apr_pool_create(&p, conn->pool); // 从连接的资源池创建子池作为请求的资源池
r = apr_pcalloc(p, sizeof(request_rec));
r->pool = p;
r->connection = conn;
r->server = conn->base_server; // 初始为默认服务
r->request_config = ap_create_request_config(r->pool);
r->proto_output_filters = conn->output_filters; // 这里的过滤器初始于连接,且协议与普通一致
r->output_filters = r->proto_output_filters;
r->proto_input_filters = conn->input_filters;
r->input_filters = r->proto_input_filters;
ap_run_create_request(r); // 运行create_request钩子,它可对request自定义与初始化
r->per_dir_config = r->server->lookup_defaults; // 每目录配置默认值
// 创建bragade用于传递给输入过滤器获取数据
tmp_bb = apr_brigade_create(r->pool, r->connection->bucket_alloc);
ap_run_pre_read_request(r, conn); // 运行pre_read_request钩子,在读请求前做些事情
if (!read_request_line(r, tmp_bb)) { } // 真正读请求
if (!r->assbackwards) { ap_get_mime_headers_core(r, tmp_bb); }
ap_update_vhost_from_headers(r); // 通过读到的请求头更新vhost
ap_add_input_filter_handle(ap_http_input_filter_handle, NULL, r, r->connection);
if (access_status != HTTP_OK || (access_status = ap_run_post_read_request(r))) { }
}
ap_process_request_internal
该函数和1.3类似,就不贴代码了。
ap_invoke_handler
它的实现就是设置handler名称并调用handler:
AP_CORE_DECLARE(int) ap_invoke_handler(request_rec *r)
{
...
ap_run_insert_filter(r);
// 执行输入输出过滤器的初始化,一般都不必实现初始化函数
result = invoke_filter_init(r, r->input_filters);
result = invoke_filter_init(r, r->output_filters);
// 若没有设置handler,则根据content-type设置,content-type之前已经设置过了
if (!r->handler) {
if (r->content_type) {
handler = r->content_type;
...
}
else {
handler = AP_DEFAULT_HANDLER_NAME;
}
r->handler = handler;
}
result = ap_run_handler(r); // 调用handler hook
...
}
此处可见最终调用的是handler hook,至此,整个流程分析完毕。
漏洞挖掘关注点
分析方式
netstat -pantu|grep -i listen # 获取监听的进程
ps aux |grep <httpd-pid> # 获取httpd的启动参数
httpd -V # 获取它的编译信息:版本,apr,模块,root目录,默认配置文件路径
grep -vE '(^\s*#)|(^$)' <httpd.conf> # 查看它的所有配置,关注用了哪些模块,有哪些路由等
grep -vE '(^\s*#)|(^$)' <extra/*> # 通常该目录下会有很多子配置...
解析特性
1.会处理hop-by-hop头,因此代理可能出现不一致
2.???
挖掘点
先说说对它的漏洞挖掘场景,有如下三种,本文主要针对后面两种情:
- 仅使用apache作为容器,使用CGI/Module等方式执行真正的服务代码
- 通过Module机制实现自己的功能
- 目标直接嵌入了整个Apache,并对其主体做了一些定制
关注点:
- 首选是配置文件,里面的点很多,如Location是网络指令,若多条Location指向了同样的位置,那么可能存在绕过,一般在做限制时应使用Directory/Files等指令;是否使用了变量,如host则用户可控;alias是否有/这是个经典的配置错误能穿一级目录;资源限制问题,防DoS;运行权限问题,如suExec,最小权限原则,文件目录权限应是www权限,需要注意server本身应该是www只读权限;用好网络位置与文件位置的校验,一般后者更有效
- 是否使用了一些奇怪的模块,如在漏洞挖掘时最讨厌看到modsecurity,但是更多的是小众的模块,它们可能本身有明显的漏洞,开源的可以直接去GitHub等位置找,可以看历史记录也可以去issue里搜什么segment之类的,搜open的没准可以拣0day
- 用的版本是否够高,当然是去找历史漏洞咯,这个一般不会有segment的issue
- 业务逻辑咯,这里面一般别碰apache本身的东西,要看自己引入的东西,分逻辑漏洞而经典漏洞,前者很多点,如产品里最好用的ssrf可重点看有没有proxy模块再看能不能控handler去指向它,而经典漏洞就是缓冲区溢出等,特别要注意strtok/crypt等不可重入造成的多线程模式下竞争条件
历史漏洞
先看看apache版本是2.2还是2.4,就可以查相应的列表看有没有洞,这里记录下近几年危害较大的洞:
-
CVE-2021-33193: H2的请求走私,2.4.17 到 2.4.48中启用了H2模块的受影响。
-
CVE-2021-41773/CVE-2021-42013:2.4.49和2.4.50受影响,利用该漏洞可实现目录穿越,如上级目录无权访问可穿越访问,或通过
cgi-bin目录去执行脚本(限制挺大的)。 -
CVE-2021-40438:2.4.48及以下版本在配置了proxy时可能受影响(漏洞点在
mod_proxy里但并不是所有的具体协议实现都受影响,详见p牛文章),利用该漏洞可实现SSRF,根据具体模块可打http/unixsocket/ajp等。 -
从右到左开始解析文件名,直到找到能解析的后缀。它使用handler标记请求处理程序,可使用
AddHandler和SetHandler指定扩展对应的handler,前者只要文件名中包含就会匹配(不是结尾才匹配),由于历史原因也可以尝试使用AddType替换AddHandler,可能效果一样。 -
CVE-2022-22720: 2.4.52之前的版本受影响,这是个经典的请求走私问题,即在出错时没有正确丢弃请求体与关闭连接。
-
CVE-2022-31813:2.4.53之前的版本受影响,这也是经典的hop-by-hop,利用它可以把
x-forwarded-*头给删掉,从而可能伪造IP地址等 -
CVE-2022-26377/ CVE-2022-36760: ajp的请求走私,2.4.53或54之前的版本受影响
-
CVE-2023-25690: 请求走私,2.4.55之前的版本中,
RewriteRule/ProxyPassMatch将匹配的数据再插入url则受影响 -
CVE-2023-27522: uwsgi的请求走私,2.4.30到2.4.55受影响