去年帮别人破解的一个程序,C++写的,第一次认真的分析C++的程序发现果然是那么痛苦,后来就着书把它啃出来了,记录了部分过程,现在整理笔记发现它,打算发出来水一期,然后...忘完了...所以想到啥写啥,以后遇到再补充吧...
CPP逆向基础
Question:C++面向对象编程的三个特点是什么?Answer:封装,继承,多态。
Question:它们是怎么实现的?Answer:...
一般提到C++与C的区别,都会想到一个面向对象一个面向过程,但是多看看C的代码,会发现它的结构体用法和C++的类特别像了,而且一些SDK同时提供C和C++版本,会发现在使用时,C仅仅是多了个一个结构体指针的参数,所以...它们很像嘛!
之前的《网络设备漏洞挖掘与代码审计》提到逆向的一个重点是结构体识别,并提了一些识别方法,那里主要针对C语言的二进制程序,对于C++对应起来就是类的识别了。
方法
事实上C++里的结构体可以认为是一种特殊类,一种没有方法且所有域都是public属性的类。再想类和对象实例,类的成员类似结构体,于是对象实例也就是结构体的所描述的值,而类的方法就比较特殊了,它不属于对象实例,是对象实例共用的一段代码。识别对象的重点就是这些方法的特征:
1.普通方法:它运行在对象实例上下文,它有个隐含的this指针,该指针作为第一个参数被编译器自动插入,代表着这个对象,在x86下一般用thiscall方式进行函数调用,它使用ECX寄存器传递this值,这个ECX就是方法识别的关键,而在x64下它退化成了通用的调用约定,如Windows下使用RCX传递,Linux下为RDI。
2.静态方法:它和普通方法类似但是不和对象实例绑定,即它不再有隐含的this参数,在二进制层面就难以区分它是否属于某个类了。
3.构造方法与析构方法:它们代表着对象的诞生与消亡,更精确的说是初始化与资源释放,它们被内存分配与回收包裹着。构造方法在存在时是对象执行的第一个方法(但是该方法可能被编译器优化为内联,于是不可见),在未定义构造方法时若存在虚表或基类有构造方法则编译器会添加默认构造方法,构造方法的第一个参数是新分配的供对象使用的空间的首地址(即this指针),它的返回也是该地址,在里面它会依次赋值虚函数表指针并调用基类构造函数,另外还有大量的赋值操作。而析构方法它只有一个参数,即对象指针,它会做和构造方法相反的基类析构与虚表赋值操作,它们在作用域成对出现,对象创建有如下情况:
- 全局对象:空间也在数据区,并在main函数执行前被初始化,如VC里被_cinit初始化,在此时它会在atexit里注册析构方法。
- 非静态局部对象:它的空间在栈上,在到函数内部被初始化,函数结束时调用析构方法。
- 堆对象:空间在堆上,使用new创建,delete时会调用析构方法。
- 实参:若是值传递,那么它会在栈上分配空间并使用拷贝构造函数创建对象的副本,并将地址传入被调函数。
- 返回值:作为函数的返回值时,不像其他语言动态申请空间,它在调用前就在栈上申请了空间用于存放返回值,一般来说函数的返回值会被在此赋值给一个变量,因此经常会出现在返回后,再次将这片区域复制到另一个区域。
构造函数与析构函数是类识别的重点,如通过上面的特征识别出一个函数是构造方法,那么调用它的所有位置都是该类的创建位置或派生类的构造函数内,因此可定位到虚表等信息,而创建位置又有对象的分配操作,如果是动态分配那么就可以知道对象的大小!
3.虚方法:它是多态的实现方式,C++本身是静态的语言,所有代码在编译时就决定了,比如一个调用一个对象的方法,这段机器指令在编译时就确定了,那如何在运行时根据对象的实际类型调用它自己的方法呢?就是把这类方法的地方放一张表里,并在对象里存放该表的指针,于是不同对象里指向的函数表不同,就可以实现多态特性,这类方法就是虚方法,在分析时也是比较恼人的方法,这类方法不是直接调用,而是通过多层解指针获取函数地址再调用。不过也有好处,它们的地址在一个表里,因此很好识别,如使用dumpvtable。
空间布局
类对象实例的空间布局不在C++标准里,因此不同编译器可以自己实现,但是一般会按照如下方式实现:
上图,Ex5继承了Ex2和Ex4,则先嵌入了Ex2,再嵌入了Ex4,之后才是自己定义的实例成员,而它定义的虚函数将覆盖基类的虚函数表或新加到第一个虚表之后,即上图偏移0处指向的是Ex2的虚表拷贝,偏移8是Ex4的虚表拷贝,若Ex5重写了基类的虚函数,则修改对应虚表即可,而新加的虚函数会被追加在偏移0处指向的虚表之后。
如果一个类没有非静态成员变量也没有虚函数,也没有继承这些,那么它也要占一字节空间,使this指针有所附着。
RTTI
运行时类型信息(Run Time Type Information)是逆向的大宝贝,用它可以获取很多有用的信息。C++是静态编译的语言,语言的符号只在这个阶段有用,之后在运行时不再使用这些符号,但是考虑这样一种情况,在一个函数的参数是基类的指针,于是所有派生类都可以作为参数传入,而在函数内部,它又需要根据实参的实际类型执行不同的操作,这里的操作中如果是调用基类的虚方法那就是多态,而如果是派生类特有的方法或者访问派生类特有的属性,则需要进行一种转换,将基类指针转换为派生类指针,这里粗暴的强制转换会让编译器很为难,C++是提供了一个函数,这个函数做的就是检查它的实际类型并返回新的指针类型,这就是typeid与dynamic_cast所做的事,如:
#include <iostream>
using namespace std;
class Base{
public:
virtual void vf1(){cout<< "call Base vf1()"<<endl;}
void f1(){cout<<"call Base f1()"<<endl;}
};
class Derived: public Base{
public:
virtual void vf1(){cout <<"call Derived vf1()"<<endl;}
virtual void vf2(){cout <<"call Derived vf2()"<<endl;}
void f1(){cout<<"call Derived f1()"<<endl;}
};
void func(Base* obj){
cout<<"the class is "<<typeid(*obj).name()<<endl; // 真实的类型:the class is 7Derived
obj->f1(); // 非多态:call Base f1()
obj->vf1(); // 多态:call Derived vf1()
if(typeid(*obj)== typeid(Derived)){
dynamic_cast<Derived*>(obj)->vf2(); // 派生类转换:call Derived vf2()
}
}
int main() {
Derived a;
a.f1(); // 正常:call Derived f1()
func(&a);
return 0;
}
要在运行时实现这些功能,就必须把类的一些信息保存起来,在运行时根据这些信息实现功能,保存起来的就是RTTI了,可以想到其实RTTI也不是一定要有的,也不是每个类都要有,这先不看,继续说RTTI的结构,它其实和语言实现有关,但大致相同,由如下结构体组成: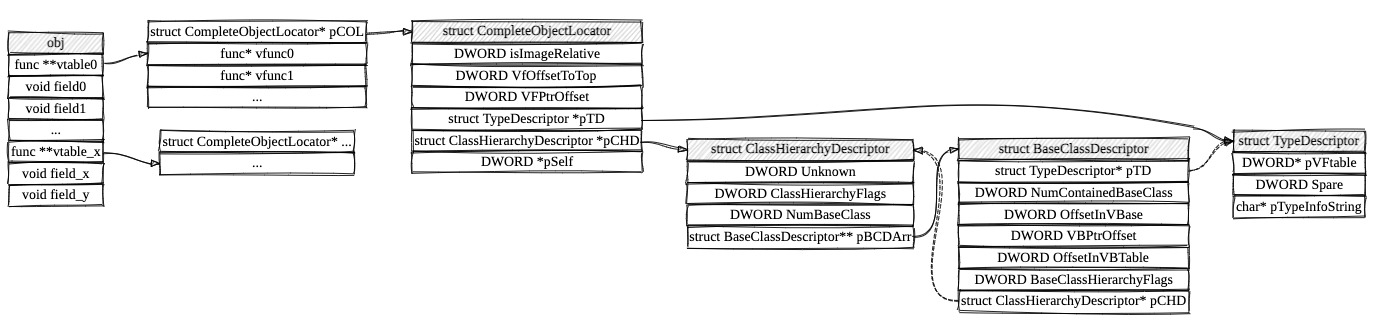
这堆结构体中只需要意识到两件事:它包含类名(struct TypeDescriptor::pTypeInfoString),它包含类继承关系(struct BassClassDescriptor)。C++使用Name Mangling来实现命名空间与方法重载,不同编译器会有特定的命名方法,因此根据这些命名特征就可以识别出类名,而由类名可以定位出以上整个结构,如虚表,类继承关系等。IDA本身就是使用这些信息识别虚函数表,并且还有些插件也利用了这些功能,如ClassInformer: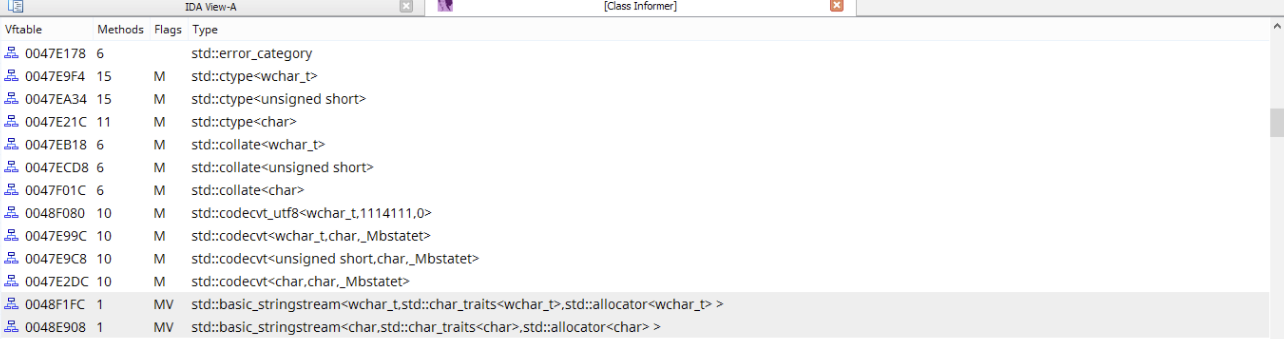
不过它不支持G++编译的,对此可使用IDA_GCC_RTTI,也是好几年没更新了,在7.5以上需要自己编译下,它的优点就是能很好的展示继承关系,如下面为某分析某产品时生成的图,可以清晰的看出类间继承关系: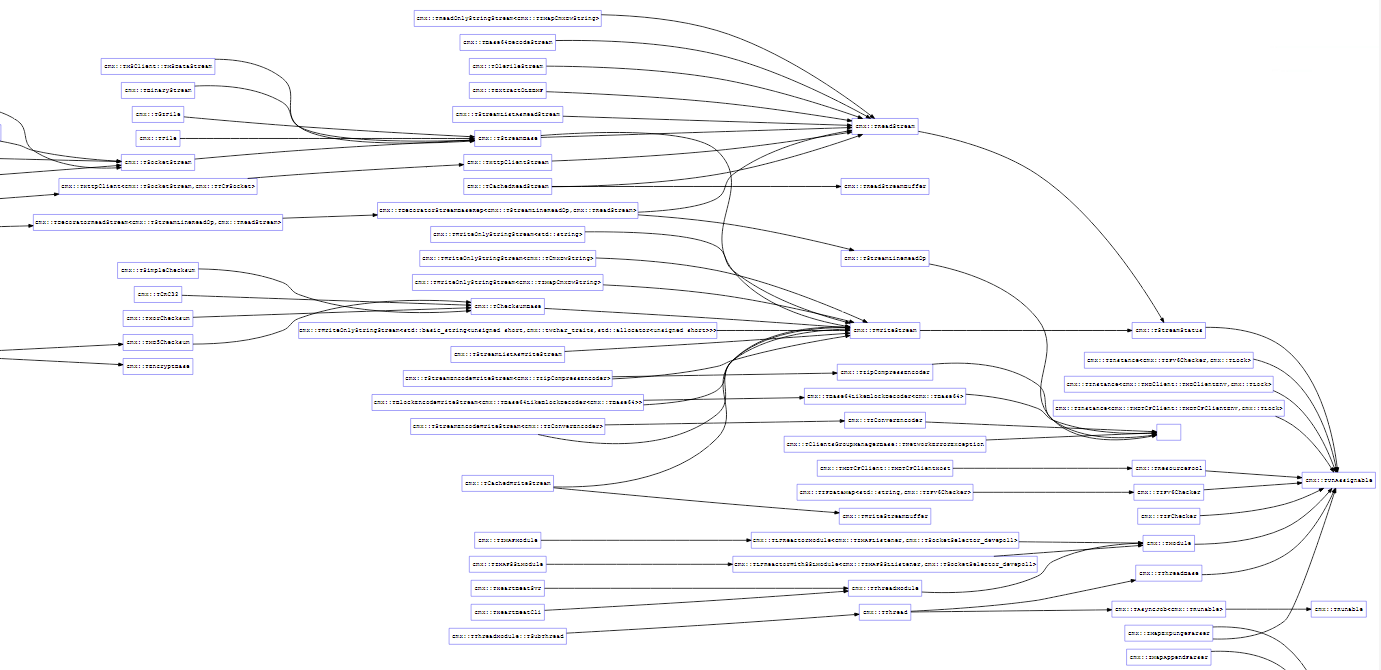
HexRaysCodeXplorer也可以用于部分重建类(结构体),它的思想和之前讲的结构体重建类似,它可以在类的构造函数处选择实例变量再按<R>键入新的结构体名称,如下:
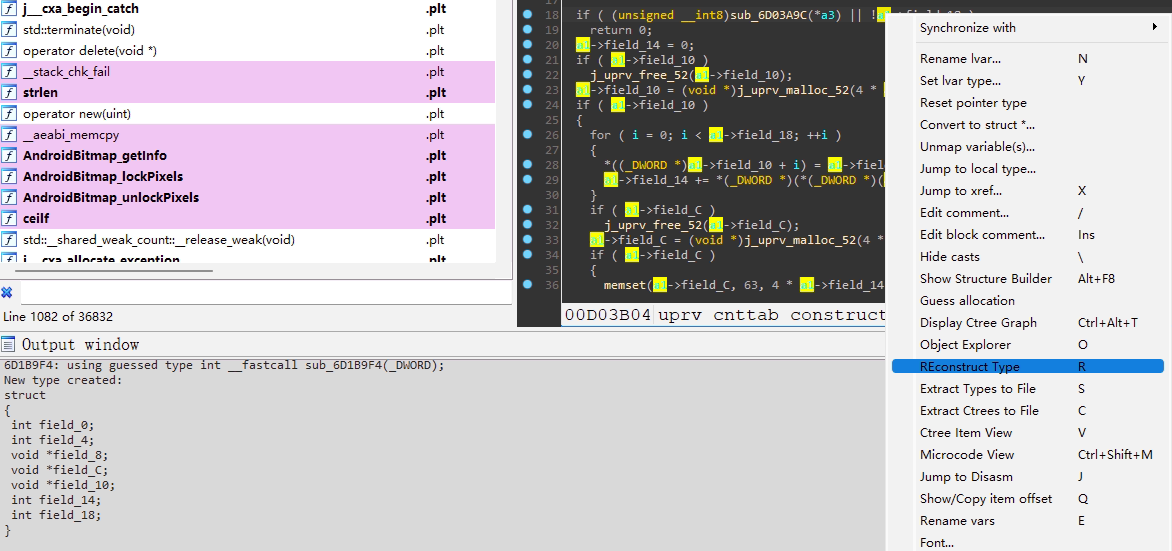
它还支持在虚函数表处按<V>新建虚表结构,两者配合就能获得较好的逆向体验。还有个HexRaysPyTools也挺好用的,可惜两年没更了。
STL
标准模板库特别复杂,还好不需要逆它,但是需要简单了解它里面的基本结构组成,以便能识别它们,例如遇到一堆红黑树操作时,可以判断出是否是STL的字典操作,而有的时候需要识别出string与vector,下面的例子中会遇到。
COM组件
和C++很相似的是COM组件,它主要为了解决二进制库的兼容调用,想想普通C的可以直接提供函数,再说明调用约定就能对外提供服务了,而C++就复杂多了,它有类,有new/delete,还有版本区别,由于只能导出函数或变量,因此只能通过工厂函数之类的功能对外提供类的创建,管理功能,COM组件就是为了实现这些功能的一种方案,它定义了接口描述语言IDL说明接口信息,用IDL可以生成其他语言所需的stub,接口可以忽略内部实现,并且它使用UUID(GUID)为每个实现命名(IID/CLSID),从而实现同名(不同版本)实现的IID不同,通过CLSID与IID就可以定位到特定版本的函数,它的全过程如下:
- 编写COM组件,它需要继承并实现
IUnkown接口 - 将COM组件注册到注册表,使用
regsvr32.exe可将它的CLSID与路径添加到注册表的特定位置 - 其他程序使用,使用
CoCreateInstance查询加载组件并获取接口的实例对象,或使用QueryInterface定位特定接口实例 - 调用实例对象的方法
- 销毁实例,释放COM组件
COM组件似乎是微软独家的,一般很少遇到,我只在某一年HVV中遇到过一次,某邮箱系统后端全是COM组件,那是个老程序员写的了...所以这里只简单记录下,它一般是CPP写的DLL,可先使用COMRaider扫一下获取函数等信息: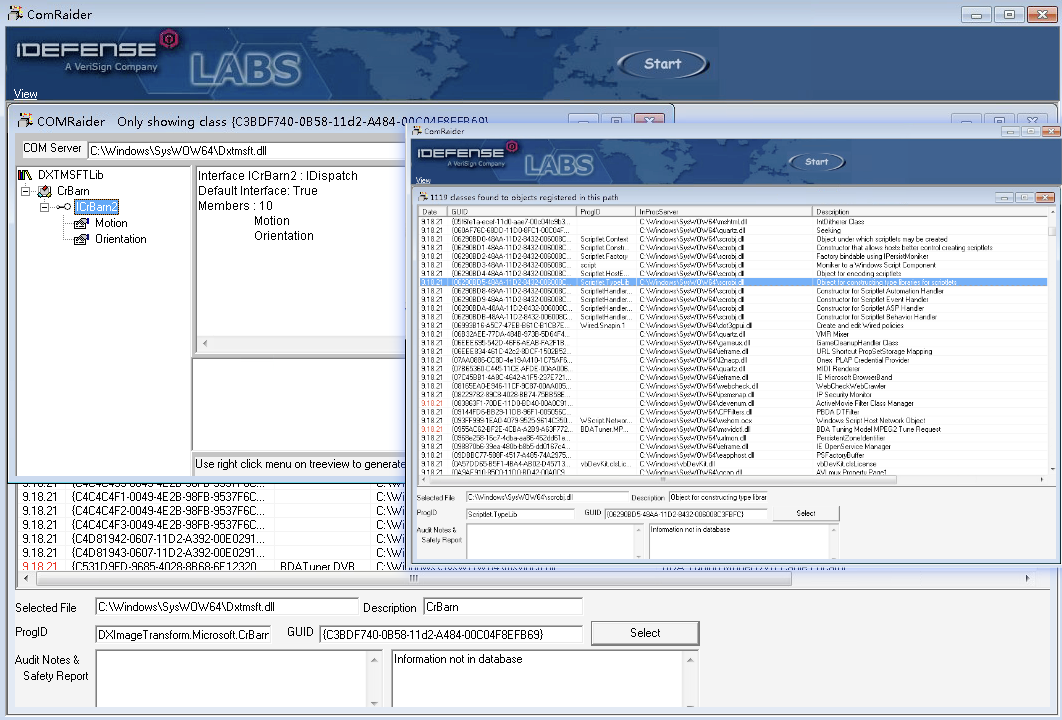
也可以用ClassInformer读虚表等,对于调试,可以直接写代码调用特定接口,例如:
#include "stdafx.h"
#include "..."
#include<iostream>
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
Interface * Ivar = NULL;
HRESULT hr = CoInitialize(NULL);
if(SUCCEEDED(hr))
{
hr = CoCreateInstance(CLSID,
NULL,
CLSCTX_INPROC_SERVER,
IID,
(void **)&Ivar);
if(SUCCEEDED(hr))
{
Ivar->Func(...);
Ivar->Release();
}
else
{
cout << "CoCreateInstance Failed." << endl;
}
}
CoUninitialize();
return 0;
}
之后可以去库里下断,也可以直接在OLEAUT32.dll的DispCallFunc上下断,它会最终调用到实际的函数。更多内容可见COM组件的逆向。
栗子🌰
当我发现时笔记的只有部分片段,环境啥的也都没了,我讨厌做重复的事情,所以就不再搭环境了,下面主要讲讲分析技巧。
这个程序是C++写的,并且使用了静态链接加去符号,对后者一般都是上flirt等工具识别了,但是这个也可以硬啃,因为分析的是授权部分,了解授权逻辑就可以用连蒙带猜大法,授权证书有多种形式,如单注册码或带授权信息的证书,以后者为例,一个典型的证书生成过程如下:
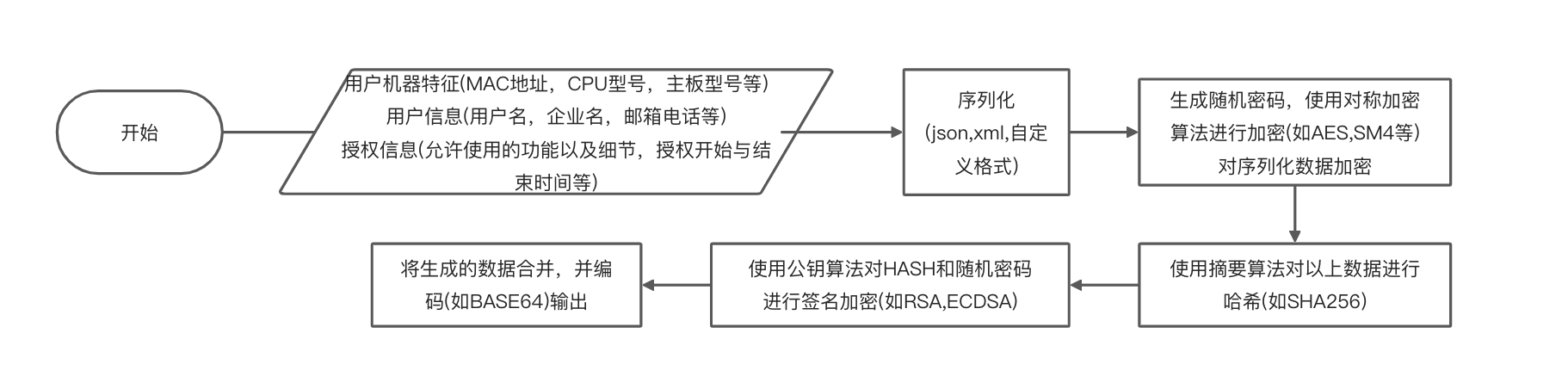
对此我们要做两件事:
- 输入的证书怎样的格式,它被哪些算法处理过,如签名加密等。
- 解析后的证书里需要包含哪些内容,如有哪些授权信息,格式是怎样的。
对于后者一般需要分析怎么使用证书,本文主要分析第一步。这个例子中该程序安装完成后无有效证书无法使用正常功能,存在的仅证书上传页面,因此跟踪它的流程定位到证书解析关键点,在关键点里发现了一些操作很像密码学操作,在授权中密码学操作常见如下4类:
- 编解码:编解码插件的就那么几种,特征特别明显,如Base64解码存在4变3,这些可参考CTF的杂项题。
- 摘要:摘要是把任意长度转换为固定长度,如128位,256位,它们一般会有一张常数表。
- 非对称密码:非对称密码都是用的数学的难题,如大整数分解,椭圆曲线离散对数,特征就是各种大数运算。
- 对称密码:这里的对称密码也包含序列密码,它们为了雪崩要扩散和混淆,因此会有很多循环,异或的特征。
因此根据这些特征可识别出很多算法,另外还可以根据程序的风格确定它的算法,比如古老的程序会用arc4,twofish,rsa这些算法,而新的喜欢用aes,sm4(国内),ecc这些,在识别时多注意常数,比如看到如下常数,可以搜索得知为FNV算法: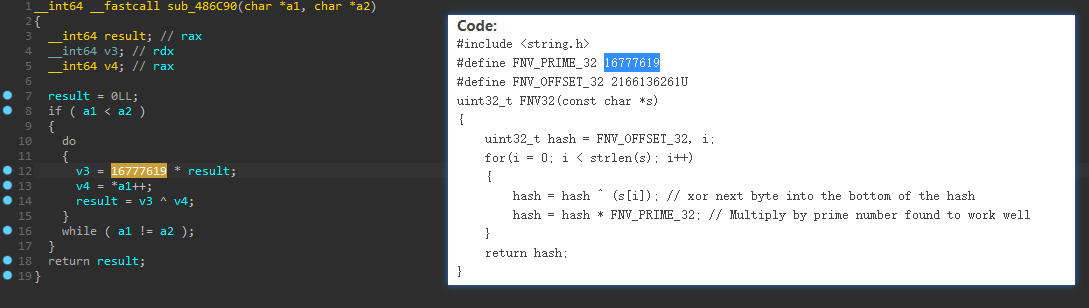
另外的就是C++逆向的技巧了,如如何识别类,虚函数调用等,对于一些类,看名字不熟悉时,可以搜索看有没有类似的实现,如
分析发现有个叫BinaryStream的类,可以网上看看它可能是怎么实现的,有利于猜测函数调用的功能...现在进入正题:
1.通过调试,发现上传的证书字符串在sub_5BE6B0内被解析,任意输入的数据将会报证书相关异常,分析该函数
到熟悉的字符串,猜测是base64解码:
输入base64编码后的字符串,继续调试发现数据被解密,继续分析它会判断数据长度是否大于64字节:
2.若满足条件会讲解码后的数据传入如下函数,它的参数4为常数,参数5为一个数组首地址:
跟入函数内,发现它先进一个函数做一些运算,接着判断返回值,分析运算发现是大数运算,而且存在65537这个典型的常数,那么先猜测此处使用了RSA签名,若如此则后面的判断很可能是 pkcs1的校验,传入的数组为RSA的公钥,判断长度为64*8=rsa512,此处可见使用了弱算法: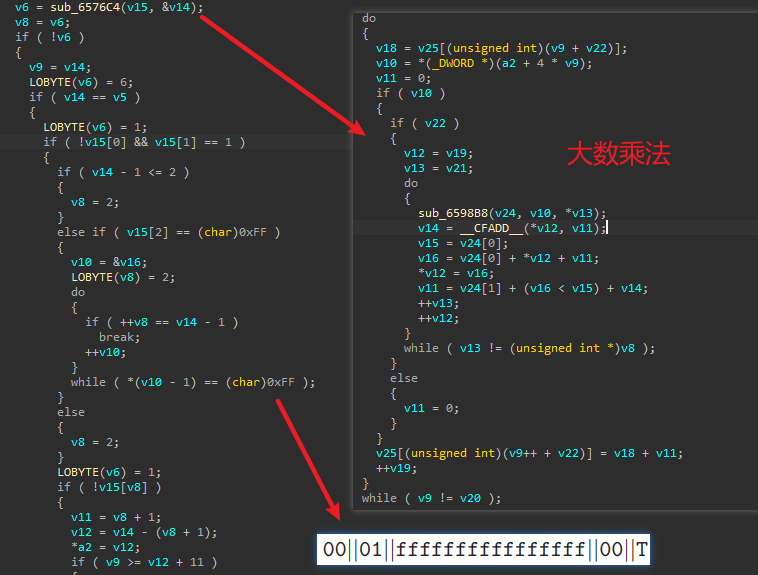
那么,可以dump出输入,输出与公钥,使用python验算发现结果与猜测一致。
import gmpy2
RSA_SK = '''-----BEGIN RSA PRIVATE KEY-----
MIIBOgIBAAJBAPEKGpuWnpXu+bfWMM2LpXpZR/R5DhXbCSJBWNLgOlOqCzNws/lj
VE/oOdtsULWuQSmhn4tzXsLZETsRoH73HUMCAwEAAQJAQmiOPB+bQaO9mTCh8X9v
7+15LZnMj6jxM0bdufudFj9SOlO/XRzdgx4Z/uK5D1JrtlSGcgs5OmgrGF+SFtAq
AQIhAP7V1mPs/HckwQpMIAdAOVV15PYnv3IAVlWKhYm8LrljAiEA8iQgBES2ypEv
Kpydf/y5KNPVNQkqhVmSpeeFP53jQqECIBVv1ZYYVHCNVfPQzYzumSQYQ8d1NoSX
hKuzeGJKwz9zAiBmXqV2iIJrE4RIVJw1rues/hnGaVCjveHE6COqaJra4QIhALbC
Mwv9nvECYbAM1Gm05eC1p7pARhcfUiK5vWQ9fqv8
-----END RSA PRIVATE KEY-----'''
# openssl genrsa 512
PKCS_MAGIC = bytes.fromhex('0001FFFF FFFFFFFF FFFFFFFF FFFFFFFF FFFFFFFF FFFFFFFF FFFFFFFF FFFFFF00')
def bignum_to_bytes(num: int, pad: int = 0) -> bytes:
"""将大数按大端序转换为字节序列"""
hexstr = hex(num)[2:]
hexstr = '0' + hexstr if len(hexstr) % 2 else hexstr
hex_arr = [int(hexstr[i: i + 2], 16) for i in range(0, len(hexstr), 2)]
hex_arr.reverse()
if pad and len(hex_arr) != pad:
hex_arr.extend([0] * (pad - len(hex_arr)))
hex_arr.reverse()
return bytes(hex_arr)
def bytes_to_bignum(data: bytes) -> int:
"""解析大端序存储的大数"""
data_arr = list(map(lambda b: f"{b:02X}", data))
return int(''.join(data_arr), 16)
def rsa512_pkcs_v1_5_encrypt(d: int, N: int, data: bytes) -> int:
"""精简版的加密"""
assert len(data) == 32
M = PKCS_MAGIC + data
M = bytes_to_bignum(M)
return int(gmpy2.powmod(M, d, N))
def rsa512_pkcs_v1_5_decrypt(e: int, N: int, data: bytes) -> bytes:
assert len(data) == 64
C = bytes_to_bignum(data)
M = gmpy2.powmod(C, e, N)
M = bignum_to_bytes(M, 64)
assert M[0:32] == PKCS_MAGIC and len(M) == 64
M = M[32:]
print(bytelist_to_hexstr(M))
return M
3.继续分析sub_600110的内容发现为一个初始化函数,根据常数猜测为md5初始化,那么此处为哈希校验: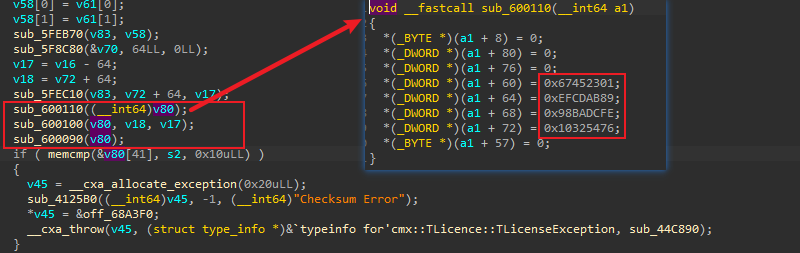
4.继续分析发现做的运算有很多位运算,以及一些轮循环,可以说很像对称加密了(虽然没有找到它的加密盒),而且这里面还有个可疑常数65537,另外之前遇到rsa512这种弱加密了,因此可以怀疑这里使用了一种比较旧的对称加密,搜索发现idea算法完美符合这些特征: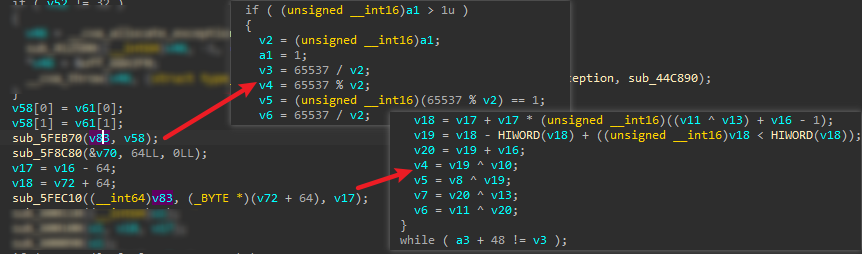
于是用同样的方式可以验证猜测无误。
import ideacipher
BLOCK_SIZE = 8
def idea_decrypt(key: bytes, ciphertext: bytes) -> bytes:
plaintext = b''
for i in range(0, len(ciphertext), BLOCK_SIZE):
block = ciphertext[i:i + BLOCK_SIZE]
if len(block) == BLOCK_SIZE:
plaintext += bytes(ideacipher.decrypt(block, key))
else:
for b in block:
plaintext += struct.pack('<B', (b ^ 0xc5) & 0xff)
return plaintext
def idea_encrypt(key: bytes, plaintext: bytes) -> bytes:
cipher = b''
for i in range(0, len(plaintext), BLOCK_SIZE):
block = plaintext[i:i + BLOCK_SIZE]
if len(block) == BLOCK_SIZE:
cipher += bytes(ideacipher.encrypt(block, key))
else:
for b in block:
cipher += struct.pack('<B', (b ^ 0xc5) & 0xff)
return cipher
5.之后对解密后的数据进行了解析,通过分析得出它将一种类似json的格式解析为c++里的map,因此需要先分析它的自定义格式,如下为处理过的伪代码,在进行一些头部校验后,它会按字节读取,根据类型进入不同的分支进行处理,反序列化为相应的对象: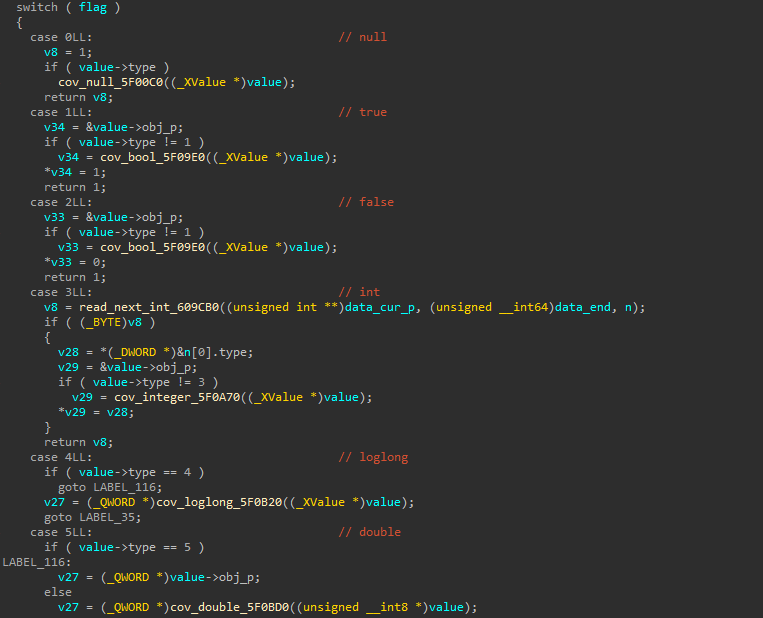
此处只需要逐个分析即可获得它自定义的序列化协议。
def pack_str(s: str) -> bytes:
"""将字符串打包"""
num = len(s)
assert num < 0xffffffff
if num < 0xff:
return struct.pack('<B', num) + s.encode()
else:
return b'\xff' + struct.pack('>I', num) + s.encode()
def seralize_node(node) -> bytes:
out = b''
if isinstance(node, dict):
out += b'\x0c'
out += struct.pack('<B', len(node))
for k, v in node.items():
out += pack_str(k)
out += seralize_node(v)
elif isinstance(node, (list, tuple)):
for v in node:
out += seralize_node(v)
elif isinstance(node, str):
out += b'\x06'
out += pack_str(node)
elif isinstance(node, int):
out += b'\x03'
out += struct.pack('>I', node)
elif isinstance(node, DateTime):
out += b'\x0a'
out += node.seralize()
elif isinstance(node, bool):
if node:
out += b'\x01'
else:
out += b'\x02'
else:
raise NotImplemented('S')
return out
def seralize2(json_data):
data = struct.pack('>IHH', 0xffffffff, 0x01, 0x02) + seralize_node(json_data) # flag + type + version
return data
6.最后,需要分析它要返回的字典应该包含哪些内容,这就要反过来追踪哪些函数会使用此处返回的数据了,最终可得到如下格式,分析完成,可以写注册机了,首先生成合法的RSA参数,生成公钥并替换原始文件:
sed -bi 's/...(原始公钥).../\xF1\x0A\x1A...'
之后写证书生成代码如下:
def gen_lic(json_data):
# 序列化数据
data = struct.pack('>I', 0xffffffff) + seralize2(json_data)
print('证书内容:', data)
# 计算MD5
checksum = md5()
checksum.update(data)
checksum = checksum.hexdigest()
print('校验和:', checksum)
checksum = hexstr_to_bytelist(checksum)
# 对称加密
idea_key = '000100020c024544000100020c024544'
idea_key = hexstr_to_bytelist(idea_key)
data = idea_encrypt(idea_key, data)
print('密文:', bytelist_to_hexstr(data).replace(' ', ''))
# 非对称加密
rsa_plaintext = idea_key + checksum
RSA_KEYPAIR = RSA.importKey(RSA_SK)
N = RSA_KEYPAIR.n
e = RSA_KEYPAIR.e
d = RSA_KEYPAIR.d
rsa_cipher = rsa512_pkcs_v1_5_encrypt(d, N, rsa_plaintext)
print('RSA N: ', bytelist_to_hexstr(bignum_to_bytes(N, 64)))
print('RSA e: ', bytelist_to_hexstr(bignum_to_bytes(e, 32)))
print('RSA d: ', bytelist_to_hexstr(bignum_to_bytes(d, 32)))
data = bignum_to_bytes(rsa_cipher, 64) + data
# base64编码
data = base64.b64encode(data)
print('证书: ', data.decode())
print('编码后证书: ', quote_from_bytes(data, safe=''))
至于这个过程中的C++技巧,就上面描述的辣些,比如识别构造函数来识别类: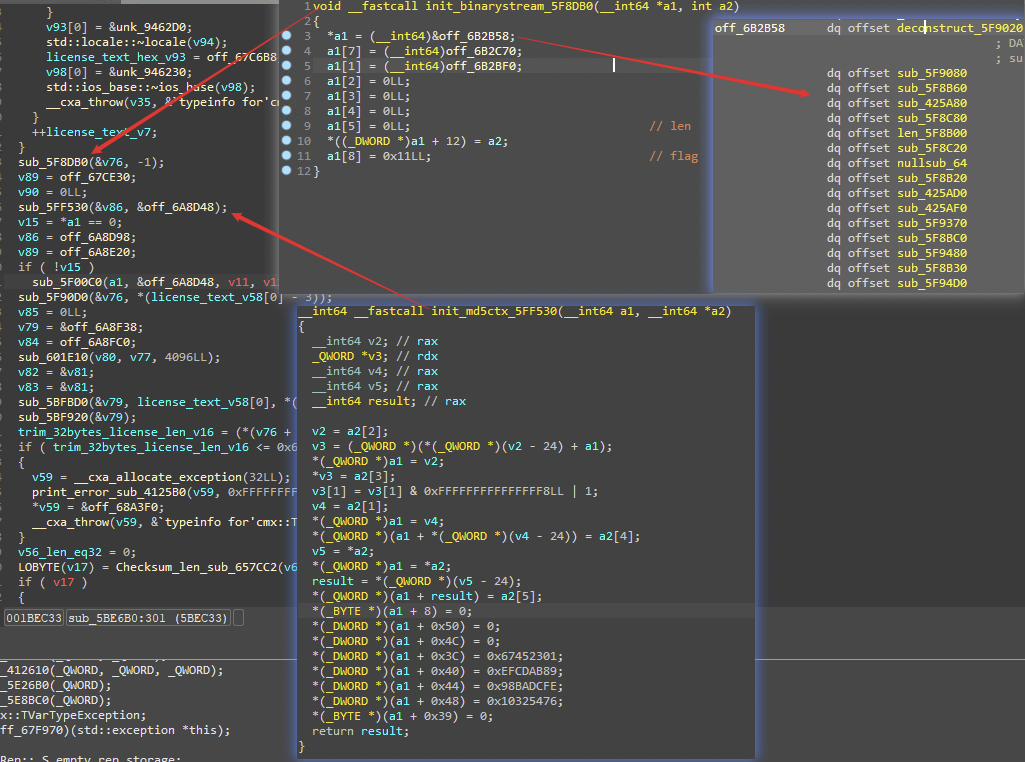
其他的就不截图了。
注:之前讲过伪代码有红色变量(错误)可能是函数prologue是非标准形式,本次分析发现了另一种错误--参数识别不准确,在函数内未直接使用的都是多余的参数,为了分析方便可将其删除。
参考
- 《C++反汇编与逆向分析技术揭秘》-钱林松,赵海旭著
- 《Reversing C++》-Paul Vincent Sabanal,Mark Vincent Yason